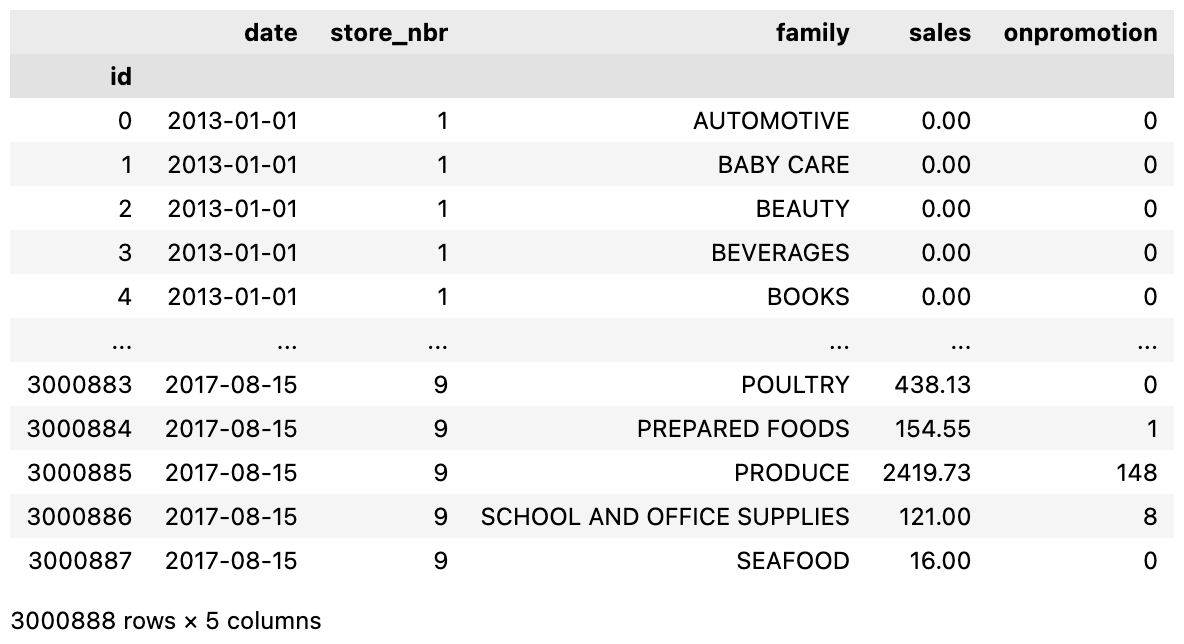
I have a DataFrame, df, which contains a 'date' column among other columns. Rows contain values of 'date' where are not necessarily unique. df is of length 3000888.
df
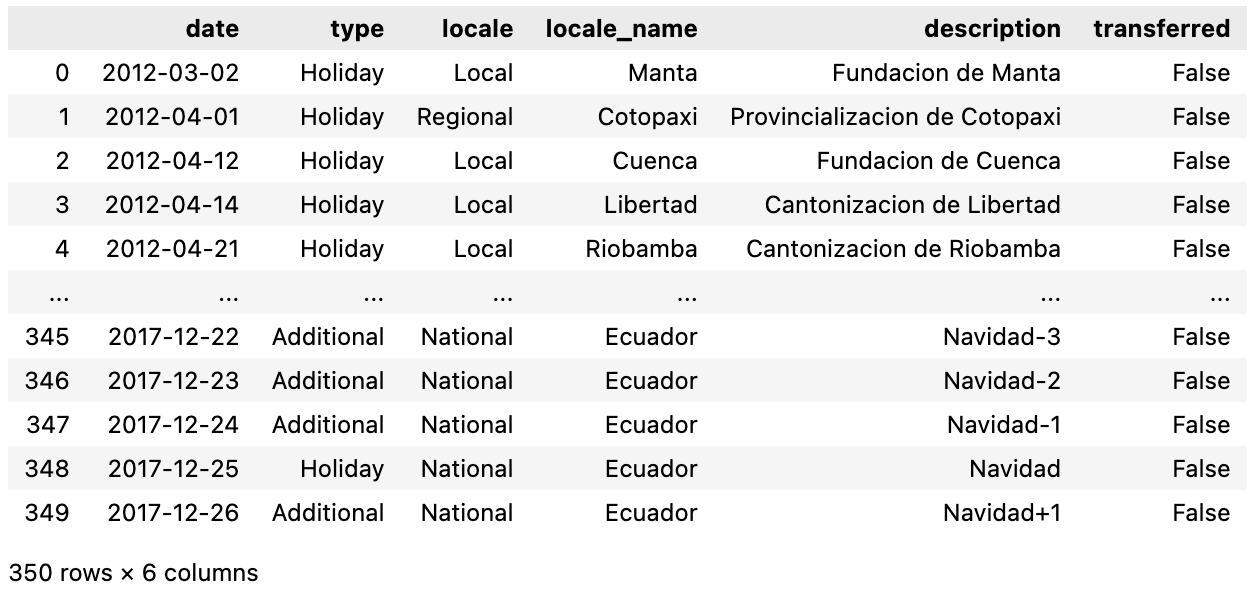
I have another DataFrame, hldys, which also contains a 'date' column among other columns. Rows contain values of 'date' which are unique. hldys is of length 350.
hldys
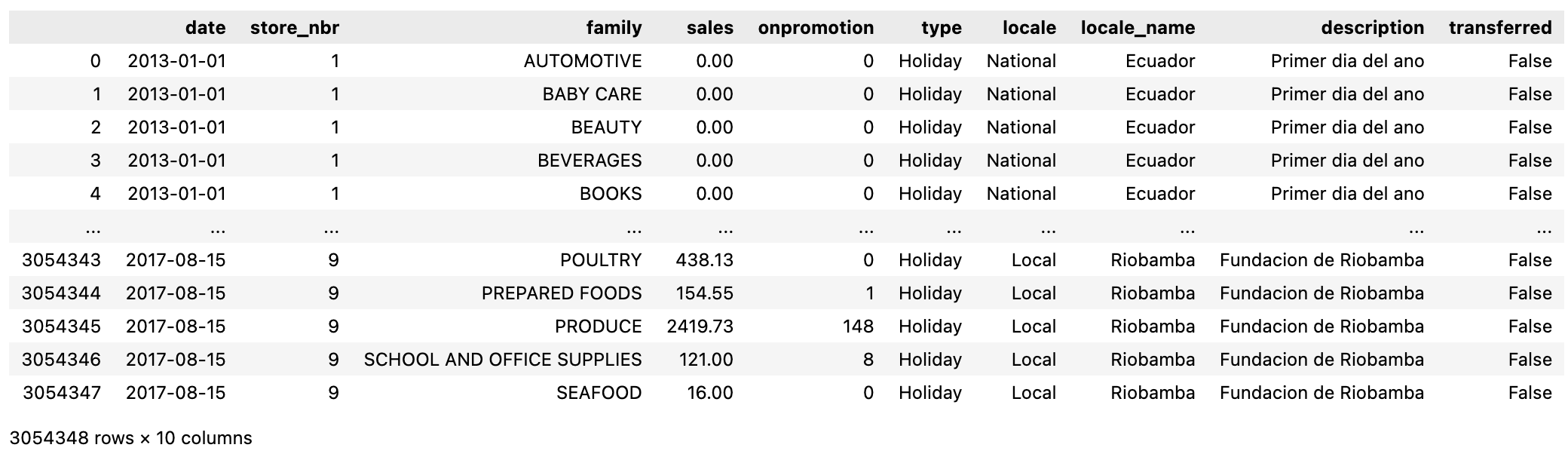
I want to merge hldys to df by 'date'.
df.merge(hldys.loc[hldys['date'].isin(df['date'])], how='left', on='date')
The line above also removes the extra dates in hldys that are not in df.
The result of the operation is a DataFrame that has a longer length than df: 3054348 entries.
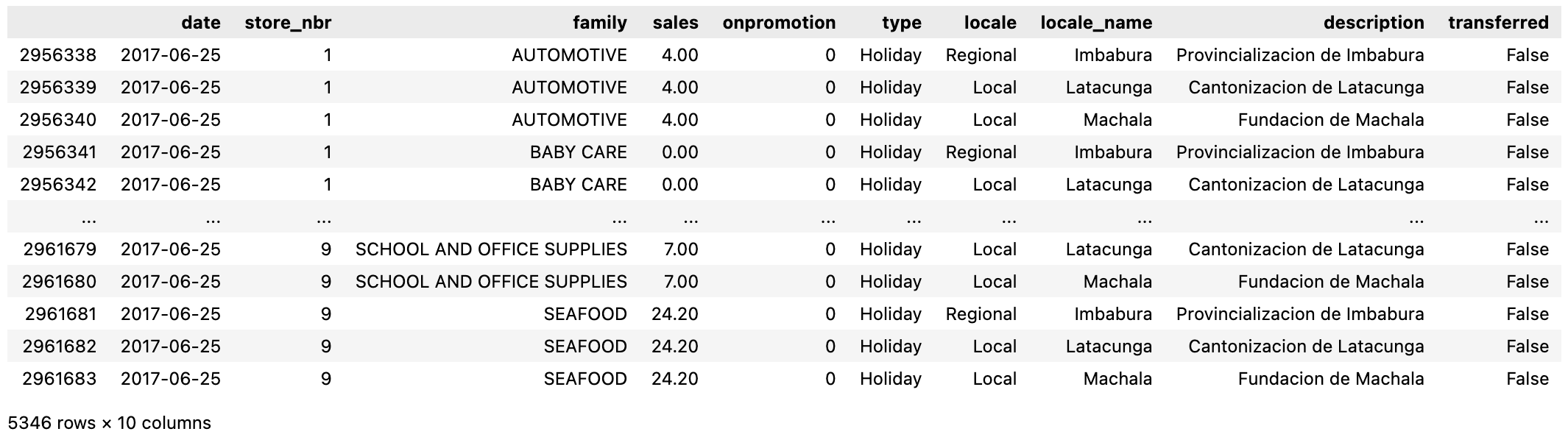
After some investigation, I figured out why the resulting DataFrame was longer: hldys contains dates where multiple holidays occured on the same day — so hldys does not contain unique dates.
hldys['date'].value_counts()
2014-06-25 4
2017-06-25 3
2016-06-25 3
2015-06-25 3
2013-06-25 3
..
2014-07-13 1
2014-07-12 1
2014-07-09 1
2014-07-08 1
2017-12-26 1
Name: date, Length: 312, dtype: int64
For example, on 2017-06-25, these three holidays occured:

So the merge operation above duplicated those rows in df where multiple holidays occurred on the same day, with the holiday information being the only piece of information differing between those duplicated rows.
So my question is, do I keep all these extra “duplicated” rows?
Would the model treat these extra rows as different sales records, which isn’t the case here, or would the model recognize that these are indeed the same sales records, and that they are duplicated only to show that different holidays occured on the same day?
The goal of the model is to predict the 'sales' column in df.