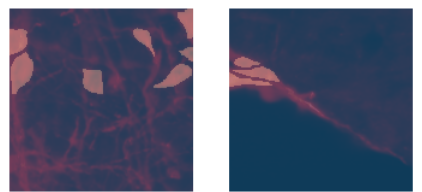
Hello, I’m new to fastai and I was experimenting with it for a semantic segmentation application. Starting from the tutorials, I understand that the suggested dataloader to adopt is SegmentationDataLoaders. However, it runs fine for loading and showing a batch:
dls = SegmentationDataLoaders.from_label_func(
path, bs=1, fnames=fnames, label_func=label_func2, codes=['Bkgd', 'Red'], shuffle_train=True)
dls.show_batch(max_n = 6, figsize=(12,12))
but then it fails when I try to fine tune a model:
learn = unet_learner(dls, arch=resnet34)
learn.fine_tune(6)
throwing RuntimeError: CUDA error: device-side assert triggered :
RuntimeError Traceback (most recent call last)
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/learner.py in _with_events(self, f, event_type, ex, final)
153 def _with_events(self, f, event_type, ex, final=noop):
--> 154 try: self(f'before_{event_type}') ;f()
155 except ex: self(f'after_cancel_{event_type}')
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/learner.py in _do_one_batch(self)
168 self('before_backward')
--> 169 self._backward()
170 self('after_backward')
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/learner.py in _backward(self)
150 def _step(self): self.opt.step()
--> 151 def _backward(self): self.loss.backward()
152
~/anaconda3/envs/fastai/lib/python3.7/site-packages/torch/tensor.py in backward(self, gradient, retain_graph, create_graph, inputs)
243 create_graph=create_graph,
--> 244 inputs=inputs)
245 torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
~/anaconda3/envs/fastai/lib/python3.7/site-packages/torch/overrides.py in handle_torch_function(public_api, relevant_args, *args, **kwargs)
1201 # implementations can do equality/identity comparisons.
-> 1202 result = overloaded_arg.__torch_function__(public_api, types, args, kwargs)
1203
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/torch_core.py in __torch_function__(self, func, types, args, kwargs)
318 # with torch._C.DisableTorchFunction(): ret = _convert(func(*args, **(kwargs or {})), self.__class__)
--> 319 ret = super().__torch_function__(func, types, args=args, kwargs=kwargs)
320 if isinstance(ret, TensorBase): ret.set_meta(self, as_copy=True)
~/anaconda3/envs/fastai/lib/python3.7/site-packages/torch/tensor.py in __torch_function__(cls, func, types, args, kwargs)
961 with _C.DisableTorchFunction():
--> 962 ret = func(*args, **kwargs)
963 return _convert(ret, cls)
~/anaconda3/envs/fastai/lib/python3.7/site-packages/torch/tensor.py in backward(self, gradient, retain_graph, create_graph, inputs)
244 inputs=inputs)
--> 245 torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
246
~/anaconda3/envs/fastai/lib/python3.7/site-packages/torch/autograd/__init__.py in backward(tensors, grad_tensors, retain_graph, create_graph, grad_variables, inputs)
140 grad_tensors_ = _tensor_or_tensors_to_tuple(grad_tensors, len(tensors))
--> 141 grad_tensors_ = _make_grads(tensors, grad_tensors_)
142 if retain_graph is None:
~/anaconda3/envs/fastai/lib/python3.7/site-packages/torch/autograd/__init__.py in _make_grads(outputs, grads)
50 raise RuntimeError("grad can be implicitly created only for scalar outputs")
---> 51 new_grads.append(torch.ones_like(out, memory_format=torch.preserve_format))
52 else:
RuntimeError: CUDA error: device-side assert triggered
During handling of the above exception, another exception occurred:
RuntimeError Traceback (most recent call last)
<ipython-input-23-ef4fa610f0bf> in <module>
1 learn = unet_learner(dls, arch=resnet34)
----> 2 learn.fine_tune(6)
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/callback/schedule.py in fine_tune(self, epochs, base_lr, freeze_epochs, lr_mult, pct_start, div, **kwargs)
155 "Fine tune with `freeze` for `freeze_epochs` then with `unfreeze` from `epochs` using discriminative LR"
156 self.freeze()
--> 157 self.fit_one_cycle(freeze_epochs, slice(base_lr), pct_start=0.99, **kwargs)
158 base_lr /= 2
159 self.unfreeze()
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/callback/schedule.py in fit_one_cycle(self, n_epoch, lr_max, div, div_final, pct_start, wd, moms, cbs, reset_opt)
110 scheds = {'lr': combined_cos(pct_start, lr_max/div, lr_max, lr_max/div_final),
111 'mom': combined_cos(pct_start, *(self.moms if moms is None else moms))}
--> 112 self.fit(n_epoch, cbs=ParamScheduler(scheds)+L(cbs), reset_opt=reset_opt, wd=wd)
113
114 # Cell
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/learner.py in fit(self, n_epoch, lr, wd, cbs, reset_opt)
203 self.opt.set_hypers(lr=self.lr if lr is None else lr)
204 self.n_epoch = n_epoch
--> 205 self._with_events(self._do_fit, 'fit', CancelFitException, self._end_cleanup)
206
207 def _end_cleanup(self): self.dl,self.xb,self.yb,self.pred,self.loss = None,(None,),(None,),None,None
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/learner.py in _with_events(self, f, event_type, ex, final)
152
153 def _with_events(self, f, event_type, ex, final=noop):
--> 154 try: self(f'before_{event_type}') ;f()
155 except ex: self(f'after_cancel_{event_type}')
156 finally: self(f'after_{event_type}') ;final()
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/learner.py in _do_fit(self)
194 for epoch in range(self.n_epoch):
195 self.epoch=epoch
--> 196 self._with_events(self._do_epoch, 'epoch', CancelEpochException)
197
198 def fit(self, n_epoch, lr=None, wd=None, cbs=None, reset_opt=False):
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/learner.py in _with_events(self, f, event_type, ex, final)
152
153 def _with_events(self, f, event_type, ex, final=noop):
--> 154 try: self(f'before_{event_type}') ;f()
155 except ex: self(f'after_cancel_{event_type}')
156 finally: self(f'after_{event_type}') ;final()
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/learner.py in _do_epoch(self)
188
189 def _do_epoch(self):
--> 190 self._do_epoch_train()
191 self._do_epoch_validate()
192
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/learner.py in _do_epoch_train(self)
180 def _do_epoch_train(self):
181 self.dl = self.dls.train
--> 182 self._with_events(self.all_batches, 'train', CancelTrainException)
183
184 def _do_epoch_validate(self, ds_idx=1, dl=None):
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/learner.py in _with_events(self, f, event_type, ex, final)
152
153 def _with_events(self, f, event_type, ex, final=noop):
--> 154 try: self(f'before_{event_type}') ;f()
155 except ex: self(f'after_cancel_{event_type}')
156 finally: self(f'after_{event_type}') ;final()
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/learner.py in all_batches(self)
158 def all_batches(self):
159 self.n_iter = len(self.dl)
--> 160 for o in enumerate(self.dl): self.one_batch(*o)
161
162 def _do_one_batch(self):
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/learner.py in one_batch(self, i, b)
176 self.iter = i
177 self._split(b)
--> 178 self._with_events(self._do_one_batch, 'batch', CancelBatchException)
179
180 def _do_epoch_train(self):
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/learner.py in _with_events(self, f, event_type, ex, final)
154 try: self(f'before_{event_type}') ;f()
155 except ex: self(f'after_cancel_{event_type}')
--> 156 finally: self(f'after_{event_type}') ;final()
157
158 def all_batches(self):
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/learner.py in __call__(self, event_name)
130 def ordered_cbs(self, event): return [cb for cb in sort_by_run(self.cbs) if hasattr(cb, event)]
131
--> 132 def __call__(self, event_name): L(event_name).map(self._call_one)
133
134 def _call_one(self, event_name):
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastcore/foundation.py in map(self, f, gen, *args, **kwargs)
152 def range(cls, a, b=None, step=None): return cls(range_of(a, b=b, step=step))
153
--> 154 def map(self, f, *args, gen=False, **kwargs): return self._new(map_ex(self, f, *args, gen=gen, **kwargs))
155 def argwhere(self, f, negate=False, **kwargs): return self._new(argwhere(self, f, negate, **kwargs))
156 def filter(self, f=noop, negate=False, gen=False, **kwargs):
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastcore/basics.py in map_ex(iterable, f, gen, *args, **kwargs)
664 res = map(g, iterable)
665 if gen: return res
--> 666 return list(res)
667
668 # Cell
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastcore/basics.py in __call__(self, *args, **kwargs)
649 if isinstance(v,_Arg): kwargs[k] = args.pop(v.i)
650 fargs = [args[x.i] if isinstance(x, _Arg) else x for x in self.pargs] + args[self.maxi+1:]
--> 651 return self.func(*fargs, **kwargs)
652
653 # Cell
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/learner.py in _call_one(self, event_name)
134 def _call_one(self, event_name):
135 assert hasattr(event, event_name), event_name
--> 136 [cb(event_name) for cb in sort_by_run(self.cbs)]
137
138 def _bn_bias_state(self, with_bias): return norm_bias_params(self.model, with_bias).map(self.opt.state)
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/learner.py in <listcomp>(.0)
134 def _call_one(self, event_name):
135 assert hasattr(event, event_name), event_name
--> 136 [cb(event_name) for cb in sort_by_run(self.cbs)]
137
138 def _bn_bias_state(self, with_bias): return norm_bias_params(self.model, with_bias).map(self.opt.state)
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/callback/core.py in __call__(self, event_name)
42 (self.run_valid and not getattr(self, 'training', False)))
43 res = None
---> 44 if self.run and _run: res = getattr(self, event_name, noop)()
45 if event_name=='after_fit': self.run=True #Reset self.run to True at each end of fit
46 return res
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/learner.py in after_batch(self)
455 if len(self.yb) == 0: return
456 mets = self._train_mets if self.training else self._valid_mets
--> 457 for met in mets: met.accumulate(self.learn)
458 if not self.training: return
459 self.lrs.append(self.opt.hypers[-1]['lr'])
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/learner.py in accumulate(self, learn)
404 def accumulate(self, learn):
405 self.count += 1
--> 406 self.val = torch.lerp(to_detach(learn.loss.mean(), gather=False), self.val, self.beta)
407 @property
408 def value(self): return self.val/(1-self.beta**self.count)
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/torch_core.py in __torch_function__(self, func, types, args, kwargs)
317 # if func.__name__[0]!='_': print(func, types, args, kwargs)
318 # with torch._C.DisableTorchFunction(): ret = _convert(func(*args, **(kwargs or {})), self.__class__)
--> 319 ret = super().__torch_function__(func, types, args=args, kwargs=kwargs)
320 if isinstance(ret, TensorBase): ret.set_meta(self, as_copy=True)
321 return ret
~/anaconda3/envs/fastai/lib/python3.7/site-packages/torch/tensor.py in __torch_function__(cls, func, types, args, kwargs)
960
961 with _C.DisableTorchFunction():
--> 962 ret = func(*args, **kwargs)
963 return _convert(ret, cls)
964
RuntimeError: CUDA error: device-side assert triggered
Snooping around the forum I found several references to similar (at least I guess) issues as in [1], [2], [3] but I still don’t get how to fix it. My understanding is that the problem is caused by the loader that reads the binary masks in [0, 255] format instead of [0, 1]. What I tried was:
- pre-process the masks (divide by 255 as I only have 1 class)
- save them with the correct [0, 1] format
but when I read them with the dataloader they are still in [0, 255] format.
I also went through other suggested hacks but I didn’t manage to make them work (maybe they were outdated or I’m simply not good enough at coding  ).
).
So my question is: as of today, what is the correct way to build a data loader for a segmentation task?
Thanks in advance and sorry for the long post!