Hi!
First of all, huge thanks to Jeremy and Rachel for putting together such a great course!
I am working on a project in cooperation with the Norwegian Coastal Authority where my goal is to predict most probable future positions for a ship, to ultimately use deviation from this normal model to detect anomalies. This can be extremely useful to prevent ships from running aground, detect illegal waste dumping etc.
I have a huge dataset of over 14*10^9 position-updates from ships over the last three years.
I have cleaned, enriched and preprocessed the data, so my current dataset looks like this:
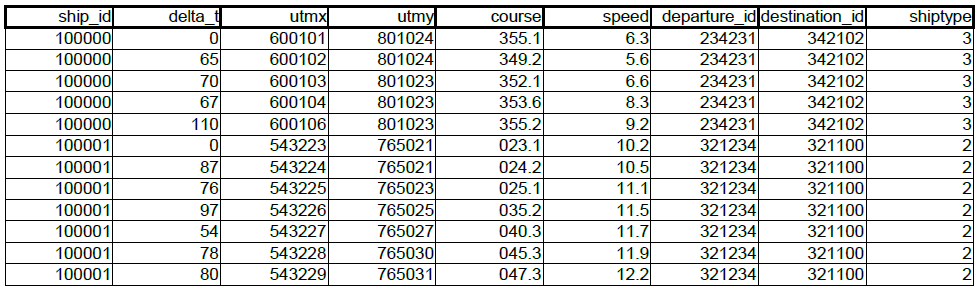
(A bit simplified, but you get the gist of it)
Up until now I have used clustering(DBSCAN ++) to extract representative vectors for the data, and have gotten pretty good results, but I have a feeling that an LSTM can learn to model this function extremely well with this amount and type of data. The key is that I want the model to learn what behavior that is normal for each area based on voyages that may have happened a long time ago, as well as the short-term dependencies, such as current position, speed and course.
Having little experience in implemententing RNN`s I would really appreciate some inputs on the following:
-
I am thinking this needs to be a many-to-many sequence prediction. I assume I will have to split up the dataset in voyages, and reset state between each voyage, so that one voyage is one sequence. The length of the voyages is different for each voyage. This sets me off a bit as most examples in Keras uses 3D input (N,W,F), where N is number of sequences, W is sequence length, and F is number of features. One possible approach is to map each sequence to a fixed length vector. Thoughts regarding this? I am a bit confused about what size to use for the inputs and outputs. I would like at least 10 predictions as the output. Does that mean I will have to use [n:n+10] as each input and [n+11:n+21] as output? Or would I use [n:n+10] as input and [n+1:n+11] as output? (Using numpy slicing notation)
-
Inputs on technology to use. I have used Keras before and starting to get comfortable with it. Theano vs. Tensorflow backend? Read that you are moving away from Theano towards Tensorflow. Would you recommend that for this case? I also have read about Tensorflow`s seq2seq, which seems promising, but I have not fiddled around with yet. Is it worth to get acquainted with for this purpose?
-
Using floats or categoricals for the input features. I noticed the sparse_categorical_crossentropy can use integers, but I am assuming not floats. Would it be worth it to scale these features to integers to avoid using one hot encoding. The sizes of matrices would need to be extremely large. Thinking about the utm coordinates, which span over 2 million values each. Or are these created behind the scenes anyway?
-
Inputs on model design. My thoughts are to try to start with some simple ones, and maybe try something like the one Jeremy used for predicting the Nietsche-text in lesson 5. Any tips on designs that is worth trying? (Batchnorm, dropout etc…)
Thanks to everyone that bothers to read, and perhaps have some suggestions for me. PS. I saw that some lessons from part 2 of the course is released, so if any of my questions are clarified there somewhere, please point me in the right direction.