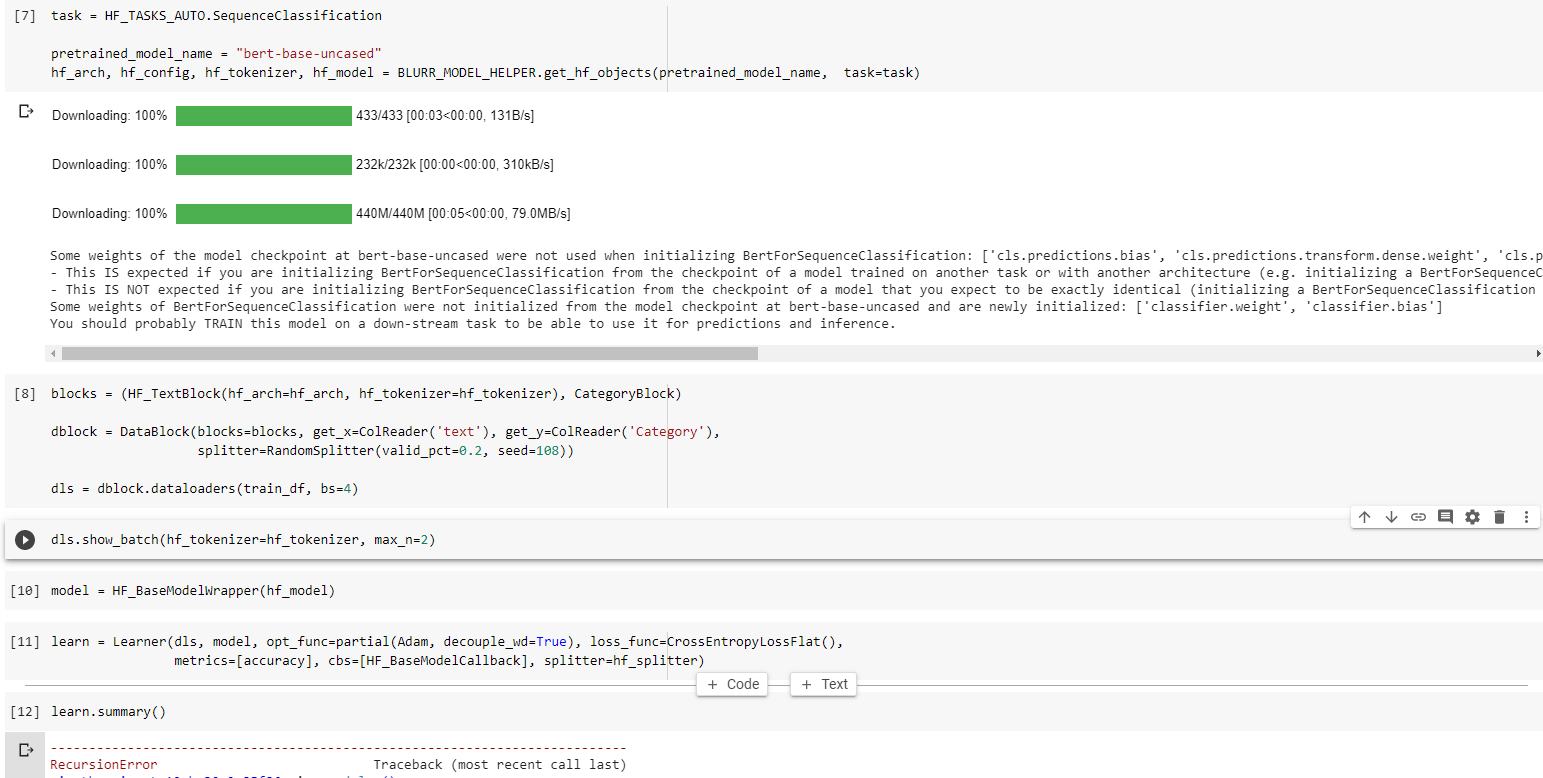
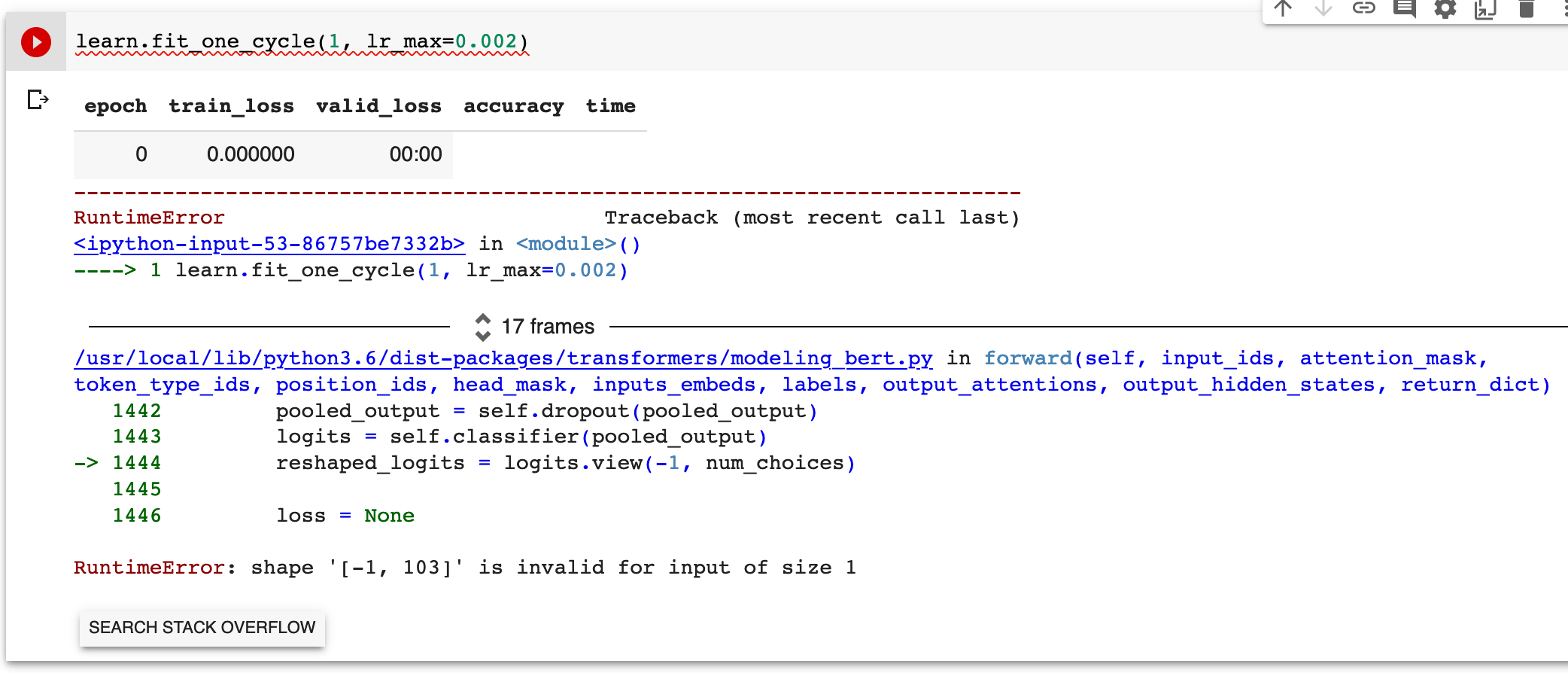
Hello wgpubs. A big compliment for your library. You make it really easy to use one of the HF models.
Sequence Classification with only 2 labels works for me. However, if I have more than 2 labels the lr.find / lr.fit are not working anymore.
I’ve tried to specify config.num_labels = len(labels.unique) in my case 5 labels, but this doesn’t work. Do I have to specify the labels somewhere else?
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-229-ad38bd08516f> in <module>
1 #slow
----> 2 learn.lr_find(suggestions=True)
/home/shared/blurr/fastai2/fastai2/callback/schedule.py in lr_find(self, start_lr, end_lr, num_it, stop_div, show_plot, suggestions)
226 n_epoch = num_it//len(self.dls.train) + 1
227 cb=LRFinder(start_lr=start_lr, end_lr=end_lr, num_it=num_it, stop_div=stop_div)
--> 228 with self.no_logging(): self.fit(n_epoch, cbs=cb)
229 if show_plot: self.recorder.plot_lr_find()
230 if suggestions:
/home/shared/blurr/fastai2/fastcore/fastcore/utils.py in _f(*args, **kwargs)
429 init_args.update(log)
430 setattr(inst, 'init_args', init_args)
--> 431 return inst if to_return else f(*args, **kwargs)
432 return _f
433
/home/shared/blurr/fastai2/fastai2/learner.py in fit(self, n_epoch, lr, wd, cbs, reset_opt)
201 try:
202 self.epoch=epoch; self('begin_epoch')
--> 203 self._do_epoch_train()
204 self._do_epoch_validate()
205 except CancelEpochException: self('after_cancel_epoch')
/home/shared/blurr/fastai2/fastai2/learner.py in _do_epoch_train(self)
173 try:
174 self.dl = self.dls.train; self('begin_train')
--> 175 self.all_batches()
176 except CancelTrainException: self('after_cancel_train')
177 finally: self('after_train')
/home/shared/blurr/fastai2/fastai2/learner.py in all_batches(self)
151 def all_batches(self):
152 self.n_iter = len(self.dl)
--> 153 for o in enumerate(self.dl): self.one_batch(*o)
154
155 def one_batch(self, i, b):
/home/shared/blurr/fastai2/fastai2/learner.py in one_batch(self, i, b)
159 self.pred = self.model(*self.xb); self('after_pred')
160 if len(self.yb) == 0: return
--> 161 self.loss = self.loss_func(self.pred, *self.yb); self('after_loss')
162 if not self.training: return
163 self.loss.backward(); self('after_backward')
/home/shared/blurr/fastai2/fastai2/layers.py in __call__(self, inp, targ, **kwargs)
292 if targ.dtype in [torch.int8, torch.int16, torch.int32]: targ = targ.long()
293 if self.flatten: inp = inp.view(-1,inp.shape[-1]) if self.is_2d else inp.view(-1)
--> 294 return self.func.__call__(inp, targ.view(-1) if self.flatten else targ, **kwargs)
295
296 # Cell
/home/shared/conda/fastai2/lib/python3.6/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
530 result = self._slow_forward(*input, **kwargs)
531 else:
--> 532 result = self.forward(*input, **kwargs)
533 for hook in self._forward_hooks.values():
534 hook_result = hook(self, input, result)
/home/shared/conda/fastai2/lib/python3.6/site-packages/torch/nn/modules/loss.py in forward(self, input, target)
914 def forward(self, input, target):
915 return F.cross_entropy(input, target, weight=self.weight,
--> 916 ignore_index=self.ignore_index, reduction=self.reduction)
917
918
/home/shared/conda/fastai2/lib/python3.6/site-packages/torch/nn/functional.py in cross_entropy(input, target, weight, size_average, ignore_index, reduce, reduction)
2019 if size_average is not None or reduce is not None:
2020 reduction = _Reduction.legacy_get_string(size_average, reduce)
-> 2021 return nll_loss(log_softmax(input, 1), target, weight, None, ignore_index, None, reduction)
2022
2023
/home/shared/conda/fastai2/lib/python3.6/site-packages/torch/nn/functional.py in nll_loss(input, target, weight, size_average, ignore_index, reduce, reduction)
1836 .format(input.size(0), target.size(0)))
1837 if dim == 2:
-> 1838 ret = torch._C._nn.nll_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index)
1839 elif dim == 4:
1840 ret = torch._C._nn.nll_loss2d(input, target, weight, _Reduction.get_enum(reduction), ignore_index)
IndexError: Target 2 is out of bounds.