I’m trying to predict if a person is sitting, lying on the floor, standing, lying in bed or sitting in bed with a tabular learner that takes pose coordinates as inputs (x, y, confidence mixed with some room semantic).
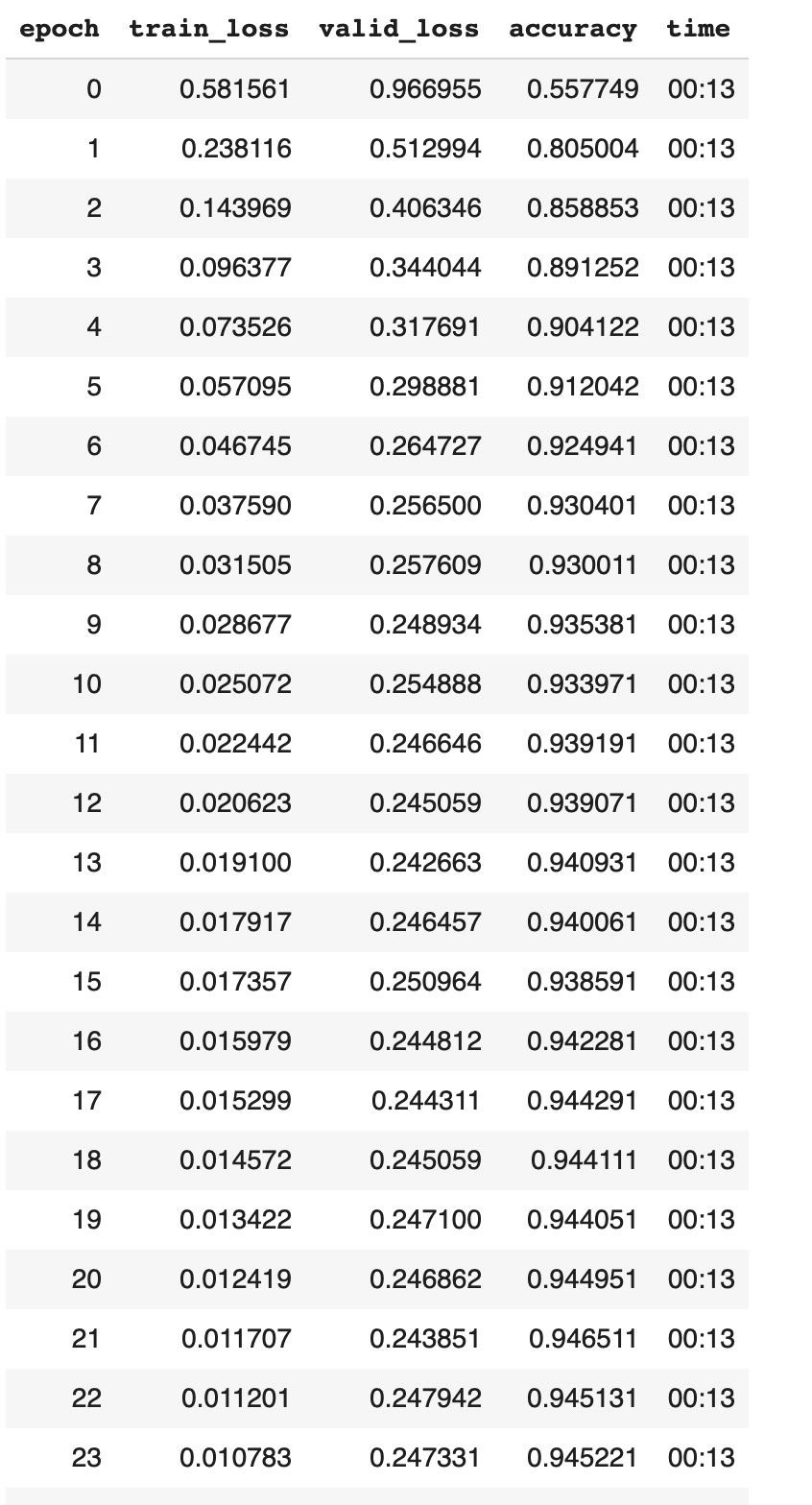
I have 360K annotated poses, of which the majority is sitting, then standing, etc… We got about 20K lying on floor poses. I upsample all training data so all categories are equally represented. The validation set is 2% of the training set. I tried lowering the number of layers. This brings the training loss a bit closer to the validation loss, but the validation loss always is high than the training loss, from the first epoch on. Anyone have any explanation for this?
It’s not correct that validation loss > training loss always means overfitting. You never want to have a model where training loss is > validation loss, that would mean you didn’t train enough and are underfitting. (See lesson 2 of last year’s course, starting from 49:00 to 53:00)
As long as your accuracy doesn’t get worse, you’re not overfitting