I have just gone through Part 1 of this course and in efforts to solidify the great information in the course, I decided to experiment with vision_learner using the Fruits 360 dataset on Kaggle (Fruits 360 | Kaggle)
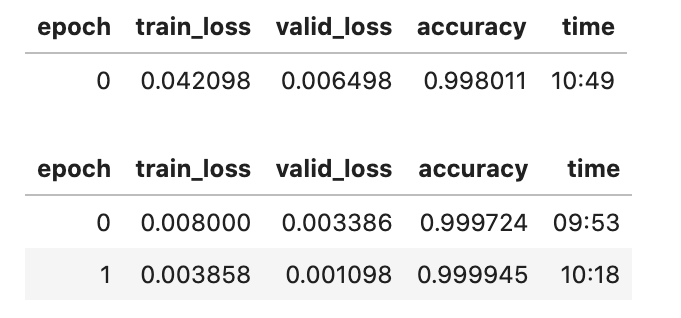
I’ve followed the steps written out in the documentation to create a very basic version of vision_learner and it has great results
But I have some questions as to how I can predict with this model
When I grab a batch from the dataloader and try to do predictions on the training set, every prediction on the training sample returns the same predicted category while the corresponding y label is clearly changing
Yet the error rate is negligible and when I run learner.show_results(), the model seems to be predicting each image into the correct class perfectly. What am I missing here or am doing wrong while using learner.predict?
I wanted to have a validation set as well as training set for this model, so I made my dataloaders like so
Reading fast.ai and other machine learning books, I’d gotten the impression that we need to create both validation (for finding best hyperparameters) and test sets (for final testing). Would this be a correct assumption?
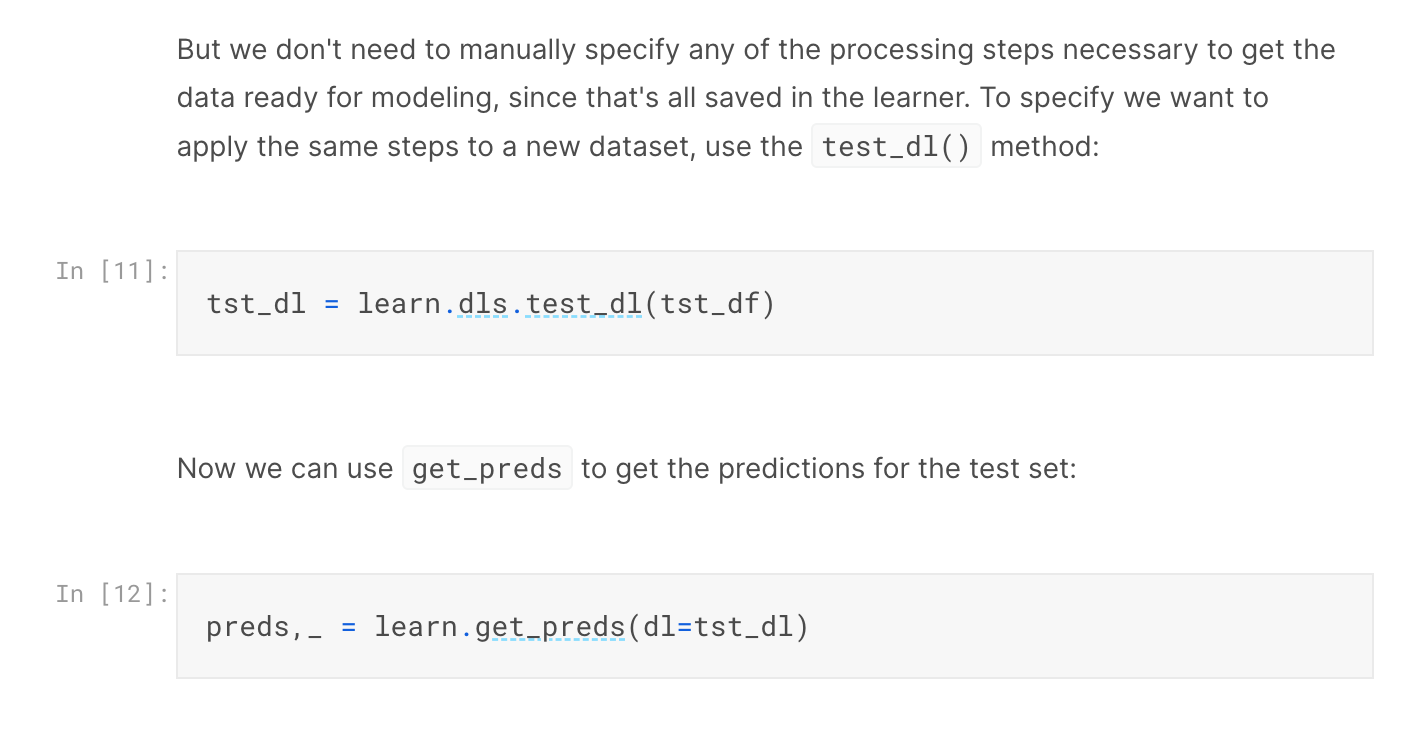
Yes, that’s absolutely correct. Your original approach of splitting the 'Training' set into training and validation sets, and then using the 'Testing' set at the end would be the desired approach from my understanding. This page of the docs and this example notebook (near the bottom) show how to prepare a test set so that fastai applies the same transforms to it as it did the training and validation data. I’m unfortunately not as familiar with this yet so can’t provide my own examples.
For your first question—can you share a Kaggle or Colab notebook with your training so I can try and reproduce the steps and see why it’s not predicting correctly?
I ran the notebook and get the same issues as you. I also re-trained the model and it doesn’t predict training set images correctly.
I also trained a resnet18 (just to see what would happen) and ran into the same issues there as well—show_results shows all correctly predicted images, but learner.predict does not predict it correctly. I’ve made a copy of your notebook here with my code.
FYI—I wasn’t able to load your model, it gave me the following error:
Not sure what the solution is, assuming some kind of sharing setting?
Let me know when you find the resolution to the prediction issue, I’m curious to see what I’m not understanding. I’ll keep poking at a bit later today.
@torchify I think I figured out what we are doing wrong. learn.predict is expecting a regular image (not a tensor). For reference, see the bottom of this blog post by Zachary Mueller where he gives learn.predict a filepath to an image: