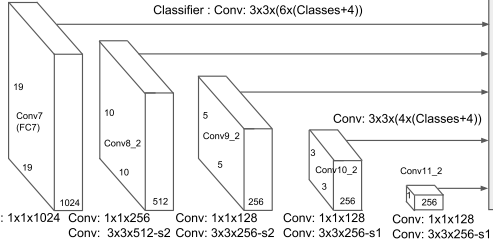
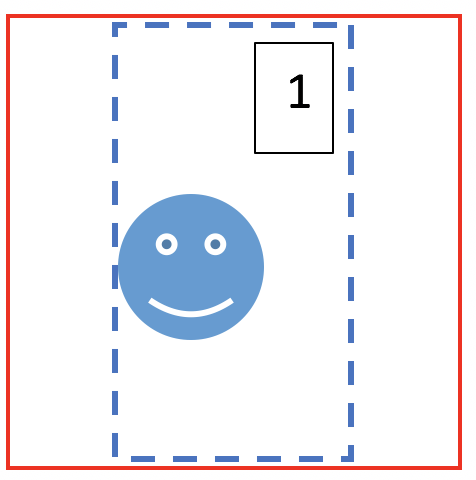
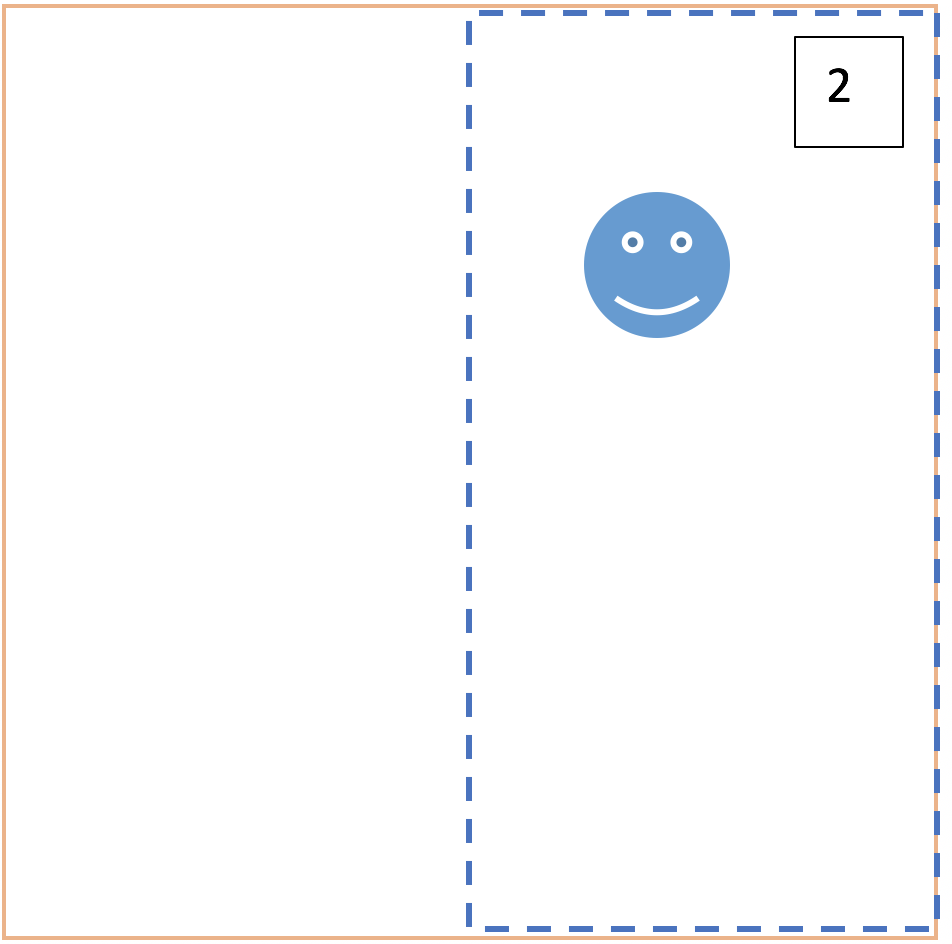
BIG QUESTION ALERT !

Call-outs: The gaps between the anchor boxes is only for visualization purpose!
The white part can be assumed as “bg”
Cases = { 1: “Perfectly inside”, 2: “Almost perfectly shared”, 3: “Imperfectly shared” }
Q1: Can the bounding box generated for blue face in the 2nd anchor box of 4X4 grid be bigger than the anchor box itself?
Observation: Yes, I found many cases where the bounding box of the final output was much bigger than the minimum sized anchor box needed to enclose the object.
My understanding: For every anchor box we are trying to find a square/ rectangular bounding box with different zoom/ orientation all centered at the center of the anchor box. When we move from 4X4 grid to 2X2 grid, the anchor box gets bigger and therefore the receptive field of the network is enhanced, but at the same time the IOU of the object detection reduces greatly. So, my belief is that the network would opt for the lesser IOU loss and assuming the BCE loss is already minimum meaning the class of the object is rightly detected, the output in such scenarios should be a smaller bounding box with a max size of corresponding anchor box. What am I missing?
Q2: Can the bounding box for the green face be exclusively inside the 4 anchor boxes which contains it?
My understanding: When are move from 4X4 grid to 2X2 grid, the IOU is reduced and at the same time, all anchor boxes have almost equal value of IOU which after taking max would be misleading, my reason for this comes from the example showed in class, the IOU for class A had 2 anchor boxes with 0.25 and 0.45 values but the IOU for class B had a max of 0.03 value. So even though the marginally available evidence of class B is wonderfully captured by the network, we just let go of the many evidences for class A by using max. Sounds bad to me! I strongly believe the output bounding box for green face will be somewhere in the 1X1 grid but please help me, if you think otherwise.
Alternate theory: (Top of my mind thought, may sound extremely vague!)
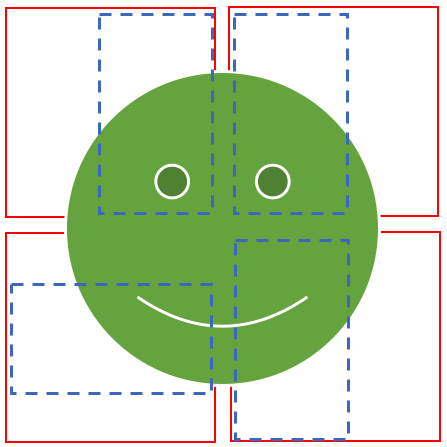
If above four are the suggested bounding box for each anchor box then is it possible to fuzzy match the edges and create a unified bounding box taking max diagonals of the fuzzy match? Also, I noticed that the aspect ratio of the suggested bounding boxes are same ( because we decided that for various receptive fields?) and their locations are almost centered at the center of the enclosing anchor box, is it just a bad observation or I’m connecting the dots right?
Q3: Can we find an almost perfect bounding box for yellow face?
My understanding: This a very loosely defined question because I think the gap I have in question 1 and the CORRECT theory for question 2, when combined, will answer this question (Re-factoring thoughts  ). But I’m still asking so that it triggers more questions in your mind and we may find something bigger.
). But I’m still asking so that it triggers more questions in your mind and we may find something bigger.