The whole point of a deep learning model is that it can do feature engineering better than humans. That’s what it learns when you train it.
However, neural nets are also pretty dumb, so sometimes it makes sense to pass in additional features (for example, “coord conv” where you also pass in the coordinates of every pixel in the image).
RAW vs JPEGs only matters if the JPEG compression artifacts confuse your model. Loading JPEG files is typically faster than loading RAW images.
Original image size vs downscaled has an impact on speed and memory. Larger images may also require a deeper network. In general, larger images give better results, but they can also cause the model to pick up on unnecessary details. In that sense, downscaling actually is a type of feature engineering (low-pass filtering).
I have a slightly different question. I want to deploy deep learning for digital pathology. (I hope it is ok to ask this question here.)
I am working with tiles that I generate within a digital pathology program from a tissue slide. I can create tiles (from tumor tissue) that always have the same size e.g. 150 µm. When I compare these generated tiles between different origin slides, the output dimensions of the files differ. From one slide I generate tiles with 306x306 pixels, from another slide I generate tiles with 330x330 pixels and so on. The file format is tiff/".tif".
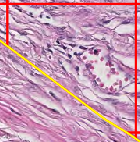
On the “surface” around the tumor I can also generate tiles that are “cut off” with various size where the tumor “ends”.
like this, yellow represents the various shape possible:
What would you recommend would be a good way to deal with these different dimensions? What happens if I would just load all these files into the same databunch in the fastai library for example?
I could probably get rid of the tiles with the various shapes (if necessary with some python programming), but I don’t know at the moment what to do regarding the different dimensions of the tiles between different slides. Are these different sizes going to decrease a deep learning model accuracy in comparison to a set of tiles that already have the same original dimensions?
In your example the size varies by around 10 percent only, so I assume you can safely use them for training. Use data augmentation (scaling) to even improve results