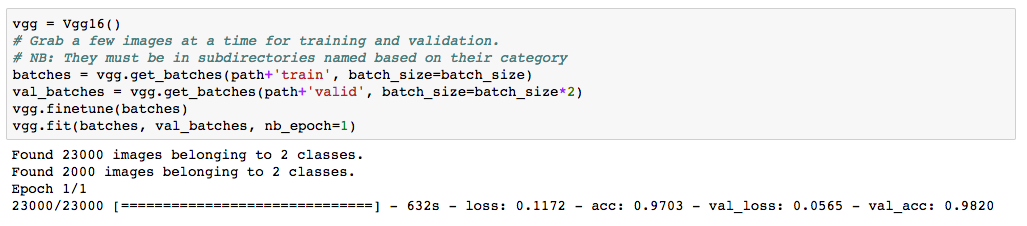
So we mentioned that a typical reason for validation accuracy being lower than training accuracy was overfitting. I also assume that when the opposite is true it’s because my model is underfitting the data.
My question is in a few parts
Is my assumption above true? Val. Acc > Train Acc. implies Underfitting?
What are the key techniques to avoiding underfitting, besides training more and reducing dropout?
How do I choose the model I want to run on my test data? Can I just pick the output with the highest validation accuracy?
EDIT: For example, the output from two different epochs on Redux:
Epoch 2: loss: 0.4074 - acc: 0.9744 - val_loss: 0.2066 - val_acc: 0.9868
Epoch 3: loss: 0.3865 - acc: 0.9757 - val_loss: 0.3739 - val_acc: 0.9768
Yes your assumption is true - although if you’re underfitting due to reasons other than dropout (or other regularization techniques), you won’t see this.
The key technique to avoiding underfitting is using a model with plenty of layers and parameters, and picking an appropriate architecture (e.g. CNN with batchnorm for images). Also picking appropriate learning rates.
Picking the output with the highest validation accuracy is generally a good approach.
Regarding determining if you are overfitting – it seems like a good guideline that @js4393 mentions (and Jeremy mention multiple times in Lesson 3) – if validation accuracy is lower than training, then we are overfitting.
But how much do these values need to be off for us to be confident that indeed we are dealing with overfitting? I was watching the video here, and my ears perked up when Jeremy said, “But here you can see I’m massively overfitting.”
Looking at the values at this time in the lecture (at the end of the MNIST training), we have
Training accuracy: 0.9961
Validation accuracy: 0.9911
If this were me working by myself, I am not sure I would have seen a difference of 0.0050 and felt like there was any overfitting going on, much less of a massive scale.
I suspect the answer will be “It depends” (on training set, model architecture, number of epochs, etc), but are there any general rules of thumb for how much disagreement we should have before we smell over (or under, for that matter) fitting?
EDIT:
I was thinking about this a bit more. Maybe it’s not just looking at these 2 values by themselves in isolation, per se, but seeing how these 2 score change epoch to epoch?
When looking at very accurate models, it’s best to look at error rates, not accuracy rates. Here, it’s a .4% error vs .9% error. So more than twice as bad. That’s quite a lot of over-fitting.
Having said that, there’s nothing wrong with some overfitting. The correct amount is unlikely to be zero. Whatever amount gives you the best validation error, is what you want!
I have run the code in the first notebook and also wrote similar code to work on my own datasets. However, one thing that I don’t understand is why the validation accuracy usually is higher than the training accuracy in the first epochs? I would expect the validation accuracy to pretty much always be lower than the training accuracy. Any suggestions?
According to the lecture (and the “patch” above by amanmadaan) you are underfitting…but I think here the difference is really small, and might be due to random artifacts. However, I’m surprise that the validation accuracy can be larger than training accuracy when you underfit. A couple of explanations from stackoverflow (also mentioned in the lecture):
dropout is used in the training set but not in the validation set
training set is larger and hence it is subject to much more variability
Anyway, in the last link, it is said that this is a “rare phenomenon”.
I have a small architecture of 5 layers with training images of 89k and validation images of 25k using softmax and categorical entropyloss my validation acc is 0.9956 and training acc is 1, when i test it i am getting bad results, is my data getting overfitted? because when i run the same architecture with lesser number of training and validation images i am getting good results