Hi, after replicating a paper from Google from 2018 about view synthesis/lightfields, I’m trying to replicate another one from 2019: DeepView: View Synthesis with Learned Gradient Descent and this is the PDF.
Basically the input to the neural network comes from a set of cameras which number is variable, and the output is a stack of images which number is also variable. For that they use both a Fully Convolutional Network and Learned Gradient Descent.
I don’t know if I am understanding this correctly: (in each LGD iteration) They use the same network for all depth slices AND all views. Is this correct?
This is the LGD network, not much important to the question but it helps you understand the setup. You can see at least 3 LGD iterations. Part b) is just the calculation they do in the “green gradient boxes” on part a).
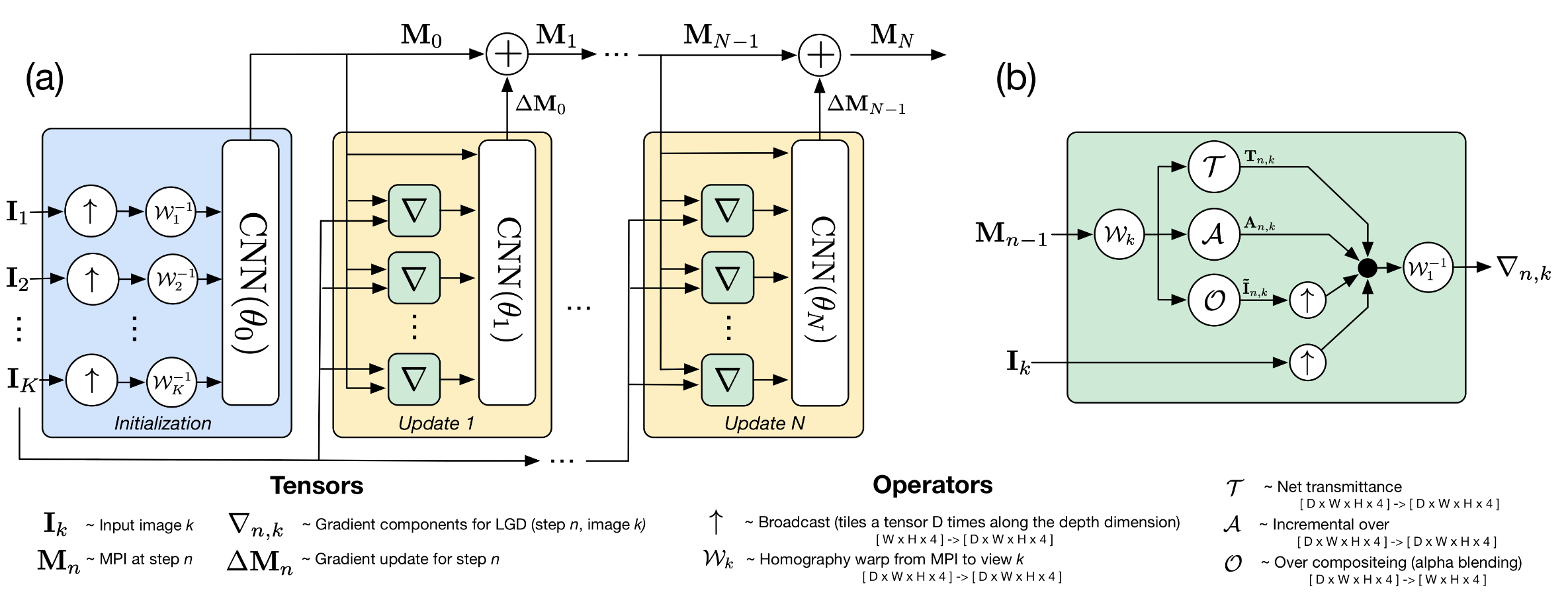
This is the inside of the CNNs. On each LGD iteration they use basically the same architecture, but the weights are different per iteration.

For me the confusing part is that they represent each view as a different network, but they don’t represent each depth slice as a different network. As you can see in the next image they do say that they use the same parameters for all depth slices, and that the order of the views doesn’t matter so it must be that they’re also reusing the parameters for all views, right? So if I understand correctly, this is a matter of reusing the same model for all depths and all views. BTW note that the maxpool kind of operation is over each view.
Also I have a question on the practicalities of the implementation. I’ll be implementing this with normal 2D convolution layers, so if I want them to run independent of the views and depth slices, I guess I could concatenate views and depth slices in the “batch” dimension? I mean, before the maximum k operation, and then reuse the output.
This is what they say:

Thanks