Considering this is one of the most asked questions on the forums, I wrote an article discussing how to bring in Pytorch into fastai including:
- Optimizer
- Model
- Datasets
- DataLoaders
Said article can be found here:
https://muellerzr.github.io/fastblog/2021/02/14/Pytorchtofastai.html
Normally I wouldn’t double-post, but considering this is such an asked question here on the forums, I’m going to go ahead and walk everyone through how to do so. What follows will be a minimal explanation and example based on the aforementioned article
Learner and Pytorch Models vs cnn_learner, tabular_learner, etc
The most important step when bringing in raw Pytorch into fastai is understanding that Learner is fastai’s base class for training. So when we bring in custom models, we should do Learner(dls, mymodel, ...) rather than cnn_learner or tabular_learner, as all of those functions have specific magic for their applications and how they should be used
Note:
Learnerexpects a full Pytorch model, not a function. So you should be passing in an instance of your model such asLearner(dls, MyModel())
Pytorch DataLoaders
When working with Pytorch DataLoaders, the only thing you need to do to have it work with the fastai training loop is wrap them into fastai’s DataLoaders class such as so:
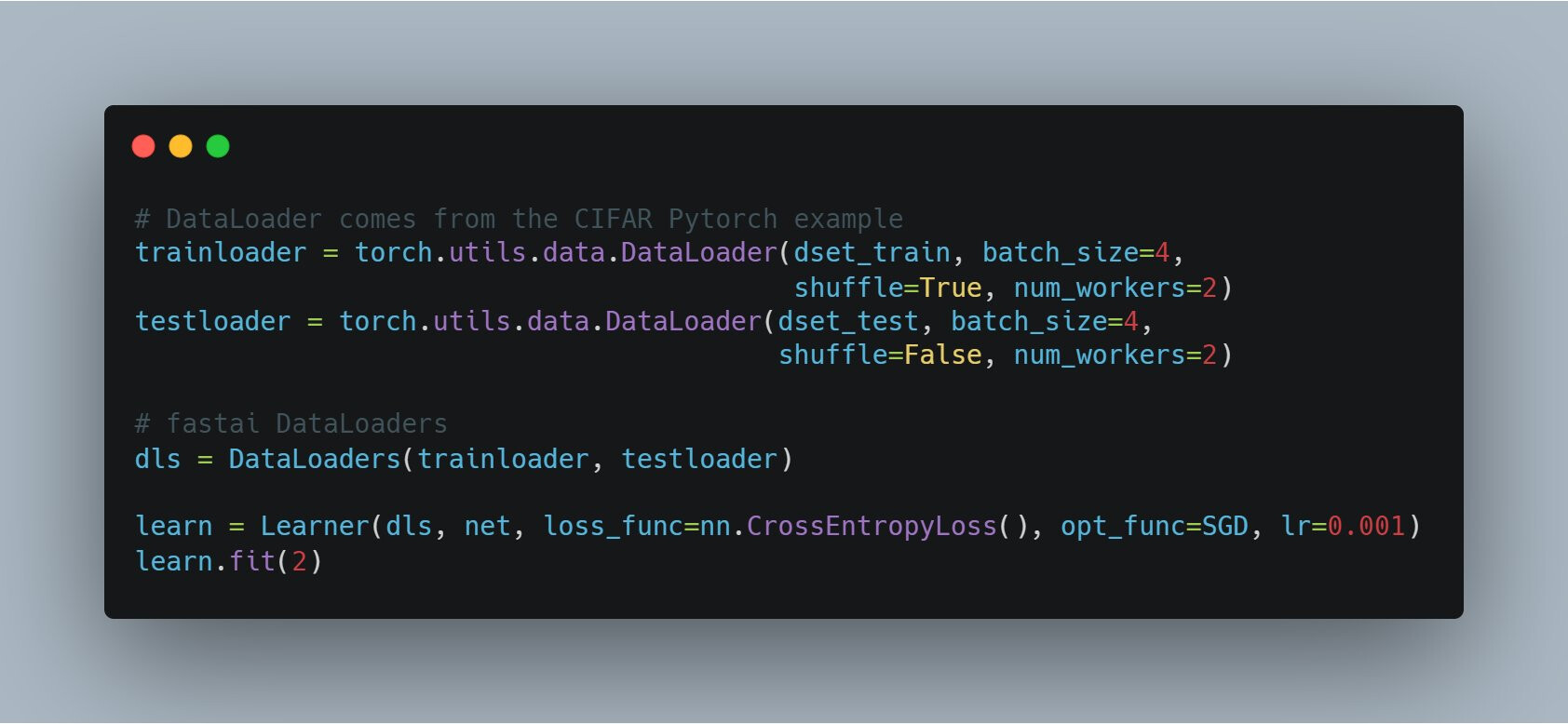
Moving Pytorch DataLoaders to the GPU
fastai will now determine the device to utilize based on what device your model is on. So make sure to set learn.model to cuda() (or just your own model) before fitting
Pytorch Optimizers
When dealing with Pytorch optimizers, fastai has a OptimWrapper class, so any time you want to utilize a pytorch optimizer, simply define a little function (we’ll call it opt_func) that looks like so:
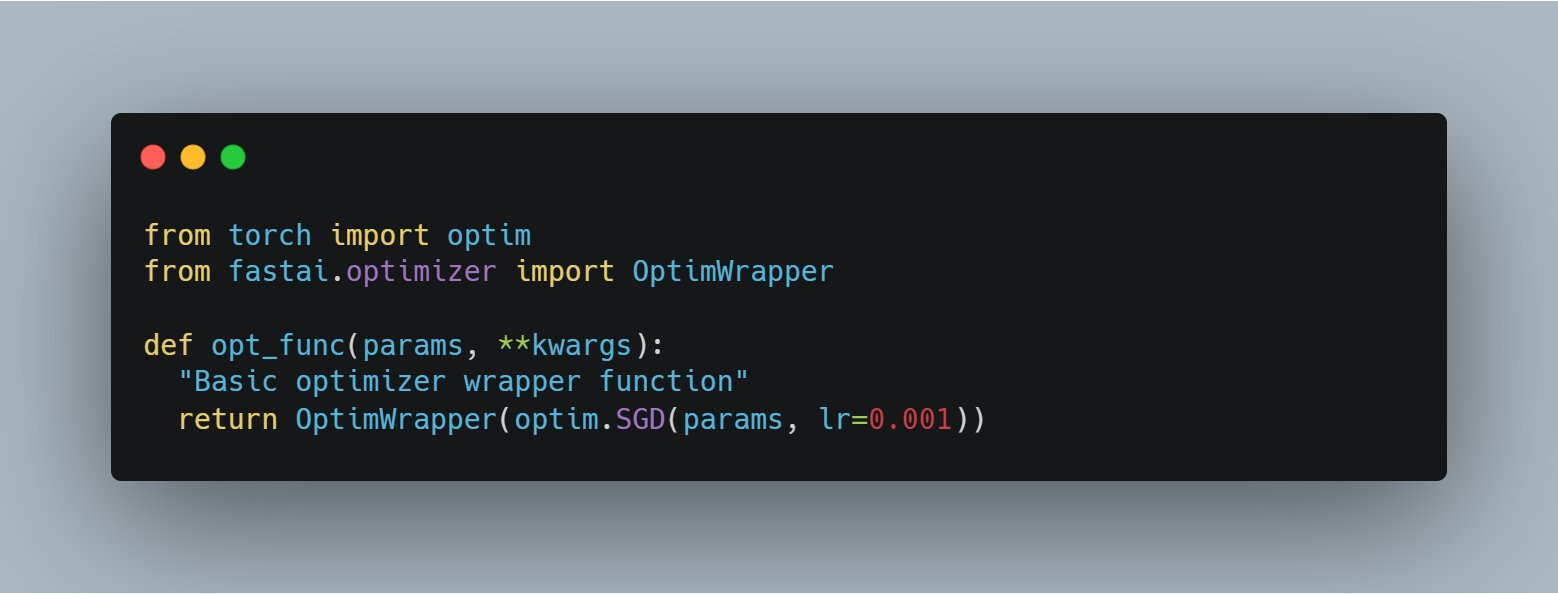
Where we’ve wrapped our Pytorch optimizer inside of this class, and this will work for us during training
Minimal Imports
If you choose to go this route, the only imports from fastai you truly need are:
from fastai.callback.progress import ProgressCallback
from fastai.data.core import DataLoaders
from fastai.learner import Learner
from fastai.optimizer import OptimWrapper
From there if you want access to the learning rate finder, fit_one_cycle, etc I would recommend from fastai.callback.schedule import *, or import the specific fit function you need from schedule
Limitations
Given you’re using Pytorch DataLoaders, you get none of the fastai data magic. This means you will not have access to test_dl, nor predict. get_preds will still work, however you’ll need to build a proper DataLoader yourself
I hope this post and blog will help someone in the future, who wants to understand just how simple fastai can truly be used when used with raw Pytorch