Hi,
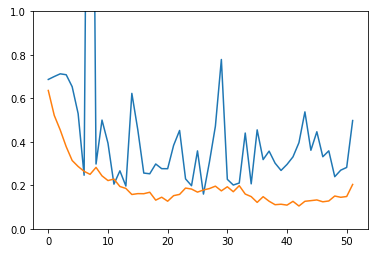
I’m training a dense CNN model and noticed that If I pick too high of a learning rate I get better validation results (as picked up by model checkpoint) than If I pick a lower learning rate. The problem is that high learning rate gives wild fluctuations in validation loss, while training with low learning rates provides for a smooth and pleasing to an eye learning curve which never goes as low though.
My train set is around 900 images and test set is close to 100. I do augmentation on the training set. Results from the model trained with high LR are quite decent and I get nice leaderboard scores at Kaggle but these learning curves make me feel uneasy. Am I terribly overfitting and getting these low loss values by chance?
I use cyclical_clr to set LR for Adam optimizer from 1e-3 to 1e-6.
Model trained with somewhat optimal LR give me log_loss of around 0.21, while 1e-3 to 1e-6 give around 0.17
Should I be worried?!
I don’t think your picture got uploaded correctly (I can’t see it anyway).
A low loss does not necessarily mean high accuracy. As far as the loss is concerned, it should go down over time. If one method of training gives you a lower loss than another method, that only tells you the loss is lower – it doesn’t necessarily say anything about the accuracy being better too.
But what counts is that the accuracy gets higher or not. If a method of training gives a higher accuracy on your validation set, then choose that method.
Accuracy is just one side of a medal. I’m optimizing for log_loss, which penalizes high confidence on wrong predictions. But accuracy moves along with the loss in this case. But moves are not as dramatic.
Piets
So, how do I live with that? Should I worry? Or just ignore the learning curve and go for low loss values through early stopping+model checkpoint?
Good observations @SakvaUA
It is normal that you get higher loss/accuracy variability with higher learning rate since the weights are just updated with higher amplitude. If your data has high variance and you have relatively low number of cases in your validation set, you can observe even higher loss/accuracy variability per epoch.
To proove this, we could compute a confidence interval (or the bayes factor) for the loss or accuracy value for each epoch with a bootstrap algorithm on the validation dataset. This way we could confirm the statistical variance of the validation result depending on the data variance and the number of cases.
That is also part of the reasons why a weighted ensemble of different performing epoch models will usually perform better than the best performing model on your validation dataset. Sometimes choosing the best model or the best ensemble to generalize well isn’t as easy as selecting the lower loss/higher accuracy model.
I hope this helps to explain your observations.
Well, I actually save all models (one per epoch) and average three best ones (with harmonic mean, which works better than simple average or geometric mean for some opaque reason) and indeed it gives better results.
It could also be that your model’s capacity is too big for your problem. In this way a small change in the high-dimension parameter space could cause the model work very well/ very bad on your test set. You can try to make a model with less parameters to train.
This is the key:
Accuracy is a value in range [0,1]
The range of loss depends. For cross-entropy it is [0, INF+)
Therefore it does not make sense to plot accuracy and loss on the same graph.
We generally have two plots. Loss plot (has cv_loss and train_loss) and Accuracy plot (has cv_accuracy and train_accuracy)
To rephrase: since, loss and accuracy are functions dependent on the distance between hypothesis and ground-truth, they are bound to have similar trends but, since their ranges are different, spikes will be of different heights.
In general, accuracy plots will appear subdued when compared to loss_plots
Hi, I am a total DL noob and trying to learn. I have a very similar issue; my validation loss is very volatile. But it looks like it is improving. So I am considering the following options:
Decrease learning rate and retrain
Put some momentum to get a smoother graph
Ignore volatility; train more epochs as long as it is improving
What would you suggest? btw my validation set is not small(have 10K images for validation and 500K for training).
Hey @kazanture, I’m also working in DL for the first time and am facing a very similar problem.
You said increasing the batch size helps but the GPU I use (Kaggle Notebooks) crashes when I keep anything above 16. They have 16GB VRAM too, how do you keep such a large batch size?
@tapankarnik
First of all I am a DL noob so what I have applied might not solve your problem BUT;
after experimenting/experiencing more;
I realized volatility is not such a big problem as long as the loss is getting better after some training.
decreasing the learning rate helped with volatility
in my case increasing the batch size helped with volatility.
I had the same memory problem when I try very big batch sizes; in my case what I did is I did not train all layers at once. I used transfer learning and froze most of the layers so when I am training less layers at once; I was able to use larger batch sizes.