What is the fastai version that you are using ?
got around with that one but now got another issue on google colab,
When fitting resnet 34 got this issue,
/usr/local/lib/python3.6/dist-packages/torch/utils/data/dataloader.py in handler(signum, frame)
272 # This following call uses `waitid` with WNOHANG from C side. Therefore,
273 # Python can still get and update the process status successfully.
--> 274 _error_if_any_worker_fails()
275 if previous_handler is not None:
276 previous_handler(signum, frame)
RuntimeError: DataLoader worker (pid 236) is killed by signal: Bus error.
it seems to me colab is crashing
Another issue with colab…There is a github issue open on it too. Workaround is to set num_workers=0 while defining DataBunch i.e.
data = ImageDataBunch.from_name_re(path_img, fnames, pat,size=224, ds_tfms=get_transforms(flip_vert=False),num_workers=0)
Maybe because of fastai version is not 1.0.11?
anyone trying a fastai v1 install on windows 10? im trying pytorch preview build from source but unsuccessful so far.
PyTorch 1.0 on Windows is a work in progress.
I don’t recommend spending time on it. I tried this myself yesterday, and after consulting knowledgeable folks (i.e., people whose day job is to make this work), I have decided to stick with Linux for the duration of this course.
1 Like
alright, thanks. i will do the Ubuntu 16.04 LTS then.
Followed all the steps on ubuntu 18.04 and all went smooth. Thanks.
But something to note i get an output of 1 on running
python -c ‘import torch; print(torch.cuda.device_count());’
I’ve added this to the topic -
Please update before running and if you still need help, please share the details so that we can help debug.
This happened to me as well. When I ran python -c 'import fastai; fastai.show_install(0)' there seemed to be some issue with torch detecting my GPU. Realized it was possibly either due to running all of this in old environment / jupyter version running on different environment (or with old packages). I have also realized that I was running the whole setup on old 390 drivers (which is not the case with you).
I have then updated drivers to 410 version, reinstalled every package again in a fresh environment (everything including pytorch-nightly, cuda and others listed in main README of the repo) and made sure torch is working with cuda and cudnn.
torch.cuda.is_available() and torch.backends.cudnn.enabled both should return True when run in the notebook. This time the notebook ran fine without any errors.
Here is my current output for the working config:
=== Software ===
python version : 3.6.6
fastai version : 1.0.14
torch version : 1.0.0.dev20181027
nvidia driver : 410.66
torch cuda ver : 9.2.148
torch cuda is : available
torch cudnn ver : 7104
torch cudnn is : enabled
=== Hardware ===
nvidia gpus : 1
torch available : 1
- gpu0 : 11175MB | GeForce GTX 1080 Ti
=== Environment ===
platform : Linux-4.18.0-10-generic-x86_64-with-debian-buster-sid
distro : #11-Ubuntu SMP Thu Oct 11 15:13:55 UTC 2018
conda env : fastai
python : /home/bharadwaj/anaconda3/envs/fastai/bin/python
sys.path :
/home/bharadwaj/anaconda3/envs/fastai/lib/python36.zip
/home/bharadwaj/anaconda3/envs/fastai/lib/python3.6
/home/bharadwaj/anaconda3/envs/fastai/lib/python3.6/lib-dynload
/home/bharadwaj/anaconda3/envs/fastai/lib/python3.6/site-packages
/home/bharadwaj/anaconda3/envs/fastai/lib/python3.6/site-packages/IPython/extensions
Thank you for this useful thread! Your screenshot for AWS setup shows the AMI named “Deep Learning AMI (Ubuntu) Version 15.0” and the official fast.ai AWS EC2 course material references 16.0, but when I am setting up my machine I have the option for 17.0. For this 2018 USF Course, should I use 16.0 or should we always use the “latest and greatest” at the time of setup?
Hi all,
I’m new to Python frameworks and services but have had no trouble so far making a local ubuntu 18 installation which has worked just fine. But while installing Starlette for lesson 2 I ran into trouble installing the ASGI server uvicorn with the following error:
conda install -c conda-forge uvicorn
Solving environment: failed
UnsatisfiableError: The following specifications were found to be in conflict:
- pytorch-nightly -> *[track_features=cuda92]
- uvicorn
Use "conda info <package>" to see the dependencies for each package.
But conda info gave no information on either package. Grateful for any tips on where to start looking for a solution.
Is it possible to use pip to install in combination with conda or should I keep to just the one?
@jeremy Is there an AWS code to access the AWS credit for folks who attend in person(I do)?
This is a good and clean set of instructions. Thank you!
1 Like
So this was my second time trying to go through the course – first time using a raw paperspace instance and the second time with gradient. I was getting consistently tired of messing with remote compute instances while also trying to… learn… deep learning. I needed a new machine anyways, and it was blackfriday so I got a new laptop with a 1070 (hopefully 8gig vram doesn’t hobble me) that is beefy enough to crank through normal ML loads via cpu as well. Took a little while to do, but this thread let me get everything up and running 
GPU load confirms everything is working right
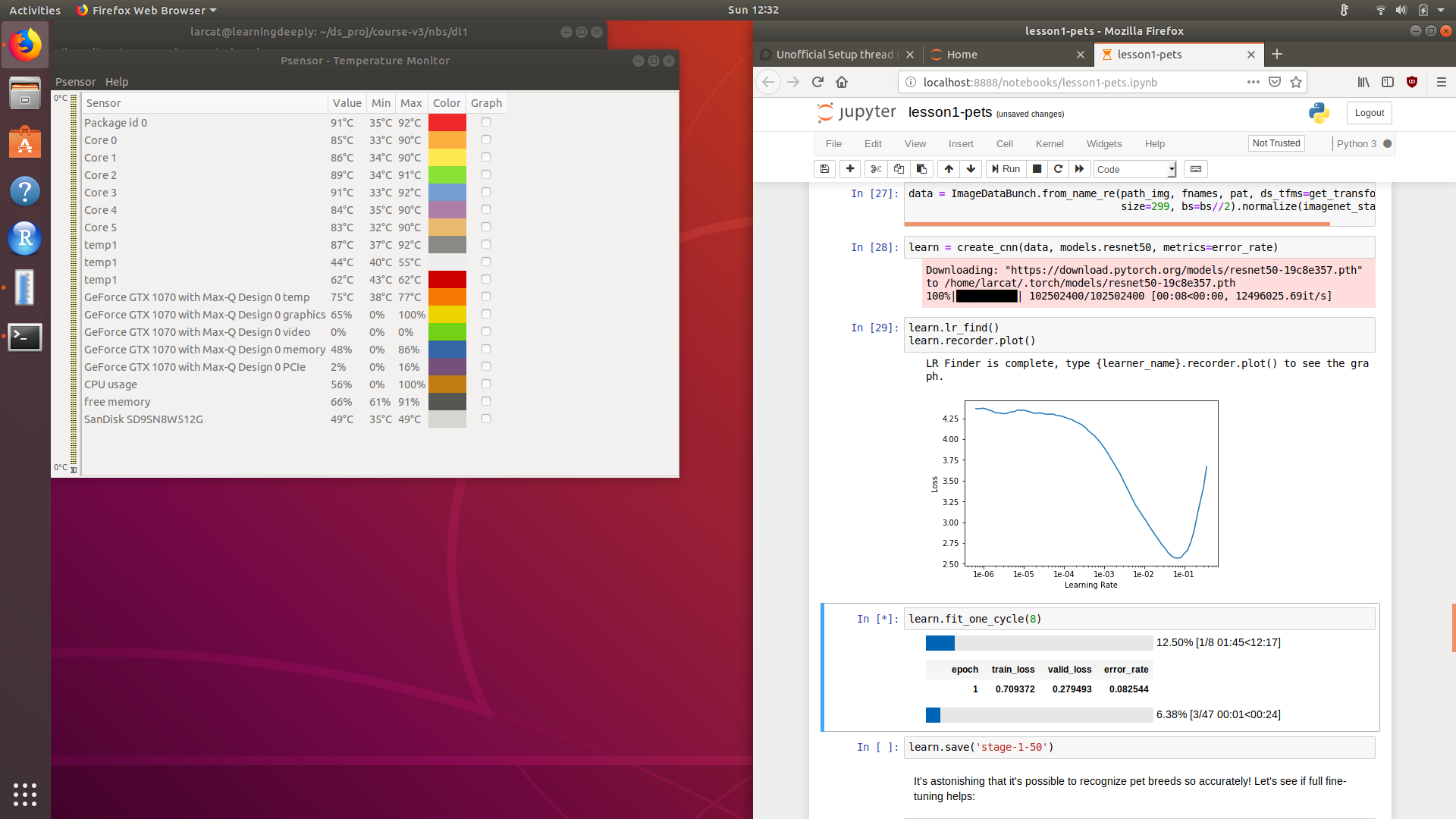
For some context on performance – this is the 8 epoch cell in the first notebook on resnet-50. GPU is a 1070 max-q.
Resnet50 fine tuning cell resulted in blackscreen first time I tried to run it (just banging through everything) – backed off on my undervolt to -.175 instead of -.185 and it ran fine. Everything is maxxed when doing this – all 6 cores and the 1070.
Tried doing this and I’m getting errors. Would be great to see instructions for those who had set up a p2.xlarge on AWS for the v2 version of the course and just want to clone the v3 repo onto this existing AMI. Since AWS permits only one p2.xlarge instance at a time, we will have to terminate the existing instance (and risk losing nbs with work) before signing up for the latest DL AMI.
I am just starting to get my personal system setup for Part 1 (2019) and hit something that others may hit. Installing conda install -c pytorch pytorch-nightly cuda92 does install pytorch-nightly-1.0.0.dev20190127-py3.7_cuda9.0.176_cudnn7.4.1_0, but then when I did conda install -c pytorch torchvision that installed pytorch 0.4.1(!) over the 1.0 install. I found that I needed to --force_reinstall the first command to get 1.0 to show up for me. Hope this helps some others…
UPDATE: before doing what I suggest here see my post to Lesson 1 Discussion ✅