Hi all,
I am following fastai v2 text classification tutorial (ULMFiT approach) using my own dataset. The first language model part went fine, thenI had an issue on loading my multilabel dataset for classification part.
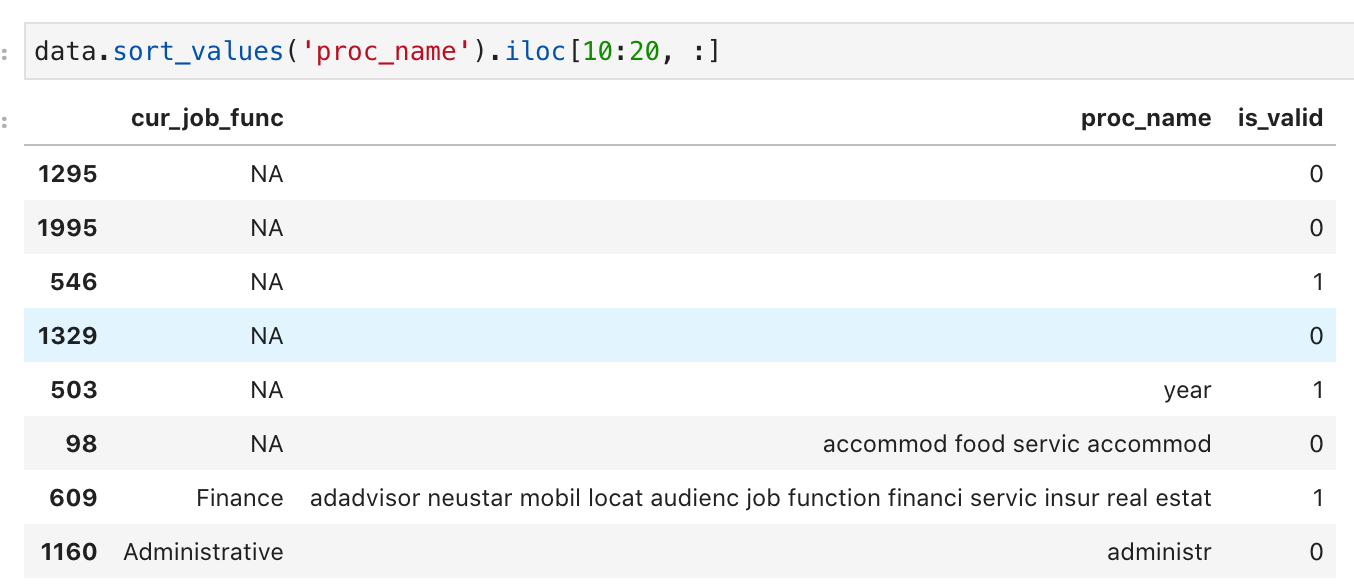
I am currently on fastai 2.0.8. My dataset is a pandas dataframe and looks like this.
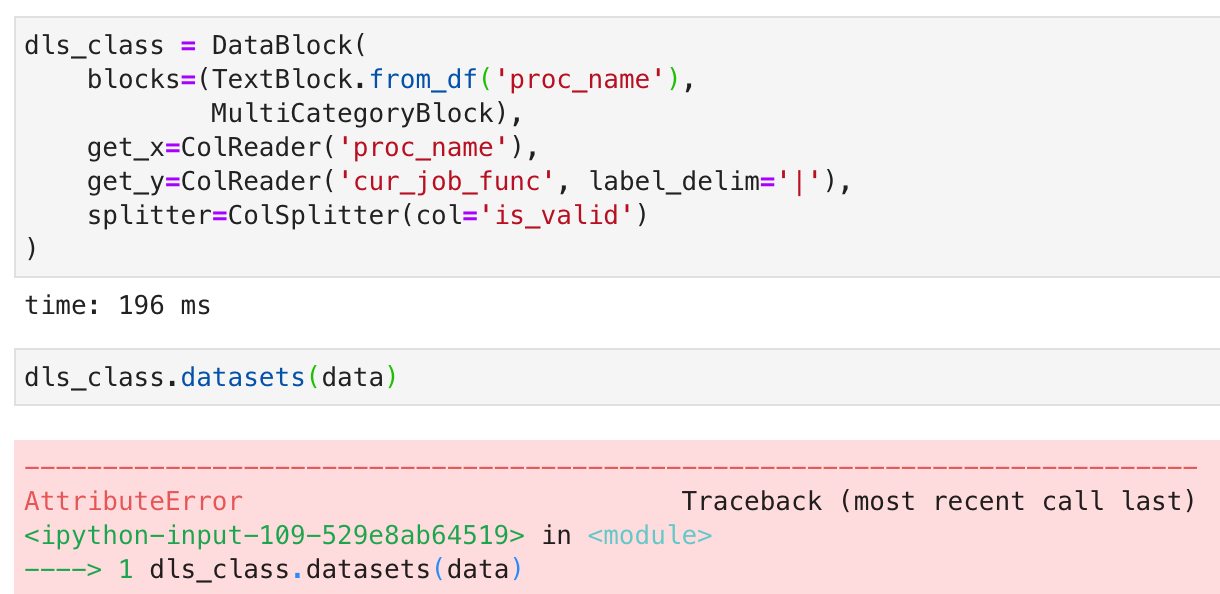
I then created a DataBlock object and called datasets I got this AttributeError: 'Series' object has no attribute 'proc_name' error which I cannot figure out.
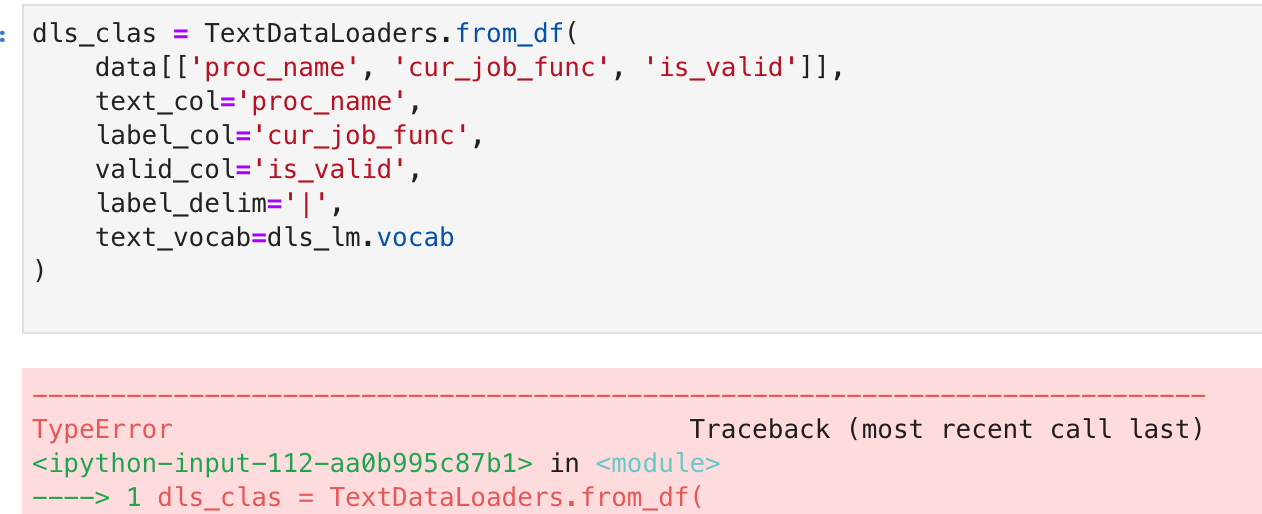
Thanks kmule, I had the same problem and it cost me about an hour.
The example at https://docs.fast.ai/text.data#TextBlock.from_df is unhelpfully misleading. The source text column in the example file is called text, but this has nothing to do with why the argument to get_x is also text.
You can either use res_col_name to change the output column name, or just understand that TextBlock.from_df is going to put the tokenised text into a column called text no matter what your source column is called: