lr changes at each batch, not each epoch (that does not contradict what you wrote).
With fastai’s implementation, max_lr is by default reached after 30% of the training, which would be at the beginning of the 4th epoch in your example.
But you’re basically right, that is how it works.
I might have gotten index wrong for max, but I hope you see my thought process. Do each batch have their own “mini” learning rate cycle, analogous to how the epochs within the full training cycle has it?
Nono, just take tour epoch schedule: Epoch [0.1/25 (min), #1, #2, 0.1 (max), #4, ...]. So within the first epoch you want to go from 0.1/25 to #1. Let’s say #1 = 0.1/10 for instance, if you don’t want to suddenly increase the learning rate at the end of the first epoch, you can instead increase it by (0.1/10-0.1/25)/n_batches after each batch. For 100 batches, that would be 1e-5. Thanks to that, you reach #1 at the beginning of second epoch, which is what you wanted.
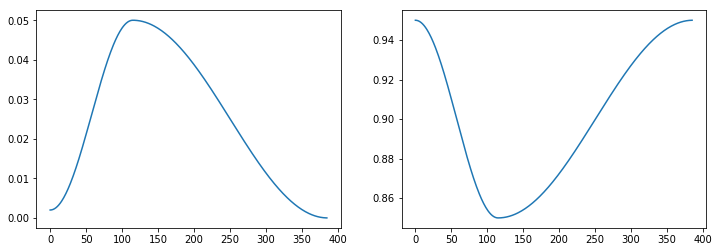
In reality they don’t do it linearly, but that’s the same idea: you increase by a little bit at each batch so that it fits your general schedule. The general evolution over all epochs looks like this graph that you can find here (it is the left one, the right one is for momentum):