I am training on chest Xray dataset from kaggle, and I use the training test and validation dataset provided to train and evaluate on Resnet-50. I am loading the data as follows:
data = ImageDataBunch.from_folder(path, train="train", valid='test',test='val', bs=bs, size=224, num_workers=4).normalize(imagenet_stats)
and then the validation on test as follows: learn.validate(data.test_dl)
which output [5.0541553, tensor(0.3750)]
How do I improve/ debug the issue, and training on resnet-34 gave 91% accuracy on validation set and 50% on test set. Also is the right way to load and test the testing dataset?
Note: The validation set seemed to be too small, and hence I have switched tests and validation sets.
Hi @jibinmathew69 it looks like you may be overfitting (decreasing training loss, increasing/high validation loss).
Maybe start with resnet34 and see how the model performs with a less complex base architecture.
If you continue to overfit, maybe try some other regularisation such as data augmentation, or increasing dropout?
I have already experimented with Resnet-34, and the validation accuracy went up to 91% but the on the test set it show 50%. And considering the nature of the image, rotation, zoom form of augmentation didn’t make sense, since it’s Xray and would have same format all through out.
Ahh great. Maybe try increasing drop out and weight decay to see if that improves things?
I also noticed some other things.
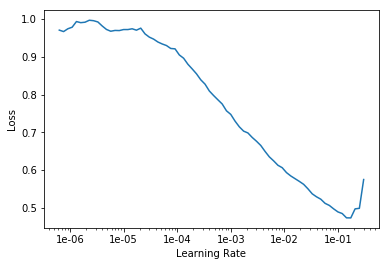
In your first fit_one_cycle run, you could choose a value from the learning rate graph to pass into that function. You would pick the highest learning rate from the steepest point before the loss starts to rapidly increase.
So for example, 1e-02 could be a suitable observation.
learn.fit_one_cycle(8, slice(1e-02))
I would also run lr_find again after you unfreeze. Then from that graph, you can choose an appropriate learning rate range to pass into your fine tuning fit_one_cycle run
From experience, when the training set is not tiny (but even more so, if it’s huge) and validation loss increases monotonically starting at the very first epoch, increasing the learning rate tends to help lower the validation loss - at least in those initial epochs.