Hi Everyone,
I am working on the distracted drivers classification problem using Kaggle states farm dataset. it has 10 classes.
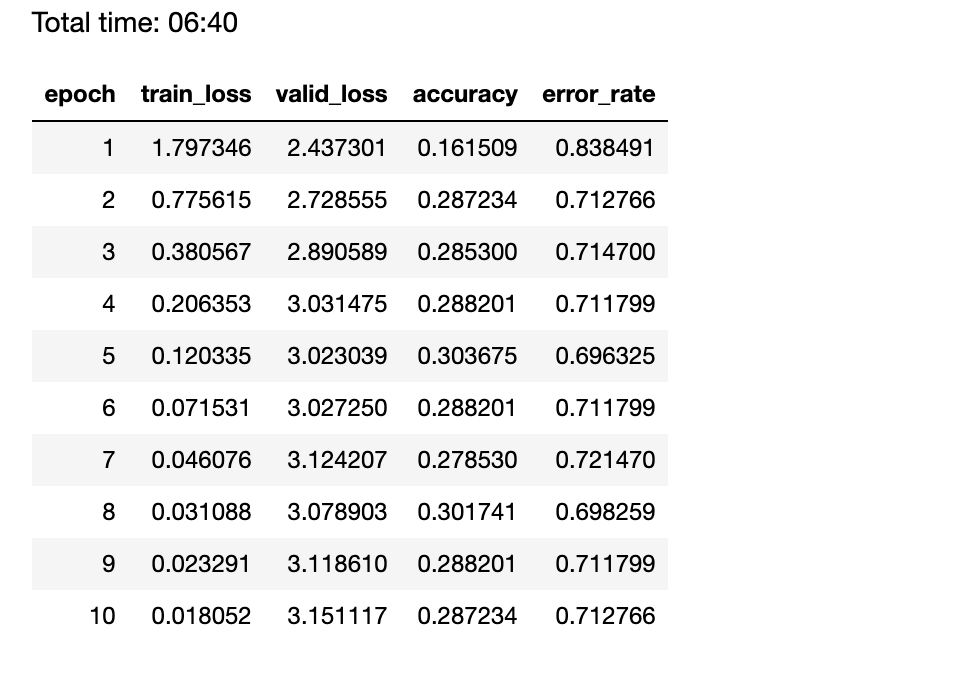
I have started with ResNet-50 with 20% of the data as validation and everything was OK! until I decided to split the validation set by drivers (4 drivers out of the 26) which seems a better idea to match the test set which contains new drivers too.
I started to see strange losses and accuracies for the validation!!
Your validation loss starts to increase at the beginning, it means that you overfit right at the first epoch. It makes sense because your model can’t predict on the new classes that they never seen in the training. you should change your approaches, in case of the new drivers in the test set it should classify it as unknown.
I am not using new classes they are both have similar classes. but the drivers in the validation set are not seen in the training set (to check if the model will generalize well for not seen data)
Would you mind upload your notebook to Github or Kaggle kernel so we can have a look at it? It is pretty hard to tell what is going on just from that screenshot, as there are so many things that could go wrong.