I didn’t find any discussion on VGG’s history, strength and limitations, so I thought I’d start one in the hope that folks with more experience can share more insights.
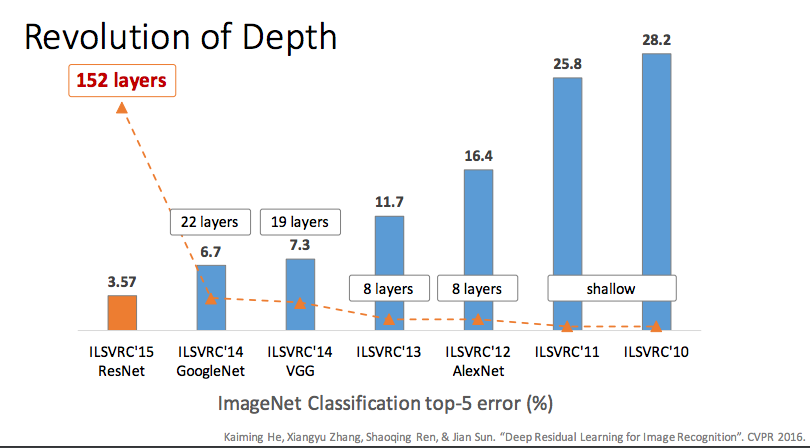
First of all, I am astonished by how influential VGG is, their original paper published in april 2015 has been cited 3177, that’s on average 3+ papers per day citing this paper in the last 2 years!! This metadata seem to be indicate that increased depth in network configurations is shaping how people think about deep learning and building deep learning models. If that is the case, can we say the deeper the better? If not, is there such a thing as optimal depth? Why stop at 19 (as in the original paper)? What are other big ideas in deep learning in addition to going “very deep”?
Second part of my question is about VGG’s application in practice, when does it work really well, when does it not work so well? Since most folks here probably tested it on their own datasets, I am curious if people care to share their own experience.
Finally, just to get some context in training time expectations. In their submission to 2014 imagenet, Simonyan and Zisserman explained “Our implementation is derived from the Caffe toolbox, but contains a number of significant modifications, including parallel training on multiple GPUs installed in a single system. Training a single ConvNet on 4 NVIDIA Titan GPUs took from 2 to 3 weeks (depending on the ConvNet configuration).” I for one am very grateful to Jeremy’s guidance on starting with sample data.
You can find the original paper here
Imagenet2014 [results] (http://image-net.org/challenges/LSVRC/2014/results)