So at the end of the pascal notebook we have this: learn.fit(lr, 1, cycle_len=3, use_clr=(32,5))
Looking at the code for learner.py I found that when specifying use_clr we end up using a CircularLR schedule instead of a CosAnneal. But even after looking at the CircularLR code I’m having trouble identifying what the parameters clr_div, cut_div means, and why is better to use a Circular anneal instead of a Cosine in this case?
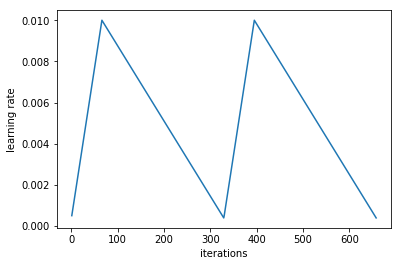
I think this is linked to the cyclical learning rates introduced here. I played around a bit and with 2 cycles with the parameters (20,5) I get this plot of how the learning rate evolved during the cycle (you can do it after a fit with learn.sched.plot_lr())
I think the first one, div, is by how much your learning rate is divided to get the minimum value (the maximum value is the lr you put as a parameter). The second argument seems to be the way you split your cycle between increasing and decreasing: 1/5 of growth and 4/5 of descent.
I’m having some issues understanding the second argument. I think I understand the first one as being the number of iterations it takes to go through the full cycle, is that how you understand it? The second one seems to be how fast it rises to the stop and goes back down, but I don’t understand how you know it’s 1/5 and 4/5, is it always that way? Like if I had a 10 in there would it be 1/10 of growth and 9/10 of descent?
The first one isn’t a number of iterations, it’s the scale between your minimum and your maximum. With 20 for instance, you begin at 0.0005 if your learning rate is 0.01 (like on the graph I showed).
Then the second one works exactly like you just said: with 10 it would be 1/10 of growth and 9/10 of descent. A typical use would be to do this with a cycle_len of 10, then during 1/10 of the cycle (one epoch) you would grow from your minimum value (lr divided by the first argument) to your learning rate, then for 9/10 of the cycle (nine epochs) slowly get back down to your minimum value.
Why is it only designed to be used with one cycle? Do you mean the second arg should always be 1 when use_clr is specified, e.g. learner.fit(lr, 1, ..., use_clr=(20, 5))? It seems to me it works perfectly fine even when 2nd arg is some value other than 1. Thanks in advance!
Leslie Smith’s new paper is the best place to read about the reasoning. The code will work fine with more cycles, but the paper recommends using just one.
It’s a bit confusing his reasoning in the paper. Firstly he says
Furthermore, there is a certain elegance to the rhythm of these cycles and it simplifies the decision of when to drop learning rates and when to stop the current training run. Experiments show that replacing each step of a constant learning rate with at least 3 cycles trains the network weights most of the way and running for 4 or more cycles will achieve even better performance.
And then he says that actually the best is to stop after the 1st cycle
Also, it is best to stop training at the end of a cycle, which is when the learning rate is at the minimum value and the accuracy peaks
But when we look at figure 1, we see the accuracy peaks at the end of each cycle. And eventually the accuracy gets slightly better on cycle 2 and 3.
I’m using cyclical LR with parameters as use_clr = (30,5). It’s clearly working better for me compared to normal cosine annealing. I want to understand if there are some guidelines for choosing the 2 numbers or is it purely experimental? If people who have tried it can share their observations then it will be really helpful. Thanks in advance!
Generally something around (10,10) seems to work pretty well. If you’ve got more epochs or larger dataset, try changing the first number to 40. For small datasets, try changing the second number to 5.