Please, do you have a practical example of how you worked with:
SegmentationItemList._label_cls.open
I’m having the same problem. I believe that there is some inconsistency in the way the data was constructed. I’m a beginner, I’ve tried all the suggestions here and some others. I’m trying to keep things cool.
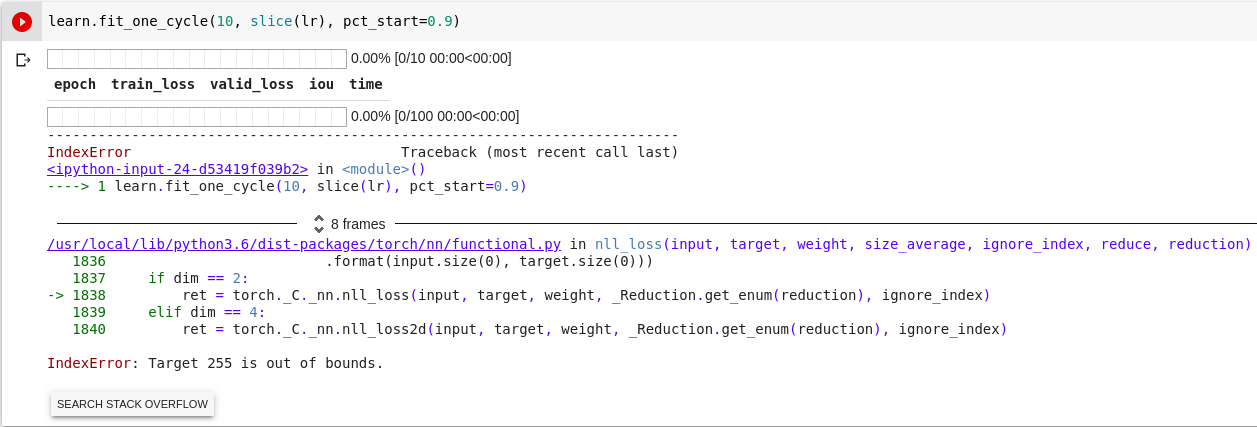
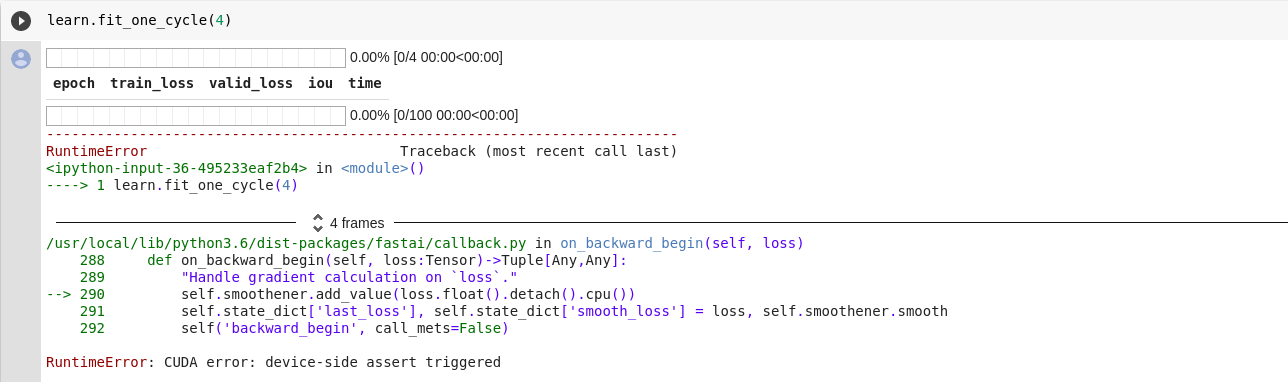
The error in my jupyter:
RuntimeError: CUDA error: device-side assert triggered
The error looking at the CPU:
C:/w/b/windows/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: block: [0,0,0], thread: [29,0,0] Assertion t >= 0 && t < n_clas ses failed.
Regarding the mask:
[In] src_size, mask.data
[Out] (array([864, 864]),
tensor([[[163, 132, 132, …, 132, 132, 163],
[132, 90, 90, …, 90, 90, 132],
[132, 90, 90, …, 90, 90, 132],
…,
[132, 90, 90, …, 90, 90, 132],
[132, 90, 90, …, 90, 90, 132],
[163, 132, 132, …, 132, 132, 163]]]
I built my database myself. When I did the manual segmentation I used the PixelAnnotation API. It was built for highway segmentation. Then, its segmentation is predetermined, that is, the colors of the segmentation of the colored mask is still selected in the API. And the corresponding gray mask is then built automatically.
The signature of the segmentation of classes by PixelAnnotation was as
| Class |
Pixel intensity |
| Background |
90 |
| Peca |
128 |
| DefeitoGrave |
76 |
| DefeitoBrando |
177 |
The mask appears to be coherent. Except for markers 132 (edges) and 163 (extremity). They seem to me to be a kind of signature of the edges and ends. Can anyone tell me if I am correct in thinking like this or if it is a mistake that I need to correct?
About classes:
[In] codes = np.loadtxt(path/‘codes.txt’, dtype=str); codes
[Out] array([‘Background’, ‘Peca’, ‘DefeitoGrave’, ‘DefeitoBrando’], dtype=‘<U13’)
So, if I do:
[In] name2id = {v:k for k,v in enumerate(codes)}
print(name2id)
[Out] {‘Background’: 0, ‘Peca’: 1, ‘DefeitoGrave’: 2, ‘DefeitoBrando’: 3}
The classes represented in the script by ‘codes’ are a total of 4, and are indented from 0 to n-1. So, respect the conditions that some comment. However, classes are indented from 1 to 3.
So, what intrigues me. My classes are signed from 0 to 3 but on the mask the same signature is represented by 90, 128, 76, 177. Shouldn’t they be the same? If so, any suggestions or material on how to correct it?
Could this problem be related to the image size? Of course not!?
Is the mask represented by a single channel image? Correct, right?
Environmental information:
Windows 10
pytorch 1.6.0
cuda 10.2
fastai 1.0.61
GeForce GTX 1050 Ti