I am currently on lesson 2, working on an image classifier for cormorants, magpies, blue jays, ravens, crows and cormorants. I’m having a hard time selecting a learning rate because when I run learn.lr_find and learn.recorder_plot I get drastically different plots each time.
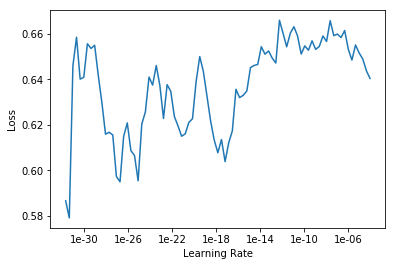
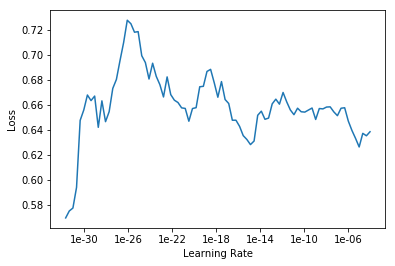
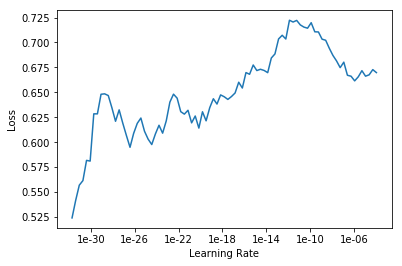
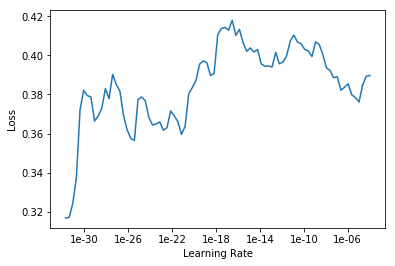
Each plot was produced on the same ImageDataBunch using the same 4 lines of code:
learn = cnn_learner(data, models.resnet50, metrics=error_rate)
learn.fit_one_cycle(1)
learn.lr_find(start_lr=1e-35, end_lr=1e-2)
learn.recorder.plot()
My error rate after fit_one_cycle(1) is usually between 21% and 25% but sometimes as high as 28%) If I do more epochs I can get it down to ~16%-18%, but no better.
Any advice on how I should select the optimal learning rate? Should I run more epochs to get the error rate down to 20% before turning to lr_find?
Note: My “most confused” looks reasonable:
[(‘ravens’, ‘crows’, 24),
(‘crows’, ‘ravens’, 8),
(‘western_jackdaws’, ‘crows’, 6),
(‘crows’, ‘western_jackdaws’, 5),
(‘ravens’, ‘western_jackdaws’, 4),
(‘western_jackdaws’, ‘ravens’, 4),
(‘bb_magpies’, ‘blue_jays’, 2),
(‘bb_magpies’, ‘crows’, 2),
(‘bb_magpies’, ‘ravens’, 2),
(‘crows’, ‘bb_magpies’, 2),
(‘crows’, ‘cormorants’, 2)]
Could the difficulty of differentiating crows from ravens be causing problems?
Note 2:
Could I be creating the DataBunch Incorrectly? When I try to run:
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_top_losses
I get:
AttributeError Traceback (most recent call last)
<ipython-input-55-34fc804e24e7> in <module>
----> 1 interp.plot_top_losses(9, figsize=(15,11))
/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/vision/learner.py in _cl_int_plot_top_losses(self, k, largest, figsize, heatmap, heatmap_thresh, alpha, cmap, show_text, return_fig)
174 if show_text: fig.suptitle('Prediction/Actual/Loss/Probability', weight='bold', size=14)
175 for i,idx in enumerate(tl_idx):
--> 176 im,cl = self.data.dl(self.ds_type).dataset[idx]
177 cl = int(cl)
178 title = f'{classes[self.pred_class[idx]]}/{classes[cl]} / {self.losses[idx]:.2f} / {self.preds[idx][cl]:.2f}' if show_text else None
/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/data_block.py in __getitem__(self, idxs)
647 def __getitem__(self,idxs:Union[int,np.ndarray])->'LabelList':
648 "return a single (x, y) if `idxs` is an integer or a new `LabelList` object if `idxs` is a range."
--> 649 idxs = try_int(idxs)
650 if isinstance(idxs, Integral):
651 if self.item is None: x,y = self.x[idxs],self.y[idxs]
/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/torch_core.py in try_int(o)
365 "Try to convert `o` to int, default to `o` if not possible."
366 # NB: single-item rank-1 array/tensor can be converted to int, but we don't want to do this
--> 367 if isinstance(o, (np.ndarray,Tensor)): return o if o.ndim else int(o)
368 if isinstance(o, collections.Sized) or getattr(o,'__array_interface__',False): return o
369 try: return int(o)
AttributeError: 'Tensor' object has no attribute 'ndim'