I am looking at these pictures
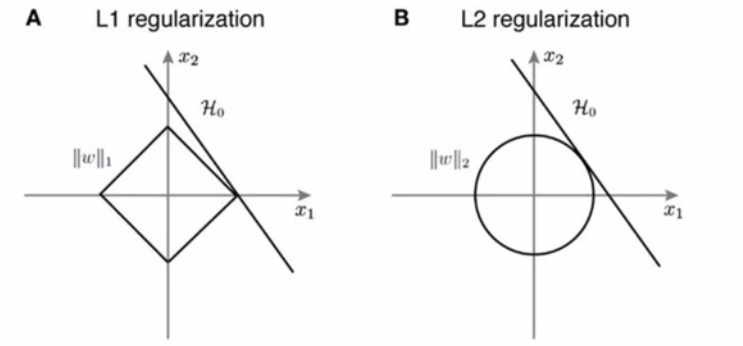
I understand that the square and circle came from the equations of the norms. But what does the diagonal on those shapes represent and why is that important for sparsity?
I am looking at these pictures
I understand that the square and circle came from the equations of the norms. But what does the diagonal on those shapes represent and why is that important for sparsity?
You haven’t provided a link to the original text so this is a conjecture, but I assume the line represents a set of “equally good” points in the (x1,x2) space in terms of the unregularized objective function, while the square/circle represents the regularization constraints (NB: depending on the model you are fitting, instead of a line you might have an ellipsis, or another convex object).
Now, as for why this matters in terms of sparsity: look at the L1 regularization case. For almost any orientation of the line, the point of contact with the square will be a point lying exactly on one of the axes => sparse solution. In the L2 case, on the other hand, you are pretty much guaranteed to get a dense solution.
The text is the jupyter notebook which Rachael shows in Video 4. So the area inside the square/circle is where we don’t want to be as per the constraints?
I would say it’s where you have to be as per constraints  But I haven’t seen the lesson, could you provide a link?
But I haven’t seen the lesson, could you provide a link?
Thanks for the link! So, the rectangle/circle represents an equally good set of points w.r.t. to the regularizer, and the line shows an equally good set of points w.r.t. the original function that you are trying to optimize. The optimum of the regularized function can be represented as the (typically single-point) intersection.
The questions is why would it be a point lying exactly on the axes? The square has sides too. So why can a solution not be on the sides of the square? Why are we guaranteed to get a dense solution? What does a “dense solution” even mean? Dense as in sparse/dense matrix?
Write down the coordinates of a point that lies on an axis. How many zero elements does it have in the 2-dimensional case? In the 100-dimensional case? This exercise should give you an idea what sparsity means.
You can think of it this way. When optimizing, you are looking for an intersection between square/circle and line. You “pay” to grow the circle/square (regularization term) and you “pay” to move the line closer to the origin (other term).
So you say “the square has sides too”, which is correct. But imagine for a minute that you are looking for good weights by hand, trying out different values. And say that with the weights that you are currently considering, the line is cutting the square somewhere in its side. Can you think of strictly better (“cheaper”) weights?
That sounds more like independent vectors. In what sense is this “sparse”? How important is this digression that “L1 norm induces sparsity”?
I get the part where we pay to grow the circle/square because the regularization term needs to be decreased usually to minimize the loss metric. Why do you say we need to “pay” to move the line closer to origin?