Hello all,
I’m trying to understand “Visualizing and Understanding Convolutional Networks” in a bit more detail.
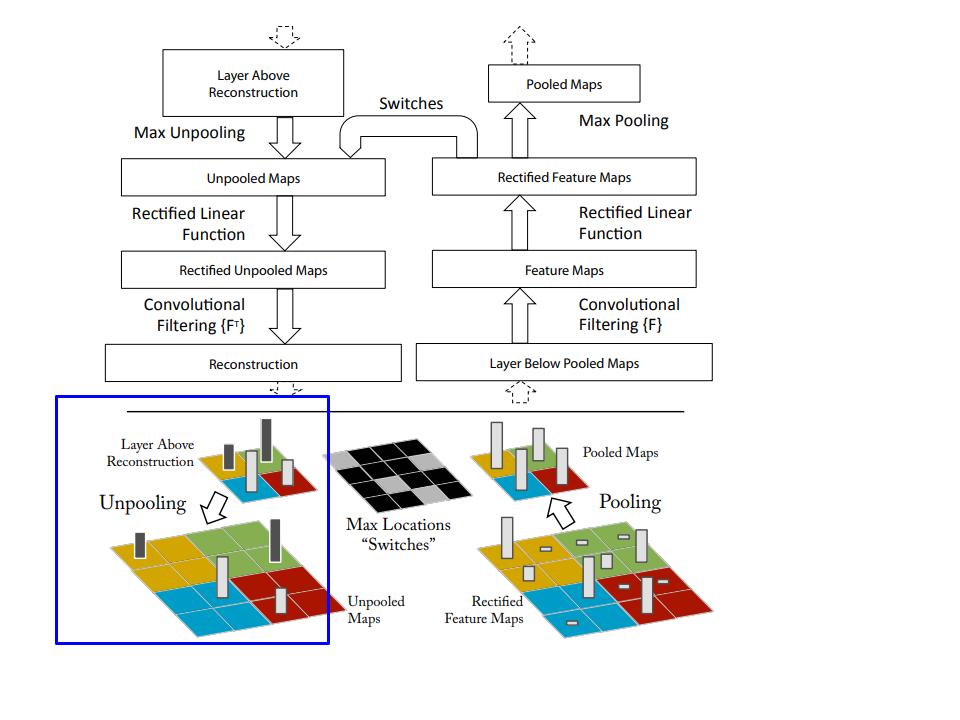
In the area I highlighted in the blue box; what is the formula which is used to go from the 2x2 image to the 4x4? As I understand; this is the step that uses each filter flipped vertically and horizontally; but I’m not understanding how those flipped filters are being applied to the feature map “coming back down the deconvolutional side.”
I did try looking at the referenced paper - https://cs.nyu.edu/~fergus/drafts/deconv_iccv_names.pdf - however I’m not wrapping my head around its explanations too well; and it references a third paper with regard to its work on “layers of convolutional sparse coding (deconvolution [M. Zeiler, D. Krishnan, G. Taylor, and R. Fergus. Deconvolutional networks. In CVPR, 2010])” <- and this 2010 paper appears to require access to download.
Thanks