Kaggle gives us a Train set, which I split into Train and Test set, and a Validation and Validation Solution (y), which was used to calculate the leaderboard.
Jeremy makes the point that it is really important to make sure that the performance on the Test set is similar to the performance on the Validation set. Otherwise, we are tuning our RF for Test set results and we’ll have a nasty surprise at the end when facing the validation set.
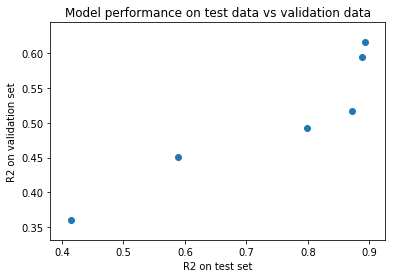
So, I built a couple of RF models and plotted R2 on test set vs validation set. I did not get a linear dependence between performance on the test set and validation set. So, what to do now?
My view is that this is part of Kaggle’s characteristics as well as real life data: validation set does not have the same distribution as test set, and we will never know for sure.
The shakeup in kaggle ranking at the end of the competition (difference between public and private test set) is also partly due to this.
If that’s the case [that because of differences in the distributions of the two data sets the analysis above is limited] then it would be nice if Jeremy would make this point more clear and not give me false hopes
Do you have any other favorite methods of comparing the test set and the validation set?