I am trying to replicate https://docs.fast.ai/tutorial.text
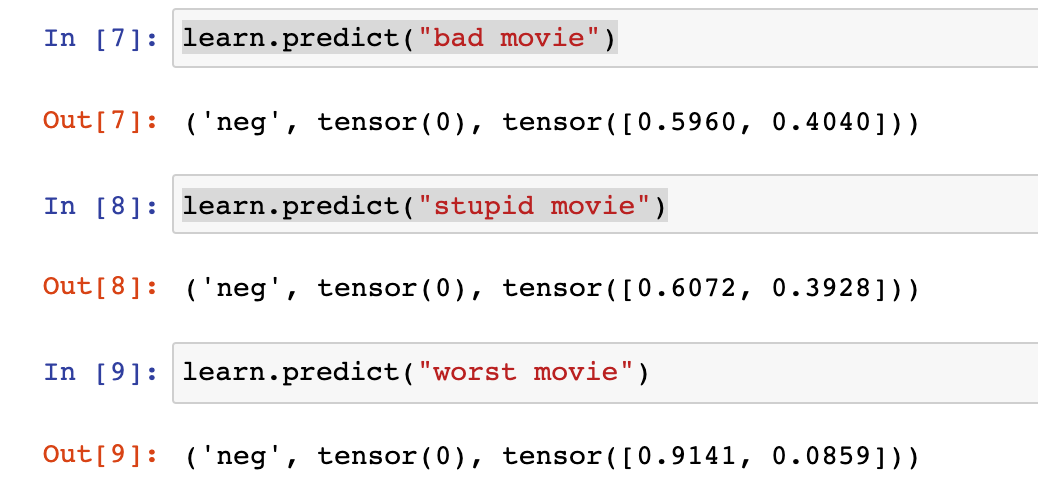
(This is not merely a “show batch issue” – I tried training on this, and got a model that returned “pos” on things like “bad movie” “terrible movie” …)
This is the code I am executing:
from fastai.text.all import *
dls = TextDataLoaders.from_folder(untar_data(URLs.IMDB), valid='test')
dls.show_batch()
This is my ouptut:
text category
0 xxbos xxmaj match 1 : xxmaj tag xxmaj team xxmaj table xxmaj match xxmaj bubba xxmaj ray and xxmaj spike xxmaj dudley vs xxmaj eddie xxmaj guerrero and xxmaj chris xxmaj benoit xxmaj bubba xxmaj ray and xxmaj spike xxmaj dudley started things off with a xxmaj tag xxmaj team xxmaj table xxmaj match against xxmaj eddie xxmaj guerrero and xxmaj chris xxmaj benoit . xxmaj according to the rules of the match , both opponents have to go through tables in order to get the win . xxmaj benoit and xxmaj guerrero heated up early on by taking turns hammering first xxmaj spike and then xxmaj bubba xxma... pos
1 xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xx... pos
2 xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xxpad xx... pos
This is my pip3 list
pip3 list
Package Version
------------------- ---------
argon2-cffi 20.1.0
astroid 1.6.6
async-generator 1.10
attrs 20.2.0
awscli 1.18.137
backcall 0.2.0
bleach 3.1.5
blis 0.4.1
bokeh 1.0.4
boto 2.49.0
boto3 1.14.60
botocore 1.17.60
catalogue 1.0.0
certifi 2020.6.20
cffi 1.14.2
chardet 3.0.4
cloudpickle 1.6.0
cmake 3.13.3
colorama 0.4.3
cpplint 1.3.0
cycler 0.10.0
cymem 2.0.3
Cython 0.28.2
dask 2.26.0
decorator 4.4.2
defusedxml 0.6.0
docutils 0.15.2
entrypoints 0.3
environment-kernels 1.1.1
fastai 2.0.13
fastcore 1.0.14
fastprogress 1.0.0
future 0.18.2
graphviz 0.10.1
idna 2.10
imageio 2.9.0
importlib-metadata 1.7.0
ipykernel 5.3.4
ipython 7.4.0
ipython-genutils 0.2.0
ipywidgets 7.5.1
isort 5.5.2
jedi 0.17.2
Jinja2 2.11.2
jmespath 0.10.0
json5 0.9.5
jsonschema 3.2.0
jupyter 1.0.0
jupyter-client 6.1.7
jupyter-console 6.2.0
jupyter-core 4.6.3
jupyterlab 2.2.8
jupyterlab-pygments 0.1.1
jupyterlab-server 1.2.0
kiwisolver 1.2.0
lazy-object-proxy 1.5.1
lxml 4.4.1
MarkupSafe 1.1.1
matplotlib 3.0.3
mccabe 0.6.1
mistune 0.8.4
murmurhash 1.0.2
nbclient 0.5.0
nbconvert 6.0.1
nbformat 5.0.7
nest-asyncio 1.4.0
networkx 2.5
notebook 6.1.4
numpy 1.15.4
nvidia-ml-py 10.418.84
opencv-python 3.4.5.20
packaging 20.4
pandas 0.24.2
pandocfilters 1.4.2
parso 0.7.1
pexpect 4.8.0
pickleshare 0.7.5
Pillow 7.2.0
Pillow-PIL 0.1.dev0
pip 20.2.3
plac 1.1.3
preshed 3.0.2
prometheus-client 0.8.0
prompt-toolkit 2.0.10
ptyprocess 0.6.0
pyasn1 0.4.8
pycparser 2.20
pygal 2.4.0
Pygments 2.6.1
pylint 1.9.4
pyparsing 2.4.7
pyrsistent 0.16.0
python-dateutil 2.8.1
pytz 2020.1
PyWavelets 1.1.1
PyYAML 5.3.1
pyzmq 19.0.2
qtconsole 4.7.7
QtPy 1.9.0
requests 2.24.0
rsa 4.5
s3transfer 0.3.3
scikit-image 0.15.0
scikit-learn 0.20.2
scipy 1.4.1
Send2Trash 1.5.0
setuptools 38.4.0
simplegeneric 0.8.1
six 1.15.0
spacy 2.3.2
srsly 1.0.2
terminado 0.8.3
testpath 0.4.4
thinc 7.4.1
toolz 0.10.0
torch 1.6.0
torchvision 0.7.0
tornado 6.0.4
tqdm 4.49.0
traitlets 5.0.4
urllib3 1.25.10
wasabi 0.8.0
wcwidth 0.2.5
webencodings 0.5.1
wheel 0.32.3
widgetsnbextension 3.5.1
wrapt 1.12.1
zipp 3.1.0