Image segmentation with Unet / ResNet. I generate a list of images and their attributes in a Pandas dataframe. The dataloader gets the images from there, I train the model on the training datasets, works well. I save the trained model to disk.
Once the model is trained, I load it in a completely different notebook and run predictions on a completely separate dataset. unet_learner.predict() works fine but it’s slow. I loop through all images, generate masks one by one, save masks to PNG files. No problems, except it takes a long time with 25k images.
To try unet_learner.get_preds(), I’ve built the dataloader like this:
If I don’t use save_preds() and capture the output from get_preds() in a variable, I run out of memory if I predict on more than about 200 images.
If I do use save_preds() it does not make the memory usage substantially less; in addition, it’s still pretty slow because it writes large, poorly compressed data structures to disk.
Is there any way to get fast batch predictions for image segmentation, when the dataset is large (25k images) and the output (prediction) is masks around the size 224x224 uint8?
Are you utilizing the GPU? load_learner loads the model for cpu by default, (if you do have a GPU available) try unet_learner = load_learner(path, cpu=False). Hope it’s that simple
According to what you set as flags (e.g. with_input, with_decoded, etc.) preds will be a tuple with length 1 (when everything is false and get_preds() returns only the n-channels one-hot encoded segmentation masks) or more. Be careful because it seems that with_decoded=True does a huge argmax across the whole batch of one-hot encoded masks so it turns out to be very very slow (I’m getting 2.5 seconds for a batch of 32 imgs @540x540 vs. 0.50 s with with_decoded=False)
Everything is already loaded into the GPU. Part of the problem was that I was using magnetic storage, which takes a long time to access many small image files. I’m testing to see whether SSD eliminates most of the speed issue.
The thing with with_decoded=True is that what I want to obtain is the predicted masks as image files. For that I would have to do argmax somewhere, no? I figured it’s faster if I do it in get_preds() but if there’s a better way I’m listening.
Switching to an SSD (preferably NVME) should dramatically improve the performance. It’s been a quite while, but I had to run inference on many 10’s of thousands of 256x256 images through a resnet34 based unet and I used get_preds with save_preds and then ran a post processing step using multiprocessing to convert the results to mask images. I think I was able to fully process somewhere in the order of 500-1,000 images per minute with a 3090 using fp16, 16c CPU and a NVME drive.
That would have been to easy
I think an SSD will have a great impact on load/save speed, nevertheless I would predict batch-wise and save the masks right away. save_preds pickles the data, which you then have to unpickle in order to save the image… I just think you can save yourself that step.
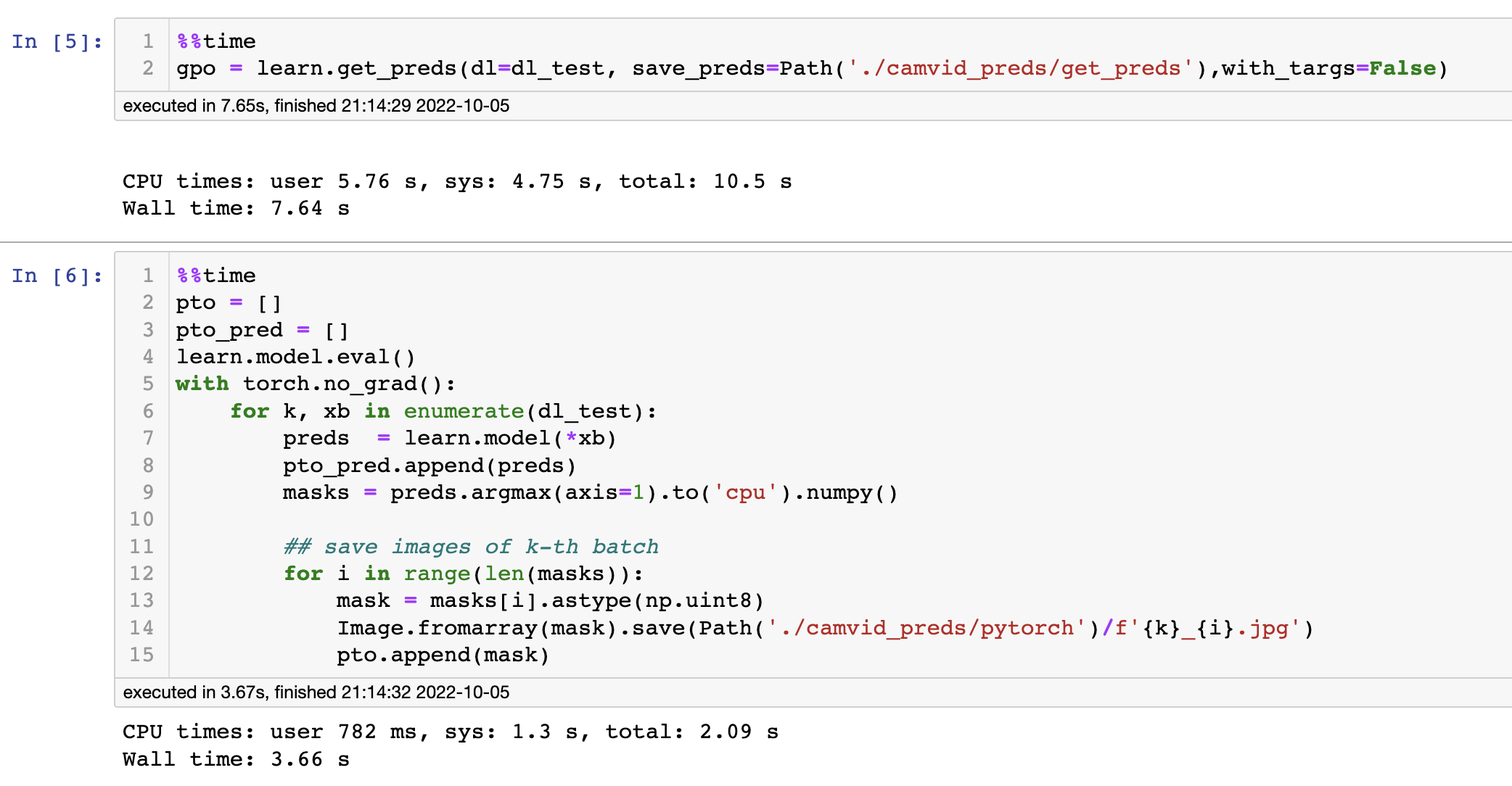
I made this quick comparison on CAMVID-TINY but I don’t see why it wouldn’t translate.
CPU times: user 12.9 s, sys: 3.24 s, total: 16.1 s
Wall time: 6.09 s
Predict and save manually:
%%time
learn.model.eval()
with torch.no_grad():
for k, xb in enumerate(big_dl):
preds = learn.model(*xb)
masks = preds.argmax(axis=-1).to('cpu').numpy()
## save images of k-th batch
for i in range(len(masks)):
mask = masks[i].astype(np.uint8)
Image.fromarray(mask).save(Path('tmp')/f'{k}_{i}.jpg')
CPU times: user 2.79 s, sys: 691 ms, total: 3.48 s
Wall time: 3.66 s
So (at least at least in that primitive example) a significant speedup .
Note that I used the bare minimum to predict the masks here. Make shure to check out @matdmiller 's post in your other thread to see what fastai usually does to receive the masks and what I’m missing here. (For example: I don’t know if the speedup against the no-save_preds case is a good sign )
Hope it helps!
I created a test using CAMVID (not tiny) as well with the images resized to 256x256. My results were similar - the pytorch prediction + saving was ~2x faster. I compared the raw predictions from each as well as the generated masks after applying argmax. The raw predictions are different, though not by a huge amount and the mask results were identical for the 192 images I tested with. It bugs me that the raw predictions are slightly different and I’m not sure why, but I believe this should give a pretty decent speedup for you and give you the results you’re after.