Hi Everyone,
I have a problem at hand which requires fine-grained image classification, for example, season in women’s dresses. Winter dresses are typically tight, have a different fabric than summer and are warm; summer on the other hand are loose and flowy.
For the model to do metric learning, I have used a resnet50 head followed by adaptive pooling in fastai and a inear layer to reduce the embedding dimension to 512 .
In the dataset, I have sampled 2 classes with a batch size of 32 i.e. 16 images per class for comparison.
Using Multi-Similarity Loss, I have used alpha = 2 (positive pairs weightage), beta = 50 (negative pairs weightage) and base = 0.5 as mentioned in the paper. Any suggestions on tuning these are also welcome.
This is the embedding plot below for the two classes which was constructed using umap with n_neighbours = 10.
(Plain Resnet50)
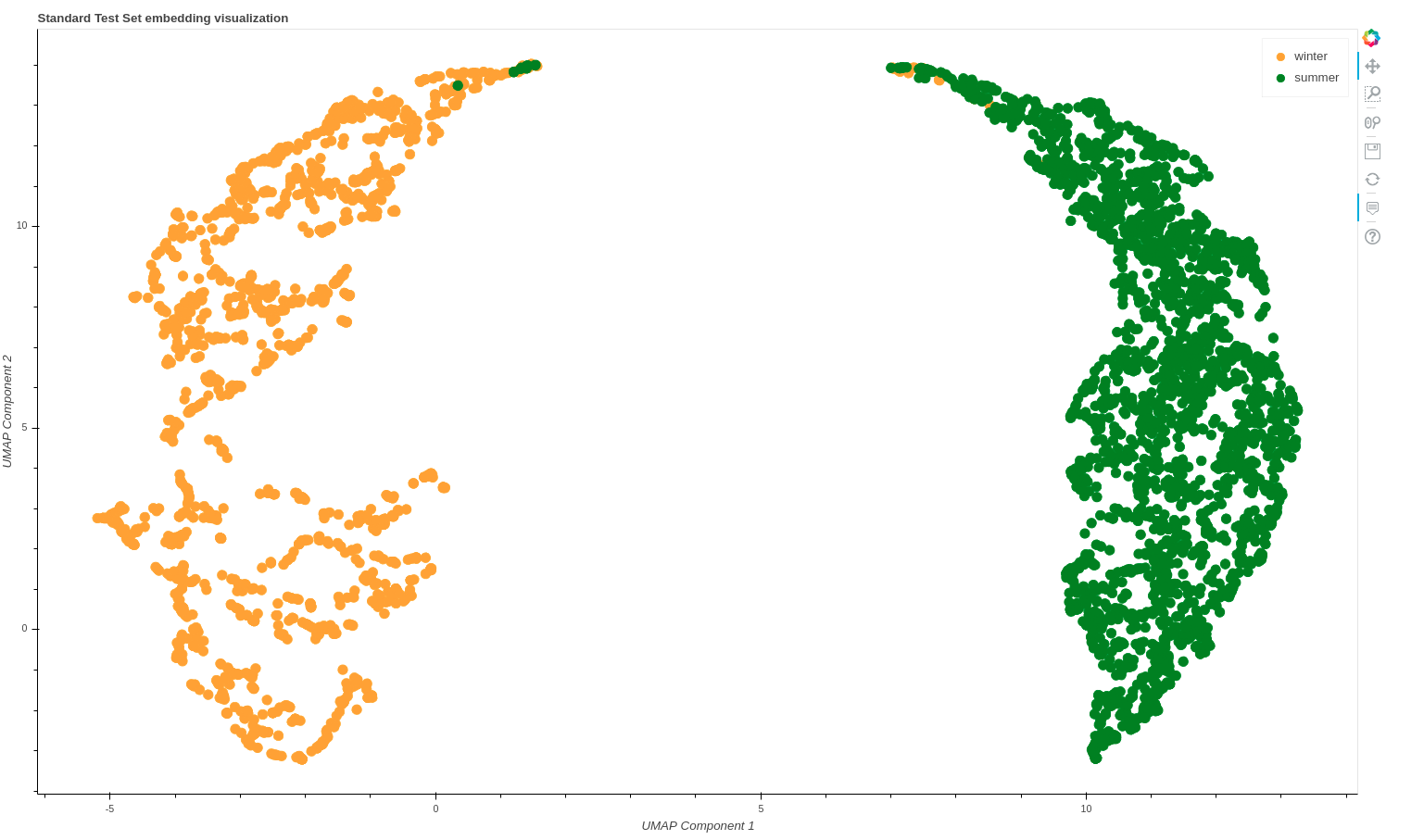
(Metric Learning using Resnet50)
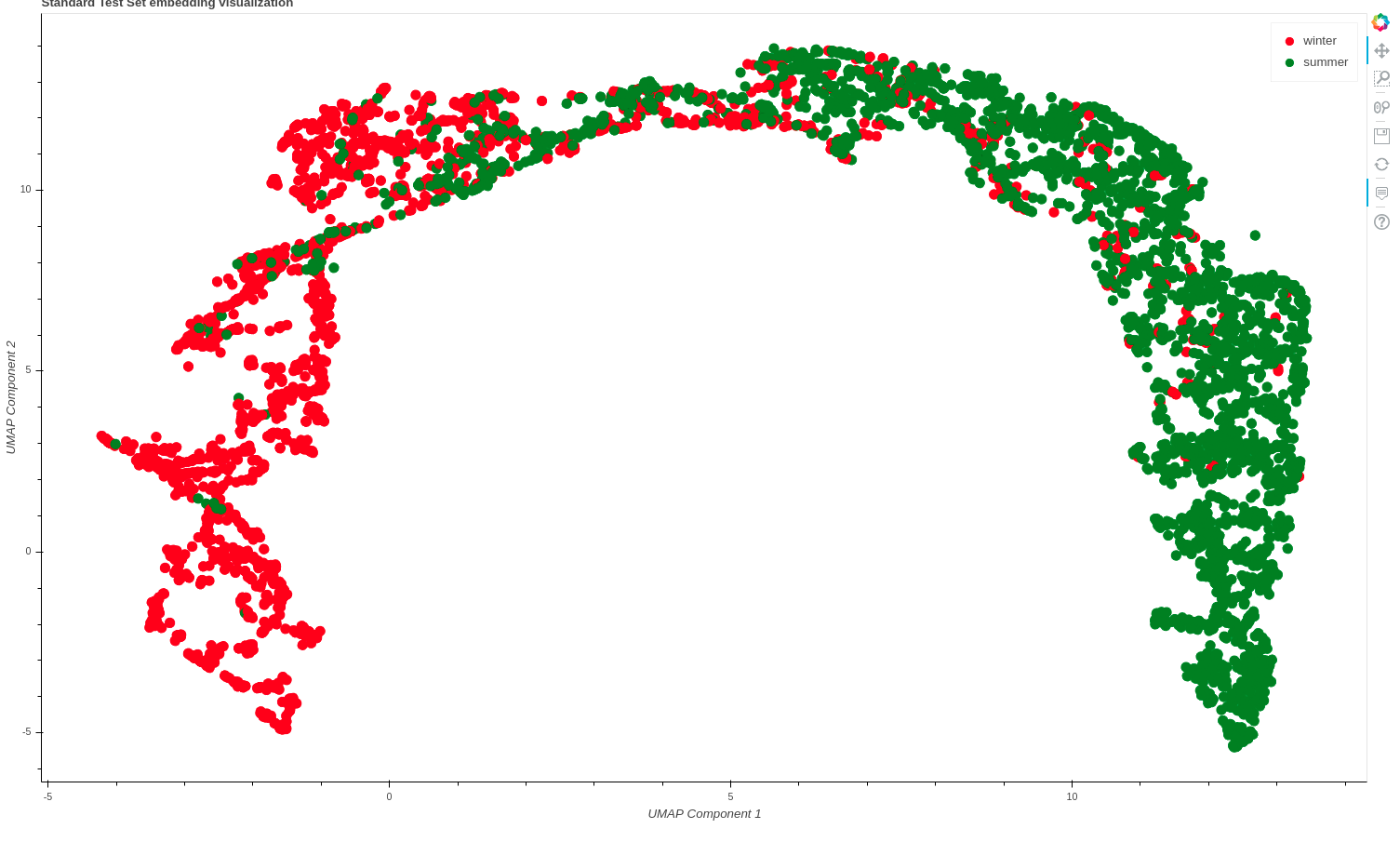
With a plain resnet-50 architecture embeddings are more distinctly separated than metric learning… Any insights are appreciated.
Sincerely,
Vishal