md.trn_dl = 963 … which equals # of tokens / batch size / bptt.
Does that mean when the forward function is called, each mini-batch will be a tensor of size 64x8?
And is it right to think of this as saying, “pass me in 64 things, each consisting of 8 characters … and then after that, pass me in another set of 64, 8 character sequences, that are composed of the last 7 characters from the previous mini-batch + 1”
Just trying to wrap my head around all this by anthropomorphizing it (rightly of course).
I think about the batch size as how many characters we will be seeing in parallel, so the batch will be in the form:
bptt (number of chars the backprop will consider) x batch size (how many things in parallel) (exactly what you said, just transposed)
But I believe at this point the batches don’t contain overlapping chars, this time we “put the triangle (output)” inside of the for loop, so we make a prediction of the next char every time we see a new char.
I think I got it backwards based on the sketch Jeremy did in lesson 7 that made it look like the text was arranged by bs x bptt. However, when I ran the lesson 7 notebook and printed out cs.size() it would return something close to 8 x 64 (confirming your understanding).
And you are right that the batches do not overlap.
So to anthropomorphize the forward pass …
“Pass me the first 8 sequential characters of 64 different segments of text … and then pass me the next set of 8 characters for each of those 64 segments. For each character in each of these 64 segments, I will use it (and any other characters that come before it in the segment if we are looking beyond at characters 2-8) to predict the next character. So, I’ll use character 1 to predict character 2, characters 1 and 2 to predict character 3, characters 1,2, and 3 to predict character 4, and so forth. At the end of each call I will return 8 predicted probabilities for each character in the vocab.”
I’m trying to figure out where in the code this is happening. Is the targeting of the next character explicit or does it automatically happen through the backpropegation because of the recurrent layer?
I understand linear/CNNs when it comes to updating the weights based on the gradient, but I’m a little unclear for recurrent backprop. Are the weights updated based on the error at each iteration? Or is this error somehow aggregated/averaged?
Looking at the wiki on this subject I was able to answer my own question but rather than delete it I thought I’d post the answer. It turns out the weight updates are summed rather than averaged in this case. I also finally understand where the term bptt comes from.
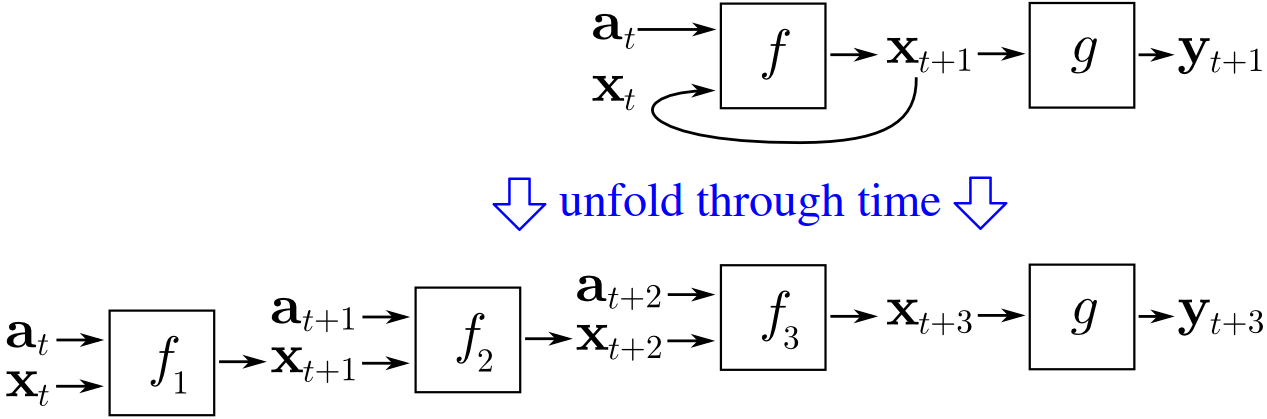
It is happening implicitly in the for loop that is the RNN. Every character input adds to the state captured in your hidden layer, and at the end of each character as it is processed, the output (its prediction) is captured as well.
Thus if you look at the stateful model examples in the lesson 6 notebook, you’ll see that you get 8 predictions returned for every minibatch.
Throw in some print statements before you run the code to display the size of things. I know this really helped me build some intuition.
The sequences should be almost constant given whatever you assign bptt too.
If you don’t want to include stop words in your model, I would think the best approach would be to just remove them from your training/test data (see the spaCy docs for ideas on how you might do this).
Ok…i think i understood the difference between bptt, batchsize etc. I am still confused about one thing and that might be just how notations and implementation happen…
are bptt and seq_len the same thing ??@jeremy@Even
If thats not the case can someone please explain, what does seq_len mean ?.
EDIT: based on the conversation below, here are the concepts in a ppt format.
bptt and seq_len are almost the same thing: the slight difference is that bptt is a fixed hyperparam, while seq_len is approximatelybptt, and can vary between minibatches. For example, see nlp.py and text.py in the fast.ai library.
In terms of how Pytorch’s RNN/LSTM/GRU layers work, they take inputs of shape (seq_len, batch_size, embedding_size).
Thanks @cqfd for the answer, really helps solidify my understanding. just so that my understanding is correct, so thats the reason why anyone who is explaining rnn for the first time , says rnn’s can process variable length sequences. am I rite ?
p.s I havent done much rnn’s/ sequence modelling before, so if this is totally obvious thing, pardon my limited understaning
It’s not quite the same thing. RNNs can process variable length inputs because they’re fed a sequence and their output is a sequence. You feed it one character/word/??? at a time and at every iteration you get an output, whether you chose to look at it or not. This is true for all RNN models.
For language modelling we’re trying to learn to predict the next char/word based on the previous sequence. In order to make that more robust and to help prevent overfitting the sequence length is varied randomly so that instead of always learning to predict the 11th word from a sequence of 10 words it splits up the data into sequences of a length that’s random, but normally distributed around the bppt hyperparameter.
Hopefully that helps a little. I recommend watching a few more videos on RNNs and rewatching the related lessons. It’s a complex topic that took me a number of tries to understand and I’m still learning it.
Got it. Thanks @Even
Finally, i think i understand.
So, rnn’s can process variable length sequences because it’s “just a for loop”: therefore it will loop through whatever length sequence the data-loader provides.
Because that’s the case, the dataloader can be smart and feed in varying length sequences so that we do not overfit the sequence length which is done by feeding in sequences normally distributed around bptt
I know this thread is quite old, but if the RNN’s accept random sizes, why do we need the padding token to make the batches to equal length?
And how does the RNN predict the next word. Don’t we just set the labels to 0 when training the language model? I don’t understand where in the code it changes to trying to predict the next word instead of always trying to just predict the 0
Batching is done to help make the compute more efficient. So while the architecture itself can take sequences of any length, if we want to leverage parallel computing we need to pass in sequences of the same (or in this case similar) length. What BPPT with sortish sampler does is approximately group sequences by their length, and then pad them to be equal so that the batch can run all together.
In terms of predicting the next word, the output of the model is a vector where the highest value of the vector corresponds to the word that the model is predicting. The output of the model is then used as the input at the next time step. There are some exceptions, like teacher forcing, where you feed the target instead of the model output, or beam search, but generally speaking you can think of the RNN as taking a sequence in and outputting a prediction of the next word. You iterate on that to produce longer output.