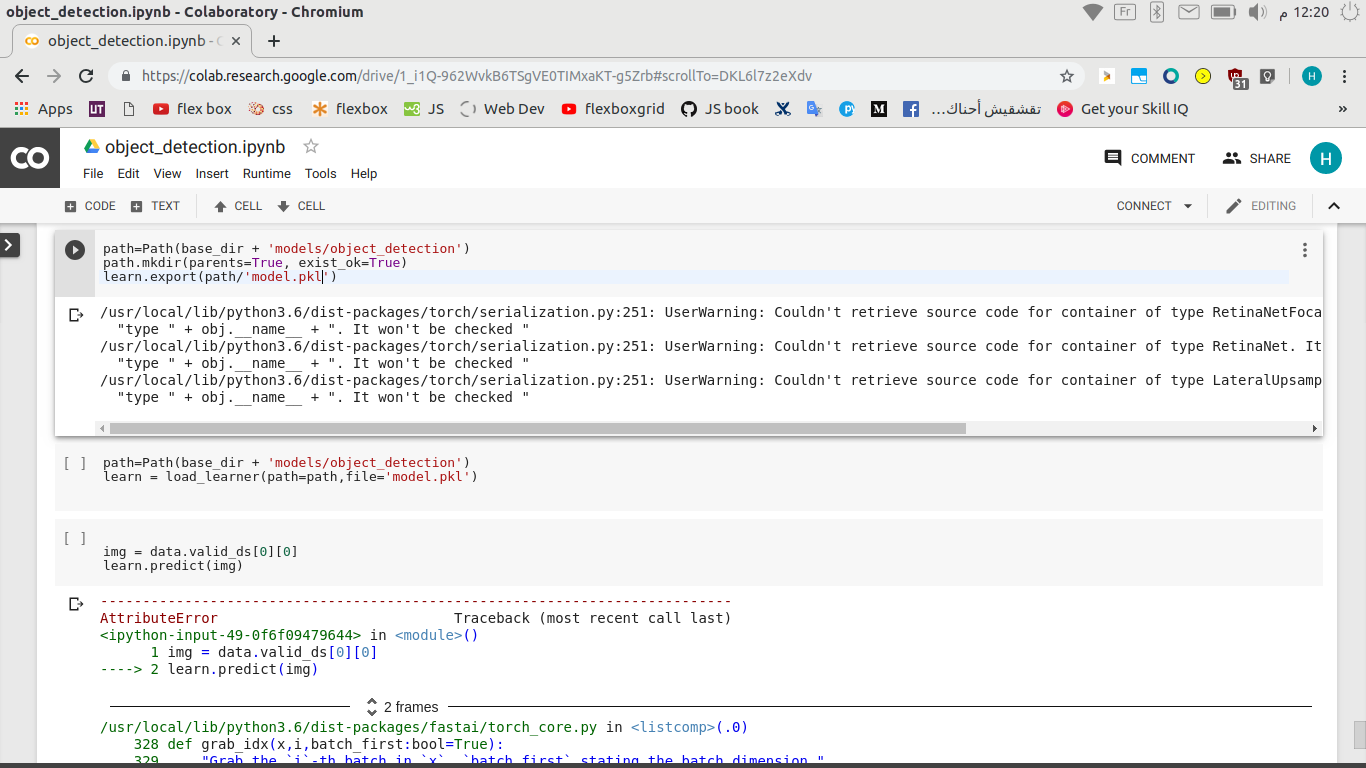
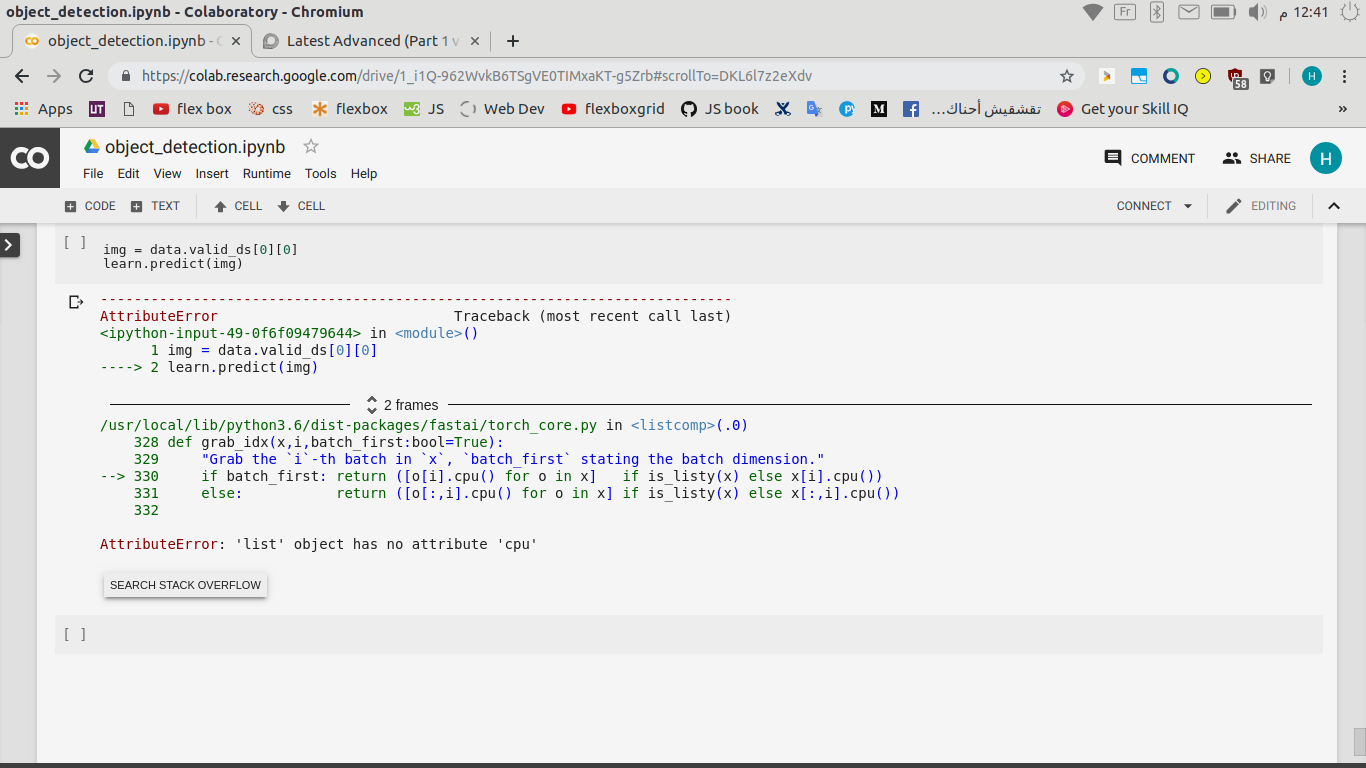
I have tried doing transfer learning for my model when I try to load the previously model for my new data, it gives me this error:
/usr/local/lib/python3.7/dist-packages/fastai/basic_train.py in load(self, file, device, strict, with_opt, purge, remove_module)
271 model_state = state['model']
272 if remove_module: model_state = remove_module_load(model_state)
--> 273 get_model(self.model).load_state_dict(model_state, strict=strict)
274 if ifnone(with_opt,True):
275 if not hasattr(self, 'opt'): self.create_opt(defaults.lr, self.wd)
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in load_state_dict(self, state_dict, strict)
1496 if len(error_msgs) > 0:
1497 raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
-> 1498 self.__class__.__name__, "\n\t".join(error_msgs)))
1499 return _IncompatibleKeys(missing_keys, unexpected_keys)
1500
RuntimeError: Error(s) in loading state_dict for RetinaNet:
size mismatch for classifier.3.weight: copying a param with shape torch.Size([3, 128, 3, 3]) from checkpoint, the shape in current model is torch.Size([2, 128, 3, 3]).
size mismatch for classifier.3.bias: copying a param with shape torch.Size([3]) from checkpoint, the shape in current model is torch.Size([2]).
The images in data loader are not binary they are 3 channel images, but still the learn. load throws this error. The new data has 2 slide images whereas the model was trained on 100 slides. I have loaded the new data like this:
batch_size=20
do_flip = True
flip_vert = True
max_rotate = 90
max_zoom = 1.1
max_lighting = 0.2
max_warp = 0.2
p_affine = 0.75
p_lighting = 0.75
tfms = get_transforms(do_flip=do_flip,
flip_vert=flip_vert,
max_rotate=max_rotate,
max_zoom=max_zoom,
max_lighting=max_lighting,
max_warp=max_warp,
p_affine=p_affine,
p_lighting=p_lighting)
train, valid = ObjectItemListSlide(train_images) ,ObjectItemListSlide(valid_images)
item_list = ItemLists(".", train, valid)
lls = item_list.label_from_func(lambda x: x.y, label_cls=SlideObjectCategoryList)
lls = lls.transform(tfms, tfm_y=True, size=patch_size)
data = lls.databunch(bs=batch_size, collate_fn=bb_pad_collate,num_workers=0).normalize()
Does anyone know how one can solve this issue, what needs to be changed?