Don’t worry, we all started some day and had many questions (and still have many others ).
Exactly, my script generates data ready to use for learning. And also yes, these appear black, if the displayed value range is not adapted. There might be cases where it can cause problems, as I only used it with some data sets, which definitely do not cover the whole space of possible use cases. But I tried to test against cases I know and to guarantee that it works for these at least. That also means if you or any one else spots problems I am always happy to look into it and enhance the function to support a broader range of applications.
@ptrampert , have you seen a scenario where data augmentation has altered the entries of the mask drastically and containing values to be with in 0 and becomes difficult
What i am seeing is , suppose before augmentation (for the mask) have contained values {0,89,14} , post augmentation (say for random zoom) , it becomes {0,88,89,13,14}.
It is obvious, that image transformations will alter discrete int values to floats and then casts these back to int. That means, you have to add an additional step that casts the transformed values back to known values.
Hi @ptrampert sorry for delay replying. I was stuck offline for several days due to travel.
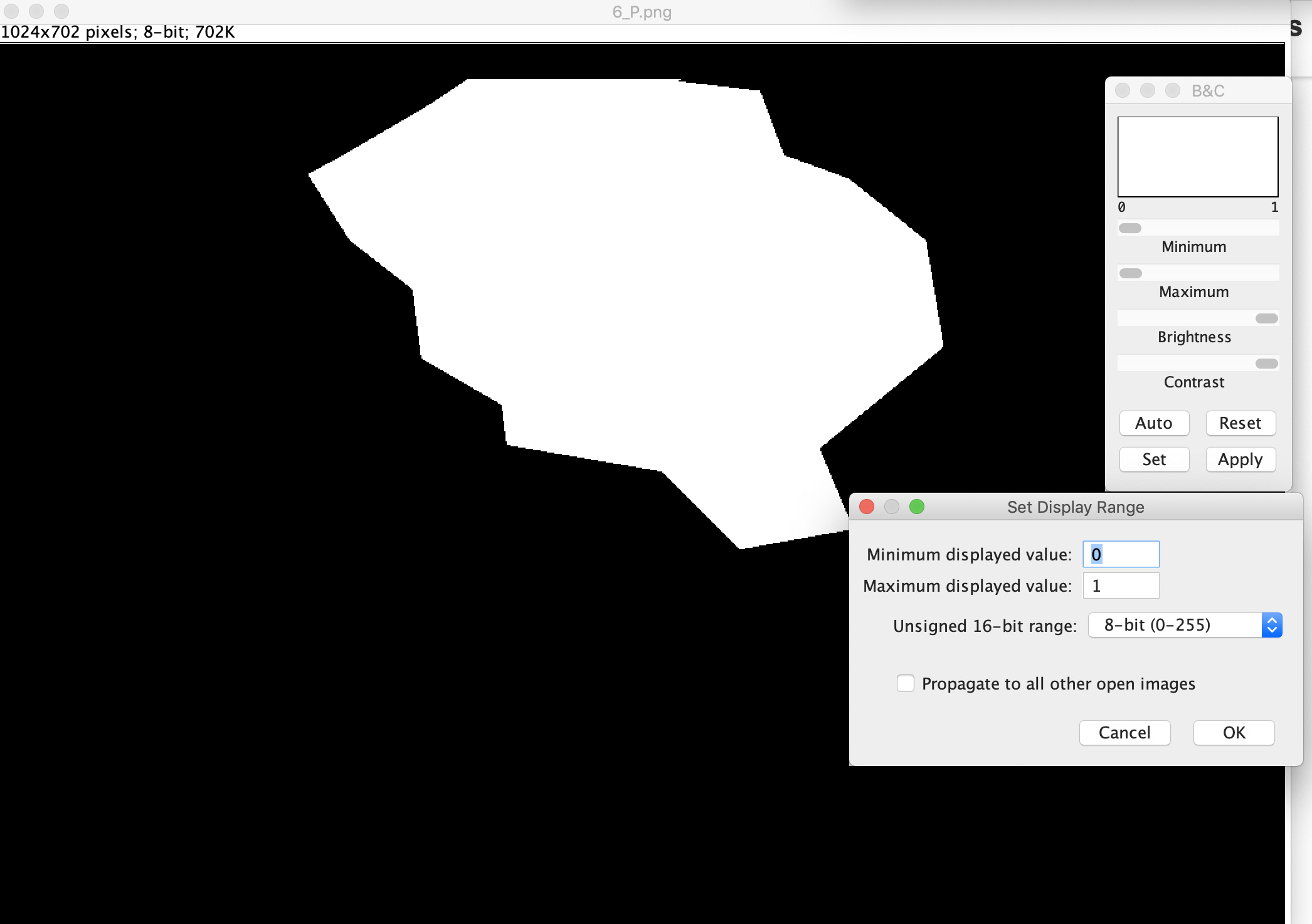
Ok, so as asuggested i have looked into the post-processed images after application of your function (and re-saving as png as your script saves to Tiff).
The masks in the image seem to still have this blue on blue which i’m not sure is a problem as the above looks to be correct and this could be a result of me using binary segmentation rather than multiclass.
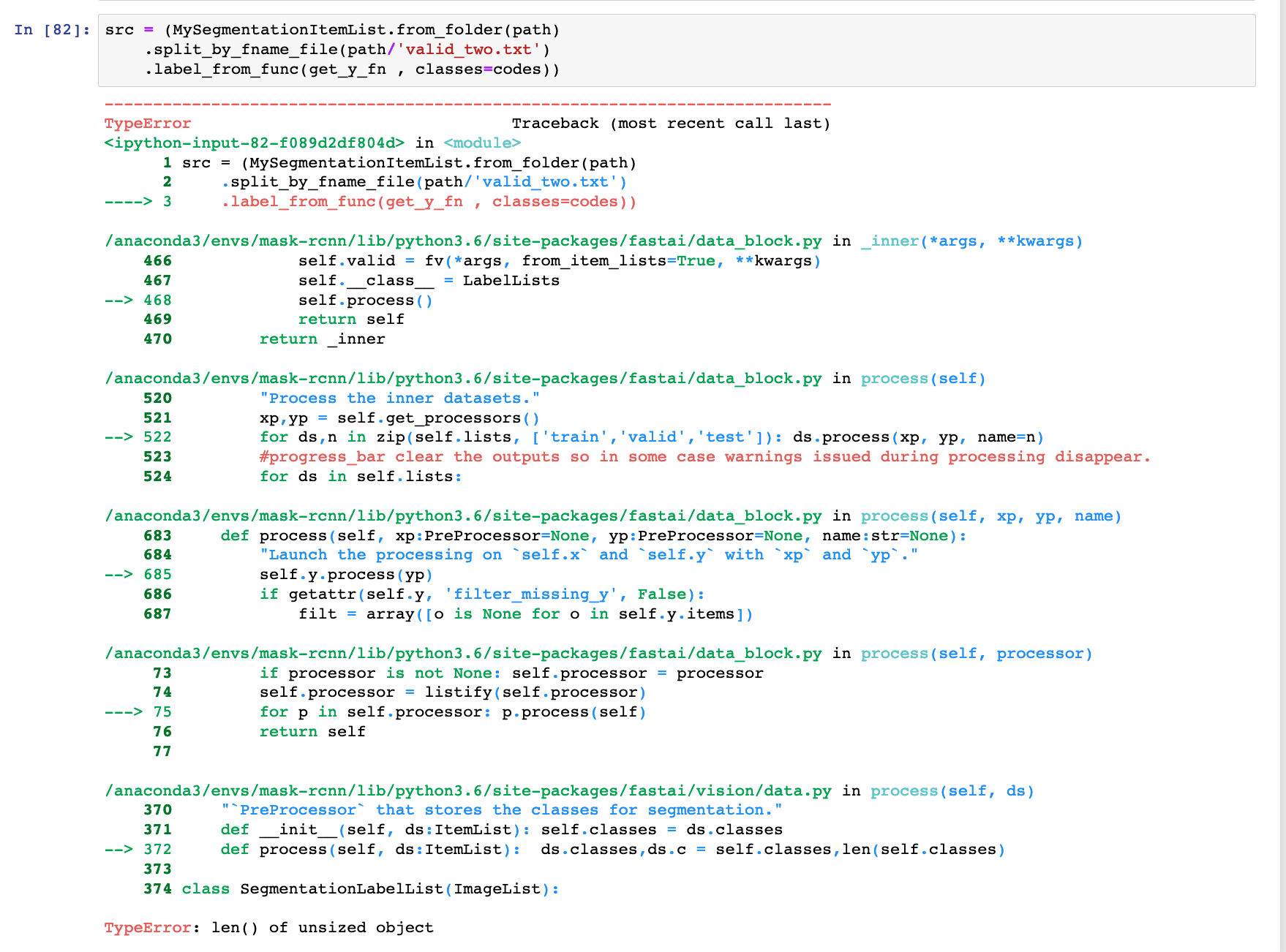
however when i come to the next part of the notebook im hitting this error below. I cross checked this against using the original camvid dataset and this does not happpen with that dataset which suggests it’s something unique to the way i have built my dataset? Any advice would be much appreciated!
Never seen this error before. Do you have the option to put the code and at least 10 or so of the images and masks (including the directory hierarchy as it is) into a github?
I will DM you now to get contact details to give you access? Edit: just realised i can just make it public! Give me about 30 minutes and i will ping you when its done.
You can find the notebook here with data in a zip folder.
The code is slightly edited from lesson 3s notebook. I am wondering if it also could be something to do with the fact camvid is multiclass and this is something to do with codes.txt. I was under the impression the class defined and using div=TRUE should help with this.
The data containts:
images_two: original images from open source data
masks: generated using rectlabel
binary_tiffs: masks imported to imageJ, made binary and exported to tiff
processed_tiffs: tiffs ran through processing code
labels_two: tiffs with extension renamed PNG to fit in with code and camvid style dataset
codes.txt: labelling format like camvid (although here is binary rather than multiple classes)
valid_two.txt: validation examples like camvid style
I will have a look as soon as I find some time this week.
Regarding your infos: You should use div=False if you use my script. It is set to true only if you have binary data with labels 0 and 255, then these will become 0 and 1.
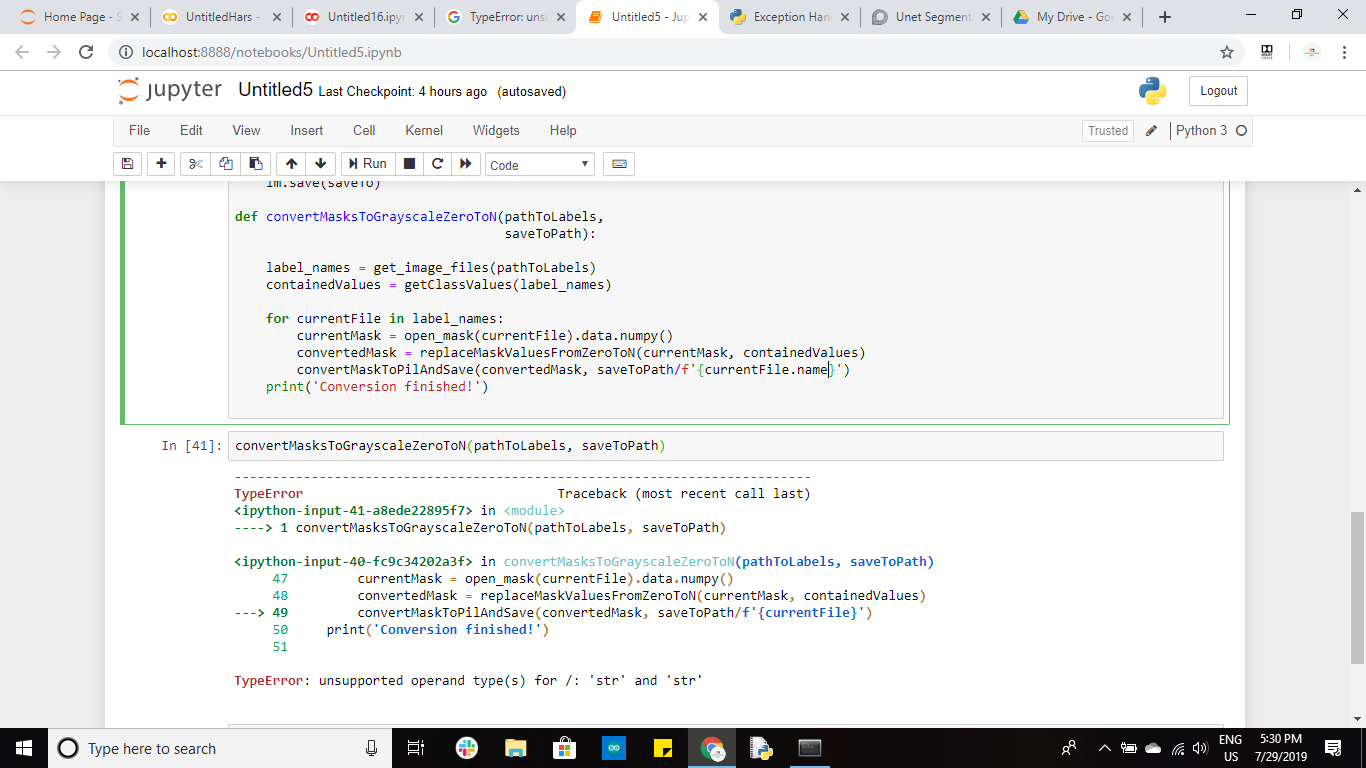
Ok great feedback @ptrampert - this seems to resolve the len() unsized object error, however there are some downstream effects when it coems to loading the databunch.
Should i also be setting tfm_y to = False here because we don’t want the transformations applied? Also do i need to forgo the normalisation ?
data = (src.transform(get_transforms(), size=size, tfm_y=True)
.databunch(bs=bs)
.normalize(imagenet_stats))
Any thoughts , ideas around how to make the UNET segmentation inference run faster in CPU. Currently i can see that learn.predict to create the probability mask is taken longer.
The important part here is “convert_mode”. “RGB” is the default. For gray scale images this means it just copies the values of an image to each channel and works on them as they were RGB. This way you can use pre-trained ImageNet from a statistical and dimensional point of view. However, this does not always work meaningfully, especially for medical images I have seen problems there. You have to basically test it.
The alternative is to set the value to “L”. Then you will work on single channel images, which also means you can’t use pre-trained ImageNet. Nevertheless, you should normalize the data with
.normalize()
This takes your data statistics for normalization and training starts with randomly initialized weights. Best use Xavier or Kaiming initialization. You can have a look here:
Regarding the tfm_y it depends. Imagine you rotate the image bi some degree, then you also want the mask to be rotated. So in general I recommend to set it to True. Only if you exactly know what you are doing and why, it can make sense to set it to False.
Out of interest, what exactly are you learning / doing? Is it for some project or a paper or something else?
@ptrampert im pretty much tinkering right now but there is definitely scope to get a paper out of this. It is for medicinal imaging. Happy to DM you some more information if your are interested? I’m also keen to play around with these segmentaiton models because from what i can see there is a lot to be done in terms of actually getting the data “ready” to train when you have a custom / unique dataset (which seems to be a recurring issue with these image neural networks in general). I have experience on the classification side with custom / unique datasets which is much more straightforward when it comes to training on your own dataset. Image segmentation feels like it opens up a bunch of powerful use cases but its definitely trickier to “get going”.
That error about unsupported operand type is (usually) from a mismatch of where it expects a pathlib object and has a string instead.
i.e. only pathlib supports that / auto-join functionality, not a str object.
Move the save to path argument into it’s own line and test that… and then once correct, pass the final object into the convertMaskToPilAndSave.
Hope that helps!
 ).
).