This is exactly what’s bothering me for a week now! I couldn’t believe what I was seeing!
@binga the accuracy of your LM seems really high, and of the classifier really low. Is that something to do with the dataset you’re using?
I was wondering the same.
I’m rechecking my classifier dataset if I’ve parsed and collected the labels correctly. Let me get back to you on this.
1 Like
The language model seems to be giving out decent results (val.loss: 2.692, perplexity: 14.7742, accuracy: 0.5978). However, when I’m doing text generation, the results aren’t great. Maybe this perplexity for Telugu language is not sufficient to produce good results.
The bigger bad news is I’m unable to replicate my accuracies on the sentiment task. It’s way worser now although the language model accuracy has improved by more than 3 basis points. 
The sentiment task val.loss is now more than 0.693 and that’s so depressing. There should be a bug somewhere.
1 Like
What’s the best sentiment accuracy that you are aware of, on that dataset you are using?
The authors (paper here: http://www.aclweb.org/anthology/W17-5408) claim an error rate of 12.3% but they don’t talk / cite about their approaches at all.
I’m currently able to hit around 47%. Pretty Very bad!
Let’s figure it out man… perhaps a minor bug somewhere
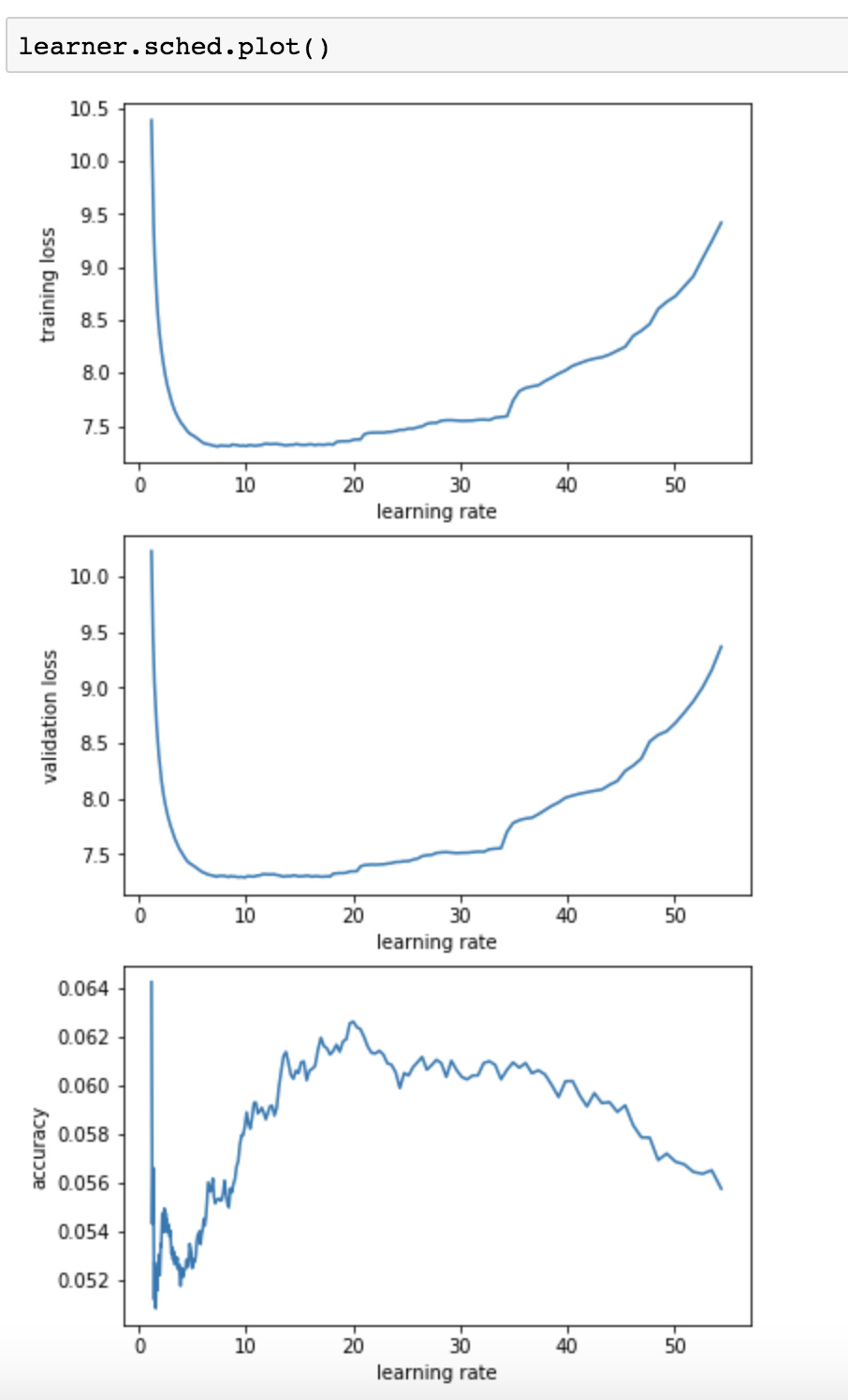
Trying lr_find2 on my language model. Can someone explain what the best LR would be based on these plots, and why? I still don’t totally understand how the LR finder works
1 Like
I’d guess ~3. Although if you’re running with a long warmup, you may be able to go higher.
Thank you. And the reason is because you want to pick some point before the bottom of the curve?
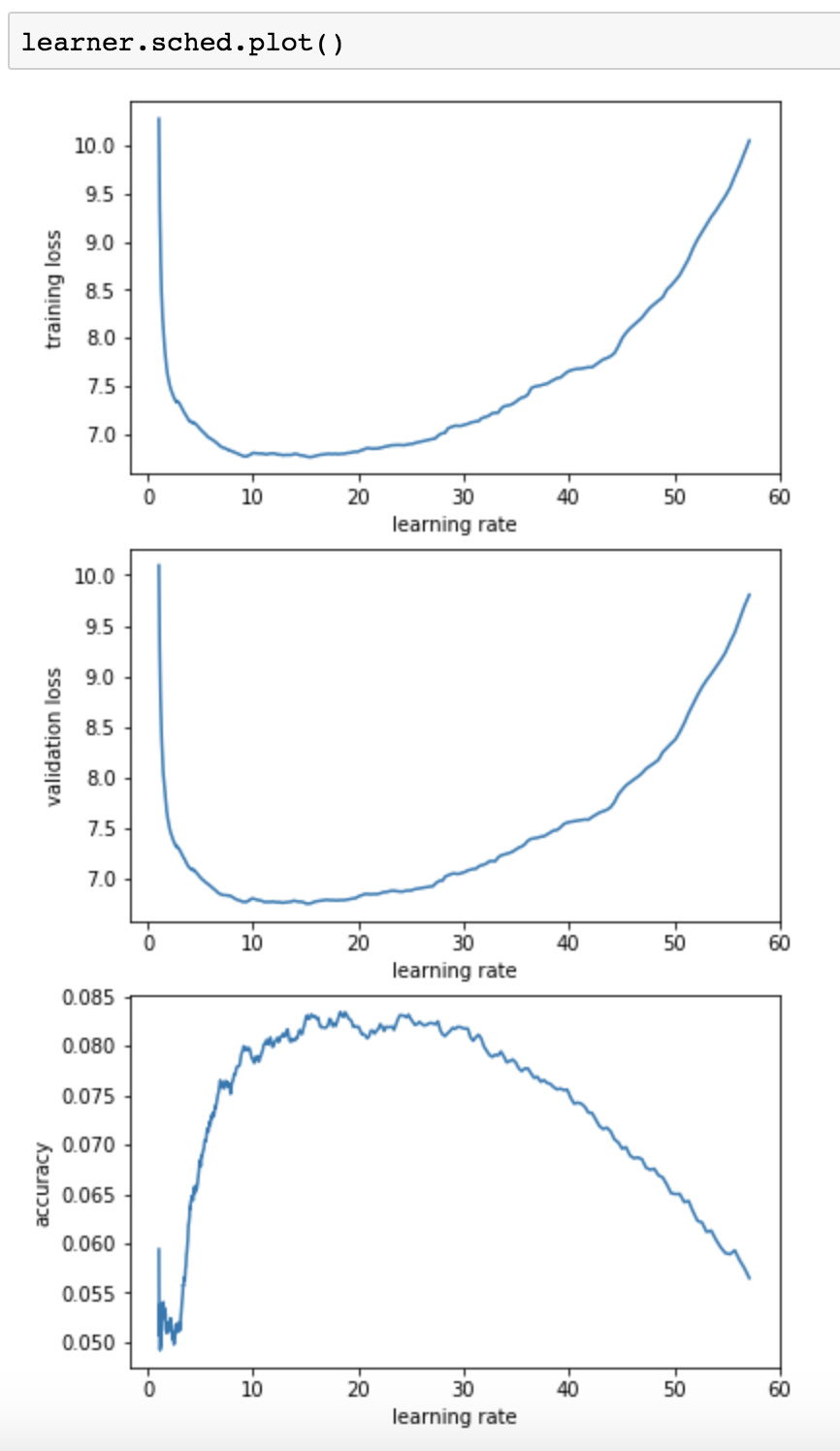
Also interesting: I ran it with 500 instead of 250 iterations, and the curves start to smooth out. I guess that makes sense though
Usually we choose 1/10th of the point it starts to go wrong, so here 30 -> 3.
With the 1cycle policy, you can go a bit further, to something like 8 or 10, but I’ve found RNNs are very resilient to high learning rates, so I wouldn’t be surprised that 20 or even 30 doesn’t make the training diverge. If you’re using gradient clipping, you can even go a bit further and still gain some points in validation loss (at the end of the cycle of course).
4 Likes
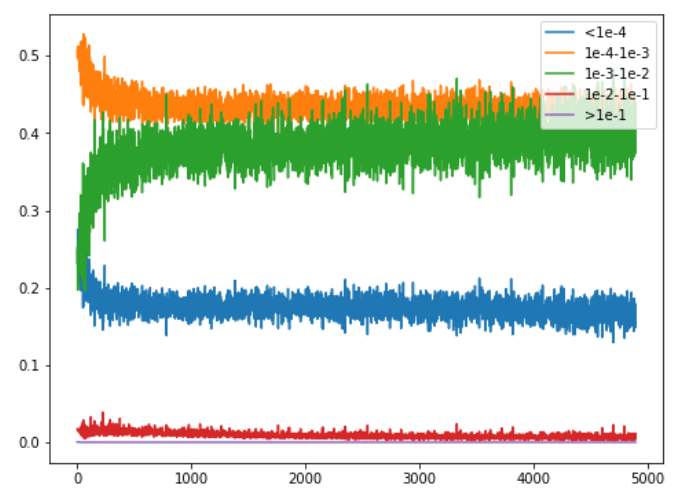
Still trying to understand why the 1cycle policy actually works, I’ve recorded some kind of histogram of the gradients this time. More precisely, I was interested in seeing how many where between 1e-i and 1e-(i+1) as the training went along. This is for a Resnet50 on cifar10.
First comes the training with a constant learning rate of 1e-2. There’s a bit of shuffle at first, but then we get about 18% of lrs really low (<1e-4) then 45% in the range 1e-4 to 1e-3, 38% in the range 1e-3 to 1e-2 doesn’t move much after a while
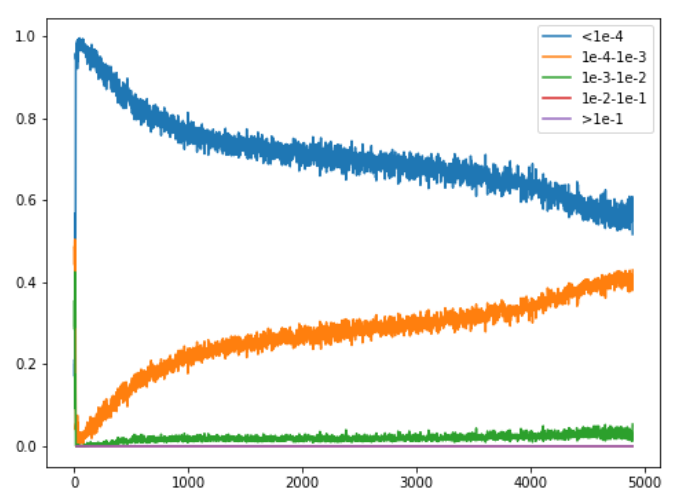
Very interestingly, the same graph for a 1cycle with high learning rates and super-convergence is completely different:
 4
4
During the warm-up we instantly kill all the gradients, with 100% at less than 1e-4, then the rest of the training is all about them going a little bit more up, with 40% in a range 1e-4 to 1e-3 and 60% still below 1e-4.
No wonder we need all this time at high learning rates to get the model to train!
5 Likes
??? 1e-2?
Edited, sorry for the typo 
Very nice. You might be interested in this analysis of gradients by layer: [1708.03888] Large Batch Training of Convolutional Networks . It also suggests an algorithm (LARS) which may just solve our problems…
hey @sgugger, what progress have you made on applying super-convergence on wikitext-2? Would you mind sharing a notebook on the progress you’ve made?
I took a look at your pointer cache notebook, but did not see the part where you trained the language model.
I’ll share it soon-ish (tomorrow or this weekend). Sadly I never got the results I hoped for (though I’m not too far) but I’m cleaning up things to share my findings.
2 Likes
Hi,
I am training a LM on text from around 100K web-contents. I noticed in the first 1cycle the loss and accuracy both are continuously improving but in the second 1cycle it only improves at the last 2 epochs, which is the percentage of epochs on the last part. I wonder if someone can help. What are the best parameters for the second 1cycle if we want to train our model further? This is a very big text and it takes about 5 days to complete 1cycle of 20 epochs. Also, I used Wikitext103 to initialize the weights of my model.
lrs=np.array([1e-4,1e-3,1e-3,1e-2])
learner.fit(lrs, 1, wds=wd, use_clr_beta=(40,10,0.95,0.8), cycle_len=20,use_wd_sched=True, best_save_name='vmi_best_cycle2')
epoch trn_loss val_loss accuracy
0 4.024065 3.808461 0.360849
1 3.852956 3.668784 0.384564
2 3.839158 3.596796 0.39848
3 3.73017 3.552418 0.407026
4 3.748169 3.52563 0.411557
5 3.69027 3.537637 0.41519
6 3.626462 3.478509 0.418335
7 3.601391 3.470867 0.421131
8 3.627678 3.453118 0.421886
9 3.698424 3.419897 0.427011
10 3.55402 3.390787 0.431517
11 3.523406 3.364544 0.434565
12 3.531432 3.342625 0.437428
13 3.496553 3.32466 0.443213
14 3.493872 3.292935 0.445534
15 3.534116 3.273344 0.448283
16 3.564222 3.251854 0.450747
17 3.53877 3.217889 0.455867
18 3.462281 3.206595 0.458111
19 3.51607 3.205203 0.458829
learner.fit(lrs, 1, wds=wd, use_clr_beta=(40,10,0.95,0.8), cycle_len=20,use_wd_sched=True, best_save_name='vmi_best_cycle2')
Epoch
100% 20/20 [116:10:58<00:00, 20912.95s/it]
epoch trn_loss val_loss accuracy
0 3.476169 3.250627 0.451431
1 3.58667 3.282692 0.448689
2 3.549398 3.309879 0.446871
3 3.491273 3.319043 0.445644
4 3.51448 3.334146 0.444118
5 3.574472 3.337171 0.442159
6 3.470438 3.328665 0.442557
7 3.521126 3.347762 0.439934
8 3.593492 3.359031 0.438734
9 3.515926 3.333626 0.440192
10 3.498867 3.316412 0.443602
11 3.54155 3.307331 0.445697
12 3.48213 3.289861 0.448782
13 3.487045 3.273117 0.450817
14 3.436541 3.261084 0.453736
15 3.440088 3.230088 0.455999
16 3.449882 3.209518 0.458923
17 3.553759 3.173916 0.463115
18 3.413137 3.162565 0.465644
19 3.404412 3.159237 0.466375Why do you want to train twice? 1cycle is meant to be used only once, that’s why you don’t see any improvement the second time.
Your main training already comes to amazing results (24.5 ppl!) and you’re underfitting so you should try reducing dropouts or weight decay a bit.
1 Like