I am trying to understand how embeddings for categorical variables work in the tabular learner model.
I reviewed this blog post on how PyTorch treats tabular learners:
Assume X is your dataset and W is your weight matrix for one layer of the NN. (I’m going to use a simplified model here, with only one paramter vector and one sample vector, and ignore bias.) It looks to me like what is happening is categorical variables are being converted to an embedding, and that embedding is being added to X as a set of values.
For example, if we have a dataset with continuous variables age and years_of_education and categorical variable birth_month with values as follows:
age = 25
years_of_education = 4.3
birth_month = January
then the tabular api would create an embedding for each month. Suppose the embedding size is 2, so January is represented by [0.2 0.8]. The entire input vector X would be [25, 4.3, 0.2, 0,8]. (This is how I understand it working, but please correct me if I’m wrong.)
The learner would then create a vector W with weights [w1, w2, w3, w4] and (ignoring bias) do a dot product beween W and X. It would then apply a non-linearity, etc. until it got to the final output, and then backpropagate. This is a conventional fully-connected model.
In a conventional NN, only the W vector is updated. But we also need to update the embedding in X to make it more “Januaryish” since it is initialized with random numbers. So does the tabluar model also use backpropagation to update the embeddings in the X vector? Or do I completely misunderstand the model architecture?
Not quite but close. Instead our embeddings are n+1 options. So if we have days of the month, our embedding vector for that variable is Jan, Feb, March… + nan to deal with ‘other’, or a 1x13 vector. We then dictate how large of a space we want for it’s weights and relationships, eg 13x600 (for example). Which is determined by the embedded size rule. Then we fill in our relationships as you said. So in actuality the ‘default’ would give us a matrix 13x5. To the rest, yes you are correct in how it is being updated.
So in your example of a 13 x 5 embedding matrix for month, each row represents the embedding vector for a month or “other”. In my January example, is it correct to say that the input vector (X) (after the concatenation of the categorical and continuous variables for a given sample) would include only the embeddings of January for that sample? And an input vector for a March sample would include only the third row? And then the algorithm would backpropagate and update the 13 x 5 embedding tensor?
I think this is what Jeremy is getting at with the one-hot-encoded matrix? We could add a one-hot-encoded multiplication to select the correct month of a particular sample, but it ends up being equivalent to just including the array for that month, so we leave that multiplication out?
It seems like tabular is a combination of a basic NN for the continuous data and a collaborative learner for the categorical data. In the former, backpropagation does not affect the input (X) variables, but in the latter there is backpropagation to update the embeddings in the input variables. The updating of input variables is the part I had never seen before and was confusing me. I suppose it’s implicit in the lectures but it’s never stated.
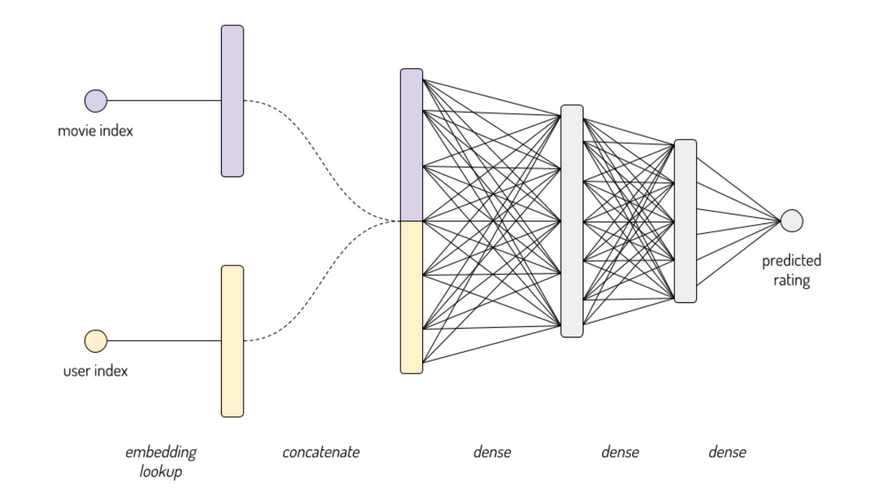
In the (unlikely) event that anyone ever searches for or reads this question (and for my own archival purposes), there is a lesson Kaggle that covers this, and it has a nice diagram showing concatenation of the embeddings for the movie database as per the collaborative learner that Jeremy uses. I assume that Tabular learner works on the same premise. In this diagram, substitute “categorical variable” for “movie index” and “vector of all continuous variables” for “user index”. Multiple categorical variables would get mutiple vectors:
Presumably, the tabular model concatenates the categorical variables’ vectors with the continous variables as per this diagram, and then passes it through a conventional neural net.
Thanks, @Mark_F. I’m going though the lectures for the first time and have been struggling with this concept as well. Something I’m still hung up on… the way Jeremy describes implementing the movie recommender model having a bias term makes a lot of sense. Dot product the two embedding vectors and then adjust with the bias parameter. It seems from the descriptions here that a bias term is unnecessary in an embedding when it is feeding into a dense layer along with other input data.
Does that make sense or am I missing something? Thanks for following up with the Kaggle reference!