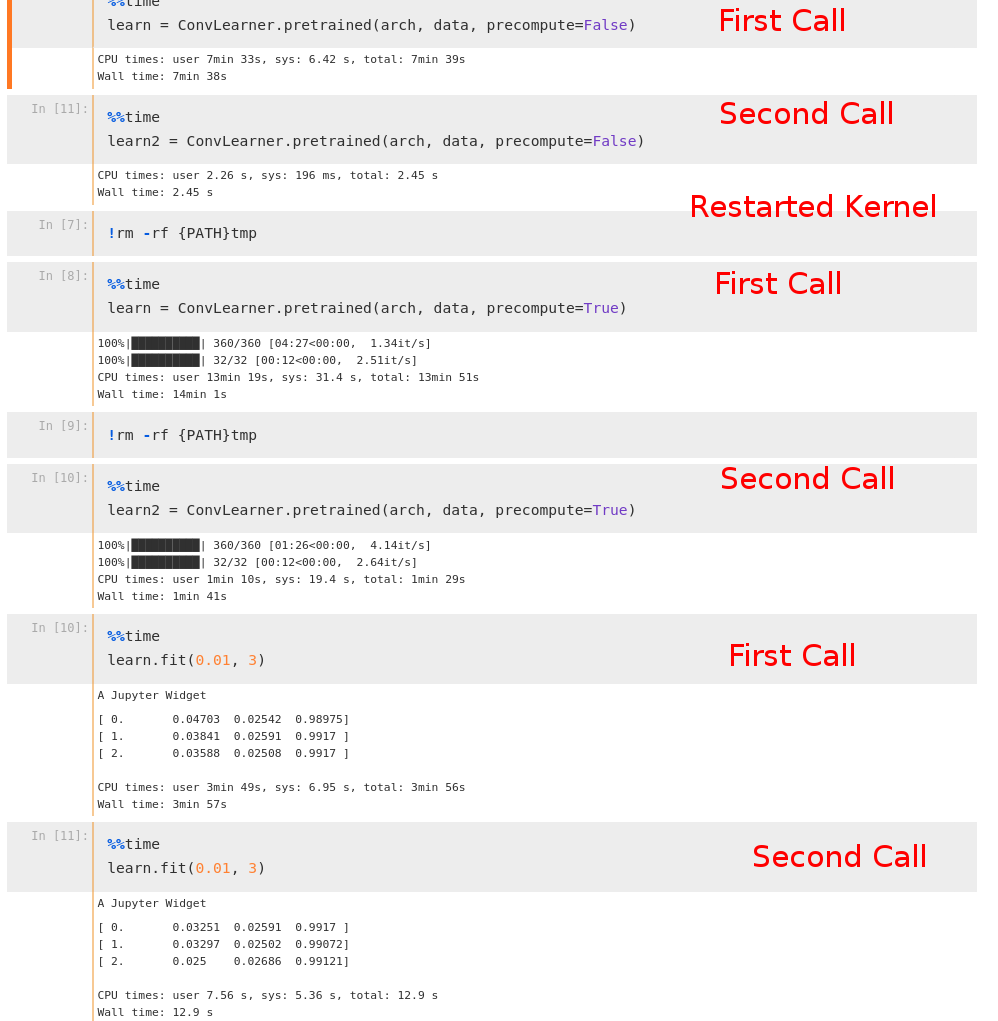
My problem is similar to this topic, but since that issue had been fixed I decided to create another topic.
First of all, I followed all sugestions on that topic, but none helped my case, I’m running the code of lesson 1, using my personal machine, Ubuntu 16.04, CUDA Version 8.0.61, cuDNN v6.0.
Here is the thing, the first time I call ConvLearner.pretrained it takes a long loooong time (no matter if precompute is set to True or False), then if I instantiate the model again it takes normal time. The same is true for the fit function.
I took a screenshot illustrating the problem and a screenshot of the stack if I interrupt the kernel while loading the model.
Ah let me put some timing, I have to add in bs param else I will get runtime exception queue.Full
Let me share out the timing with you once I run mine.
Wow this is an odd problem. It’s nothing to do with the previous thread you linked to - your issue is that actually creating the model is very slow. It’s not connected to anything in the fastai lib. You can check by calling the pytorch function directly:
m = resnet34(True)
You’ll find this takes a long time, based on what you’ve shown in your post. The best place to ask about that is on https://discuss.pytorch.org/ , since it’s a pytorch issue.
I’ve spent the hole day trying to fix this, while using docker like described here seemed to fix the problem, using conda env create -f environment.yml caused the problem once again.
If you are using Docker / nvidia-docker, try using --ipc=host in your docker run command as specified here - https://github.com/pytorch/pytorch#docker-image, otherwise Docker instance may not have access to all the memory.
@jeremy you were right, messing with docker was a waste of time. I created a new virtual env and installed each package manually when requested by some fastai import (on lesson1), the problem seem to be gone, maybe some package installed by conda env create -f environment.yml enters in conflict with torch?