Since it’s all fairly new, I wanted to use this thread to ask other fastai users who used the 1cycle policy to share the situations where it worked and where it didn’t (or did less), so that we all get a better understanding on when to use it.
In my (short) experience this works miracles when trying to make a model learn from scratch (as Jeremy proved in last lesson) but less so when you work with a pretrained model you want to fine-tune to a specific situation. In particular, I didn’t find good results (not as good as Adam with use_clr for instance) when trying to first train the added layer with a 1cycle, then unfreeze and train the whole network with another (using differential learning rates) but perhaps I did it wrong. What gave me better result was to train quickly the added layer then do a long 1cycle for the unfrozen network.
In general, one longer cycle always gives better results than doing two shorter ones in a row.
It is a disaster with Adam: the training diverges once out of two, and you can’t use as high learning rates. I may have an explanation for that. The general idea of Leslie’s paper is that during the 1cycle training, we’ll get in a flatter area of the loss function and high learning rates will allow us to travel through it quickly. Flatter means lower gradients, and in Adam with divide each parameter by the moving average of the gradients squared. So high learning rate divided by a little something means explosion.
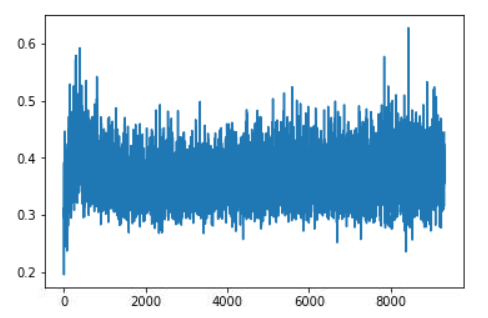
To support this, I’ve recorded the mean of all the absolute values of the gradients in my training of a resnet56 over cifar10, one with a 1cycle and one at constant learning rate.
This is during the constant training:
This is with the 1cycle:
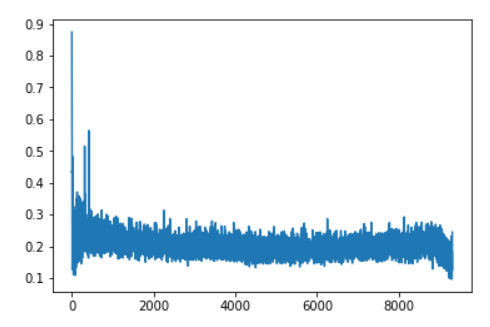
There are a few spikes at the beginning but we indeed end up fairly quickly in a reasonably flat area, which seems to be very wide in the sense that the gradients don’t spike as high as with a constant LR. The slope at the end corresponds to the part where we decrease the learning rate further, which means we get closer to a minimum of the loss function (but it’s also the part where we overfit more).
That’s for my feedback at this stage, looking forward to reading other’s experience!