thanks for the tip. I just created an AWS SPOT instance asking for access to p3.2xlarge, p3.8xlarge and p3.16xlarge in the US West (Oregon) region using the Fastai AMI.
thanks for your help as I do not understand what AWS has in mind.
My first request about using an AWS p3 instance was on 04/15/2018. Let’s see how long it will take to get a final YES or NO.
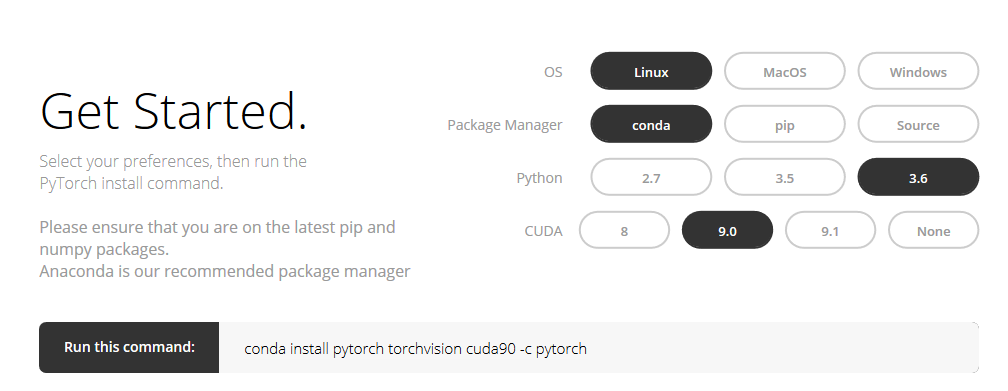
I guess since November 2017 (today is the 31st of May 2018), the https://pytorch.org/ site updated its package and then, we do not need anymore to install pytorch from source but we can use conda.
I just tried it on Amazon Web Services (AWS) p3.2xlarge and it worked
And I tested it on lesson1.ipynb : p3.2xlarge works 400% faster than p2.xlarge
Note : I did try as well to install cuda91 (conda install pytorch torchvision cuda91 -c pytorch), but it did not work (the lesson1 notebook did not detect cuda : torch.cuda.is_available() = False).
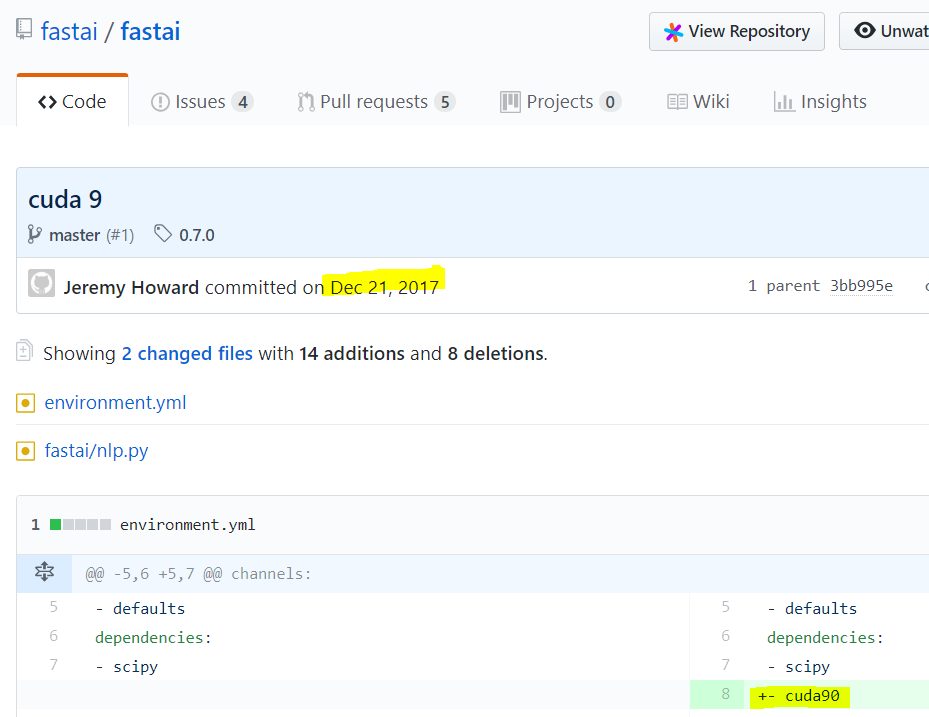
Thanks for the update. Per GitHub log, Jeremy updated the environment.yml on 21 Dec 2017 to cuda90. The fastai AMI should be ready to go since then. I don’t think you need to run extra conda commands.
Well on my side, I had to. Therefore, I understand what you say @Moody but I do not understand why I had to follow another path.
This is the path I followed :
After I launched my AWS p3.2xlarge instance, I did conda update --all, cd fastai, git pull, conda env update.
Then, I ran the lesson1 notebook, and got the following message after 8 minutes (note : my lesson1 notebook did run but slowly as it was Cuda 8 that was compiled as showed in the following message) :
/home/ubuntu/src/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/cuda/__init__.py:95: UserWarning:
Found GPU0 Tesla V100-SXM2-16GB which requires CUDA_VERSION >= 9000 for
optimal performance and fast startup time, but your PyTorch was compiled
with CUDA_VERSION 8000. Please install the correct PyTorch binary
using instructions from http://pytorch.org
warnings.warn(incorrect_binary_warn % (d, name, 9000, CUDA_VERSION))
Finally, I ran in my ssh Terminal to AWS the following 2 lines and then, my lesson1 did work correctly with Cuda 9 :
Note : I did try as well to install cuda91 (conda install pytorch torchvision cuda91 -c pytorch), but it did not work (the lesson1 notebook did not detect cuda : torch.cuda.is_available() = False).
Hi guys, I’ve noticed that P3 instances aren’t being used at full capacity when training on imagenet using pytorch main imagenet examples and also some of my own code. Although I do notice the 4x speedup over P2 instances as some others have noted, I do believe there is about an extra 2X left (for a total of 8X) speedup as running constant tensors through the GPU’s goes about twice as fast. I’ve spent a long time trying to profile whats going on, and I believe its an I/O issue on Amazon’s EBS volumes/instances, but I can’t seem to figure out what exactly is bottlenecking. I think the problem isn’t that big a deal on P2’s since the GPU is bottlenecking, but it becomes apparent for faster GPUs. Does anyone have ideas?
Sorry for the repeat post guys, but after looking into it a bit more - it seems to be half related to reading constraints, and half limited by the CPU power of the instance. If we crop to 1 pixel instead of 224, we can dramatically speed up (50+%) the training process. I think potentially the P3 instance might not be proportionally equipped CPU-wise to handle higher resolution image on-the-fly pre-processing ?
Hi ,
I was using p3 instances and looking at the amount of ram available I can fit the whole data into RAM. Will loading the whole dataset into ram be faster than loading the data in batches from ssd saving IO operations ?