Hey all, I think I’ve found an odd bug in fastai where my RAM runs out of memory during eval mode for image to image models (ex. autoencoders).
Here’s the code to reproduce the error:
from fastai.vision.all import *
from fastai.data.external import untar_data, URLs
path = untar_data(URLs.MNIST)
dblock = DataBlock(
blocks=(ImageBlock(PILImageBW), ImageBlock(PILImageBW)),
get_items=get_image_files,
# load the image:
get_y=lambda x: x,
item_tfms=Resize(28),
splitter=RandomSplitter(valid_pct=0.9, seed=42),
batch_tfms=aug_transforms(do_flip=False, pad_mode=PadMode.Zeros),
)
dls = dblock.dataloaders(path / "training", bs=64)
x, y = dls.one_batch()
print(x.shape, y.shape)
# create a simple autoencoder for mnist (28, 28)
class AutoEncoder(Module):
def __init__(self):
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, 3, padding=1), # b, 16, 28, 28
nn.ReLU(),
nn.MaxPool2d(2, 2), # b, 16, 14, 14
nn.Conv2d(16, 8, 3, padding=1), # b, 8, 14, 14
nn.ReLU(),
nn.MaxPool2d(2, 2), # b, 8, 7, 7
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(8, 16, 2, stride=2), # b, 16, 14, 14
nn.ReLU(),
nn.ConvTranspose2d(16, 8, 2, stride=2), # b, 8, 28, 28
nn.ReLU(),
nn.Conv2d(8, 1, 3, padding=1), # b, 1, 28, 28
nn.Sigmoid(),
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
model = AutoEncoder()
learner = Learner(
dls,
model,
loss_func=F.mse_loss,
metrics=rmse,
)
learner.fit_one_cycle(1, 1e-4)
As you can see, there’s nothing special about the code. I’ve put 90% of the data in val set to highlight the error.
When you look at your task manager (run it, it takes 30 seconds to run) you can see it goes up a bit for training. For eval mode it climbs steadily, then at the very end spikes. Then it drops back down:
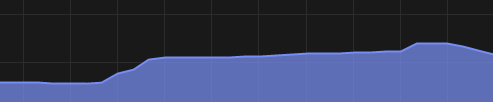
^--------------------------^-----------------------^----------------------------^
1 = normal
2 = training starts
3 = eval time (it’s a steady slope up)
4 = end of eval time
The bumps here are small, but when training on a larger dataset (ex. CelebA) it ends up killing your script because the RAM runs out of memory (there’s no error message, just “Killled” and then the pid)
I’ve done a few experiments to isolate it:
- Normal MNIST Classification → You get 1 and 2, but during eval 3 and 4 don’t occur. As in it doesn’t increase in memory nor spike at the end of evaluation
- Pure pytorch (no fastai) autoencoder → Same as above, it doesn’t increase during eval
I’m using a conda environment with pytorch & Fastai (I limited all other packages to try and isolate the error)
If anyone else could reproduce the error and/or help me figure out what’s going on it’d be awesome! I’ve been stuck on this problem for a while ![]()