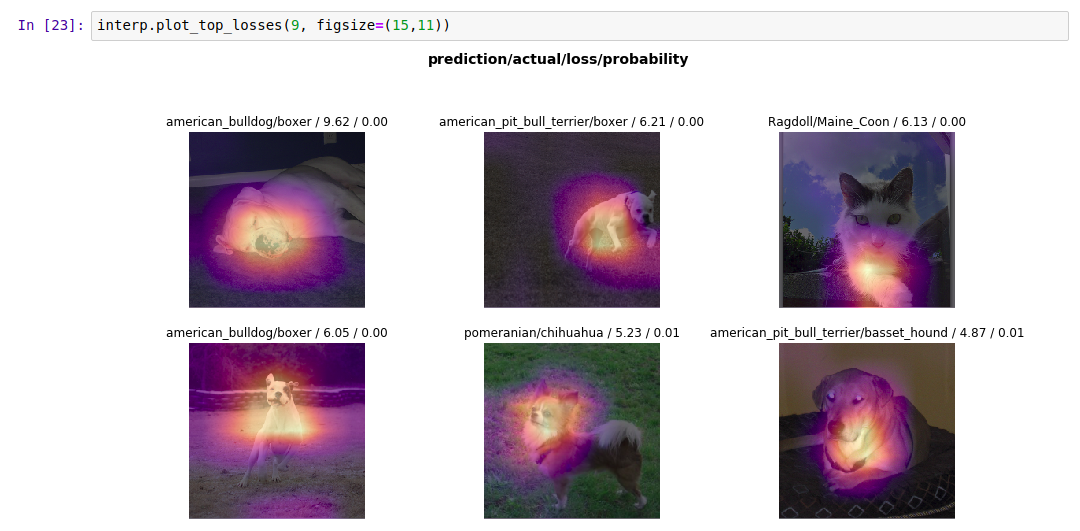
Just guessing, but could it be that ‘actual class’ is either concretely this or concretely that (0s or 1s), and hence does not involve probability (i.e. maybe this 60% of the time or maybe that 20% of the time)?
I think every class will have some predicted probability including the ‘actual class’. The predicted class is simple the one with the highest prediction.
What I am unclear about is whether the ‘plot_top_losses’ function’s returned probability values is the highest probability value (among all the predictions) or just the value of prediction of the ‘actual class’. I think it is meant to be the later, but the docstring says otherwise.
I’m glad this thread exists. I’ve trained a model to ~95% accuracy, but every prediction probability is very close to 0, so it displays as 0. I initially found it confusing that the class with the highest probability has a probability of 0.
Is marmuc’s suggestion still something we would be interested in seeing added? If so, I might be able to work on that sometime, although I’m not familiar enough to know what you are referring to, jeremy.
I totally forgot about that issue. I don’t think there was any PR on this, I could try to fix it. I guess one easy fix to be less confusing would be to represent the numbers with 3 decimals instead of 2, but it would be best to fix the underlying cause as suggested above.
If I find the times in the next few days I’ll work on that but feel free to also try to fix it
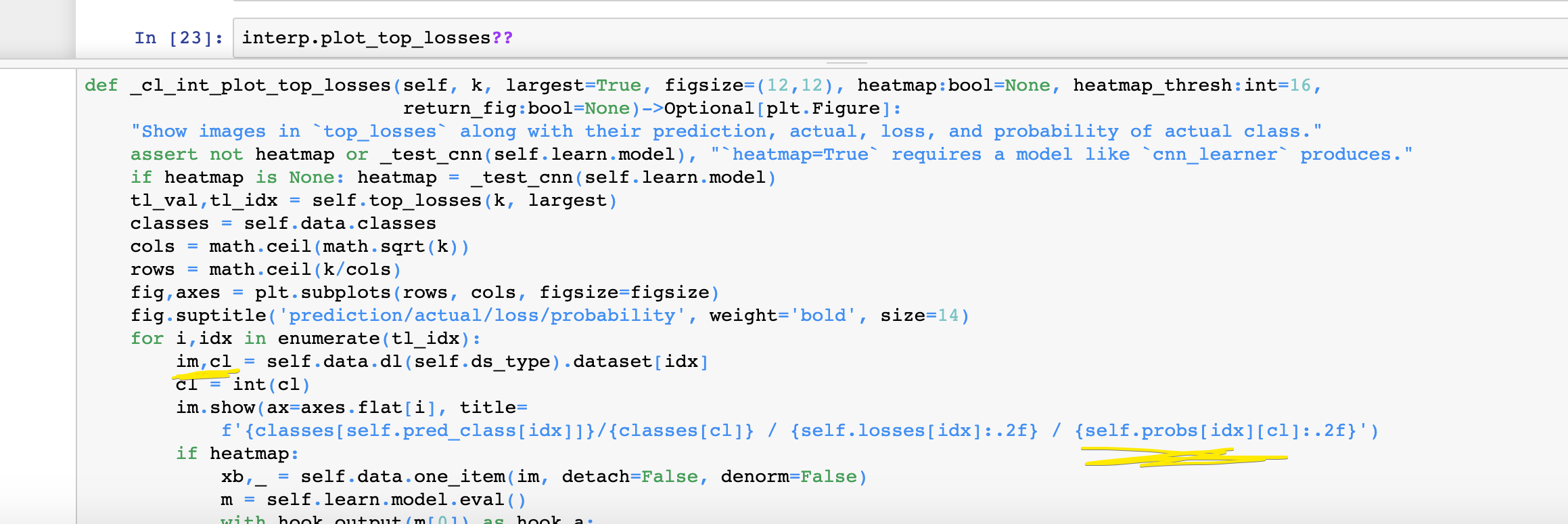
Looking at the source code for interp.plot_top_losses, we find
“Show images in top_losses along with their prediction, actual, loss, and probability of actual class.” in the first line.
I believe this should be changed to “probability of predicted class.” @PierreO, i do not think changing it to 3 decimals is the best approach because it’s fine to consider it 0.00 if probability is smaller than 1%. The problem seems to be in the underlying interpretation, which can be expressed better. @sgugger what do you think about this?
Take for example the first subplot. How can the predicted class “american_bulldog” have a probability of 0.00? If it was 0.00, it shouldn’t have been predicted in the first place. Is that an error in softmax?
Having said that, the output of learn.model shows Linear as last layer. Softmax isn’t listed at all in that topology output. Why not? Does resnet34 not have a softmax layer?
With reference to the first image, 0.00 was the probability that was assigned to the true class, i.e. boxer. And how CrossEntropyLoss works is the lower the probability you assign to the true class, the greater your loss, no wonder that image gave the greatest loss!
Why Softmax isn’t listed in the model architecture can be said to be a quirk of PyTorch, this may sound odd but the activation after the final layer isn’t defined explicitly, instead we rely on the loss function to do that. CrossEntropyLoss is a combination of LogSoftmax and Negative Log-likelihood loss. More information can be found in the PyTorch docs of CrossEntropyLoss!
Thank your for your answer, but I still don’t understand.
You’re saying that 0.00 is “the probability that was assigned to the true class”. However the fastai docs state “probability of actual class”. Could you explain again, please?
Concerning your explanation on Softmax, I don’t understand how the final layer’s activation can be “encoded” in the loss function. Isn’t the loss function only used in the training process?
When I use the model after training to make predictions for new data of unknown class, then the loss function is not even well-defined, since the labels are unknown. How can the output layer then rely on the loss function to calculate the prediction? Could you describe again, please?
You can see that cl is the true class of one item from the validation set. And later on when setting the title of the plot, they index into the probability assigned to the true class of the item.
During training, when the loss function is still relevant, it will first take the logsoftmax of the outputs of the model and then calculate the negative log-likelihood which will then be your loss. Here I emphasise that the outputs of your model are mere logits. Hence during inference, you will have to run softmax/argmax on the outputs of the model yourself. I hope this helps!
Thank you. That really helped. Knowing that during inference I have to add softmax manually, was crucial.
One final question concerning plot_top_losses: Who is assigning said probability to the true class and in which way? I, as a user, do not assign any probability to the true class. I just put training files into class-specific folders, which should translate to probabilities of 1.00 for the true classes (= one-hot-encoding).
Yes probabilities of 1 are assigned to the true classes since they are the labels. I suppose I too ,employed a poor choice of words earlier. With reference to my previous response, allow me to rephrase “…, they index into the probability assigned to the true class of the item.” into “…, they index into the predicted probability of the true class of the item.” And of course here, a Softmax was on the output logits to give said probability.