I have troubles understanding 3 things and would be happy if somebody could help me to understand it. RNN Classifier has the following structure:
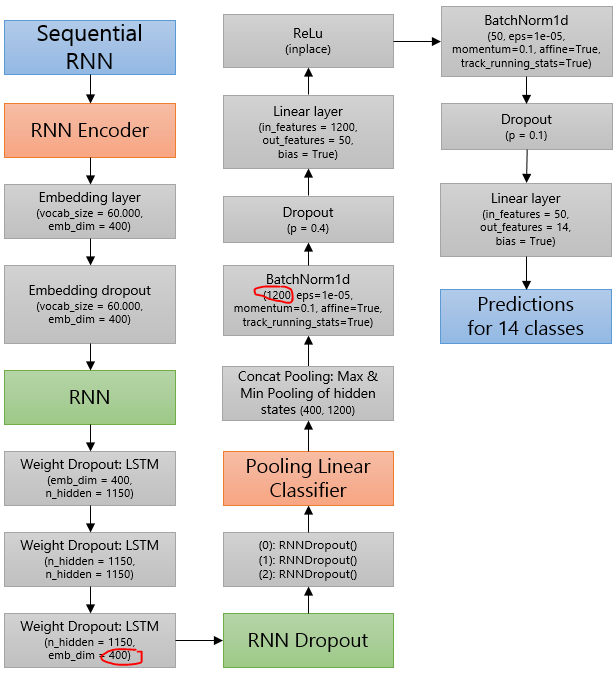
-
The input to BatchNorm1D is 1200, even though the previous layer has a shape (1150,400). Why isn’t it 400? I marked it red. Is it because of Concat Pooling? If so, it would imply the structure below. Can you confirm whether my assumption is correct?
-
Why do we apply RNNDropout() at the end of a language model? it looks like throwing away predictions for certain possible next words. Could you explain? I don’t understand the reasons for using dropout at the end.
-
I couldn’t map the dropout from the ULMFiT paper to those dropouts in model’s summary on which I based this visualization. From the paper: “We apply dropout of 0.4 to layers, 0.3 to RNN layers, 0.4 to input embedding layers, 0.05 to embedding layers, and weight dropout of 0.5 to the RNN hidden-to-hidden matrix.” Was it changed in fastai v1 in comaprison to ULMFiT? In particular, where do we apply 0.4 input embedding layer dropout and where 0.05 embedding layer dropout? Cause it seems to me that there is only 1 embedding layer.
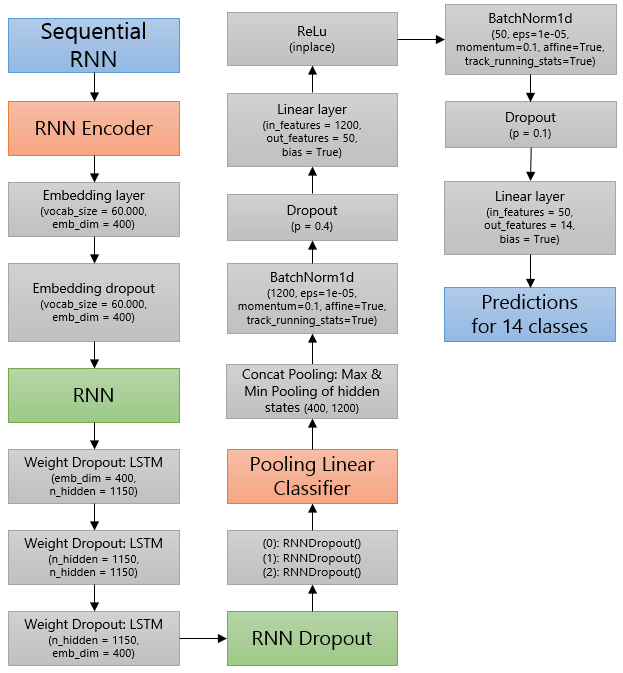
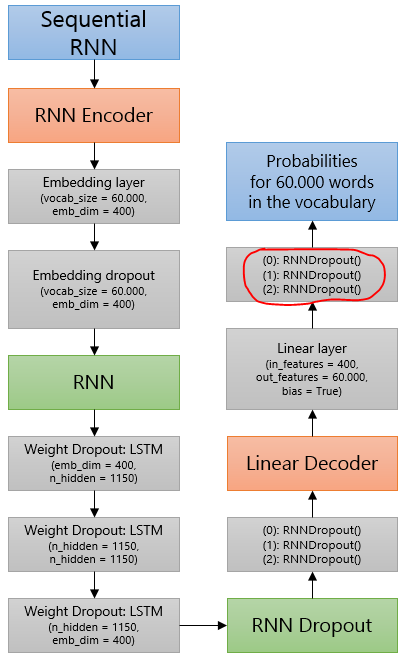
Thanks a lot in advance!