First off, I’d just like to apologize if my question has already been answered in some form elsewhere in this forum, but based off my searching I couldn’t find a question in this exact format.
Working through Lesson 2 in Colab, I found that I had a significantly higher error rate than Jeremy was able to get using ResNet 34, in fact my error rate was about 10 times that of his. So in order to lower the error rate, I used ResNet 50 but saw little to no improvement.
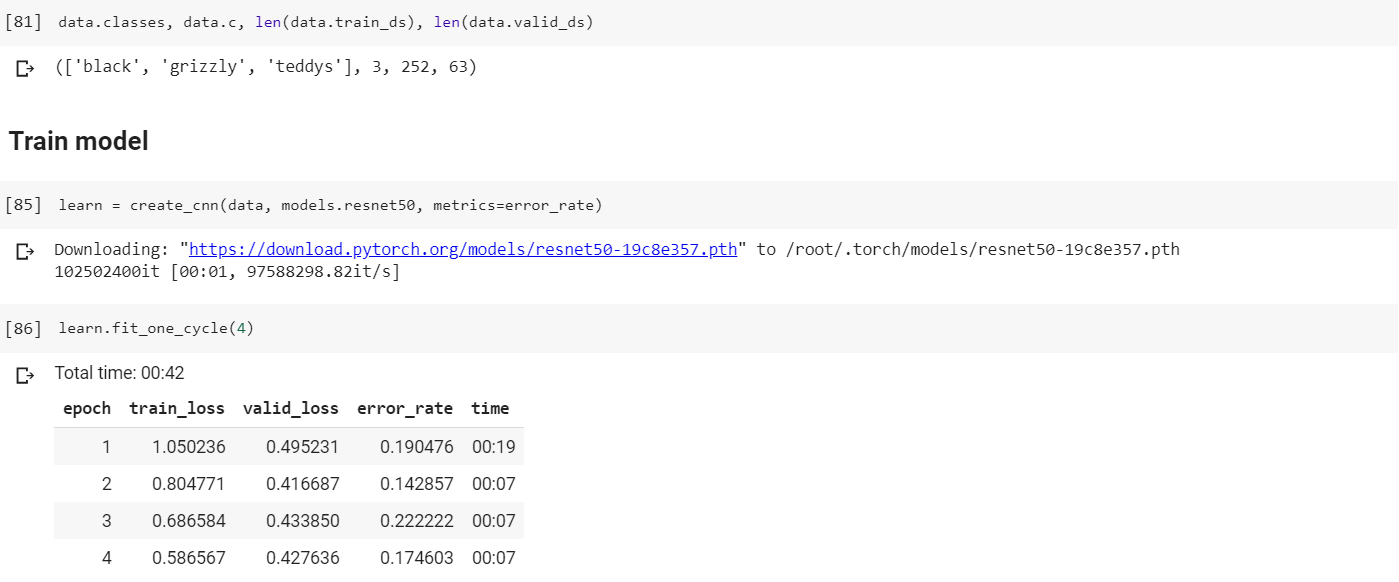
When using fit_one_cycle, I did see improvements in the accuracy of my model, however it was nowhere near the accuracy of Jeremy’s model.
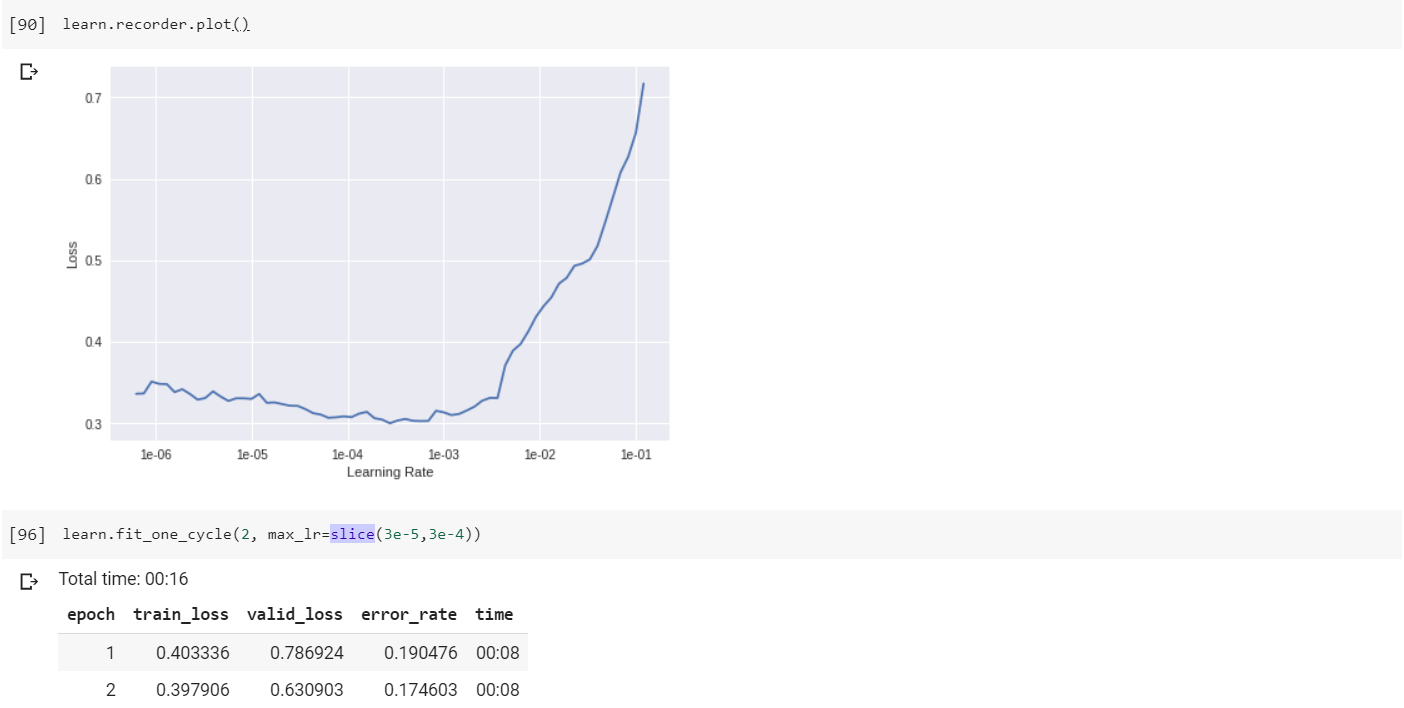
Given that my graph sees a sharp spike in loss after 1e-03 and does not have the characteristic strong downward slope, should I use the highest learning rate that doesn’t result in a major increase in loss?
Based off answers from other such similar questions, I am of the opinion that the difference in error rate is due to outlying images being present in my dataset, or simply that I had fewer images in my dataset. However, the recommended solution was to “clean out” the dataset. Is there any way to automate this especially for datasets of a larger size without manually filtering (ImageCleaner)? It seems inefficient and improbable for larger datasets.
Any and all help would be deeply appreciated. Thank you very much!