I stopped using AWS and moved to my personal laptop, since I am only doing tests for understanding the code.
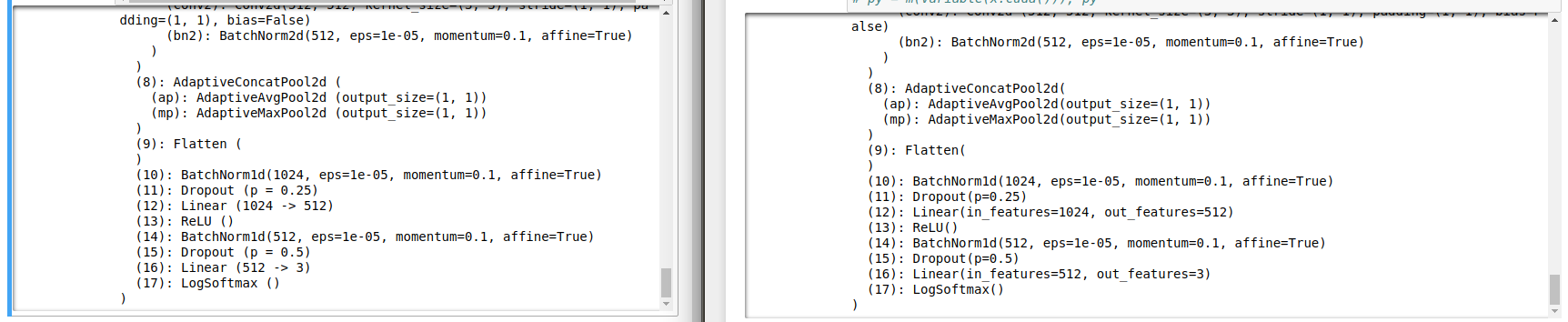
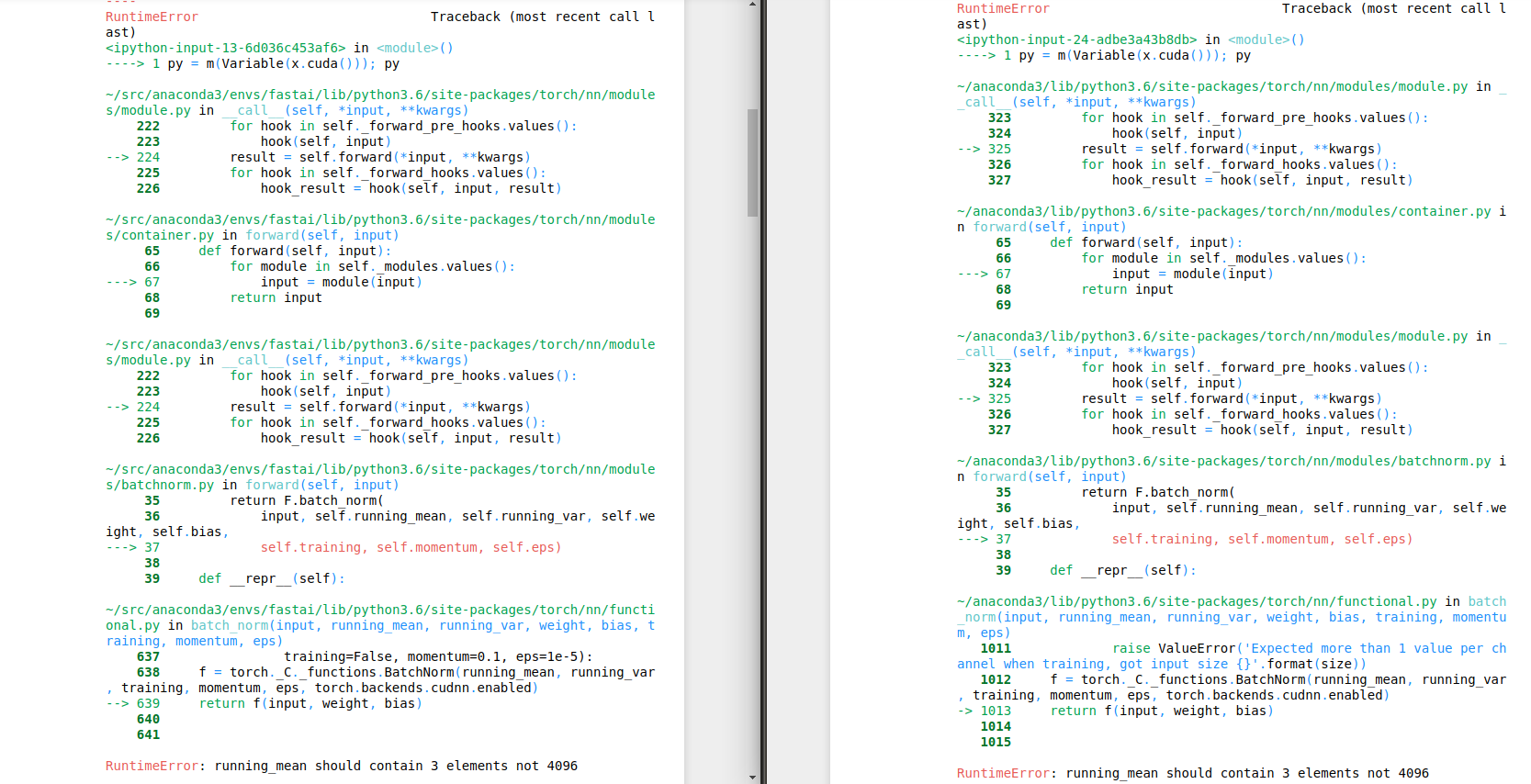
I struggled with this error for a while Expected more than 1 value per channel when training, got input size [1, 1024] and I tried to figure out what am I doing wrong. I have seen that this error is displayed by the forward function which calls the F.batch_norm. And interpret it as the fact that he aspects and image [1 3 224 224] for example or [1, 256, 14, 14] where 256 is the number of filters and 14x14 is the size of the input/image. So it does well until the input is flatten - transformed into a vector.
size(input): [1, 64, 112, 112]
size(input): [1, 64, 56, 56]
.....
size(input): [1, 512, 7, 7]
size(input): [1, 512, 7, 7]
size(input): [1, 1024]
Trying to figure out what’s the issue, I replicate the same content on the AWS - where I have no error - running the exact same code. Any help, or orientation tip is extremely appreciated
On the left is the code from aws, and to the right is the same code on my pc + the error
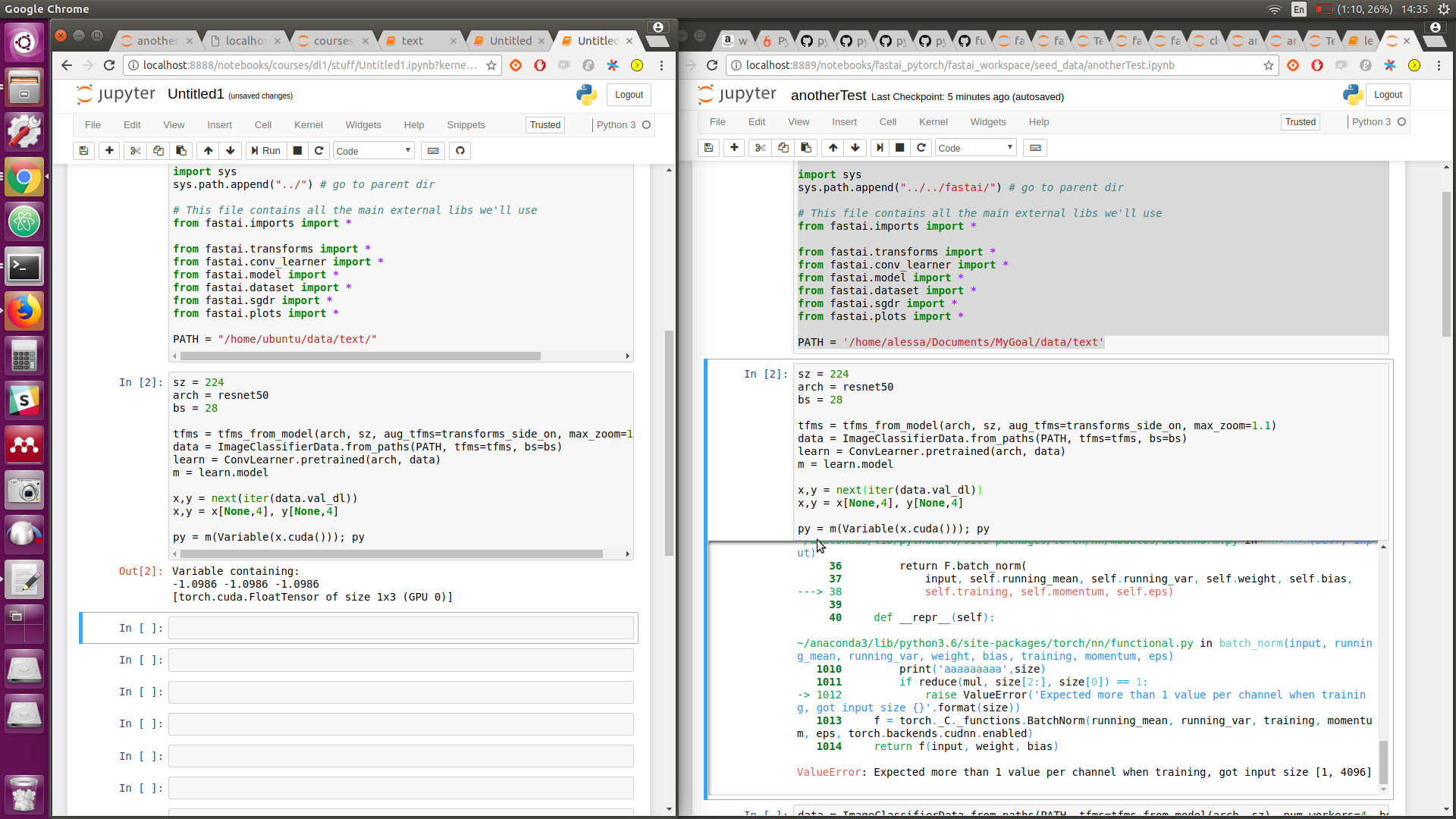
p.s. Even the model looks the same