As discussed with @piotr.czapla, I’ll open an issue at the fastai github. I’m gathering the information needed for the issue, and will open it once I’m done.
For a quick fix simply save the best model and restart the training by loading the weights,
to do so use SaveModelCallback https://docs.fast.ai/callbacks.tracker.html
1 Like
OK, thanks!
Hi, we are trying to make summary of ulmfit efforts see: Multilingual ULMFiT
Do you have some results trained on the publicly available / official data set?
Hi @piotr.czapla ,
Yes, I can help with that. I have a few details that I’d like to discuss with you. Can I have your e-mail?
Ok. Thanks
Wow, really cool to find you guys around here working with portuguese datasets.
I would love to cooperate! 
Hey guys!
Whats the status on this? Do we have a portuguese model already? if not, how can i help?
@piotr.czapla do you know how do i start to contribute to this? any place i can start?
Thanks and congrats for the efforts!
Hi Joao We do have a model but I suspect that it isn’t that performant as it could be as it was trained on wikipedia that has formal language. You could try to train a model that is using informal language like one used on reddit or twitter. We had good results on Polish language by pretraining on different text types. We could then test that model on some dataset and compare it to one pretrained on wikipedia.
Hello Piotr. Where can i find the notebook used to train this model? Do you guys have a sample notebook on how to train a new model? Or even how you trained for english, or this Polish model you cited? That would be awesome. I want to help but i dont know how, and really didnt want to start from scratch…
thanks and congratulations for the work being done…
Using fast.ai version 51, just follow the template below in order to train a portuguese language model:
from fastai.text import *
path = Path(“data/wiki/pt/”)
tokenizer = Tokenizer(lang=‘pt’, n_cpus=4)
lm_data = TextLMDataBunch.from_csv(path, ‘train.csv’, tokenizer=tokenizer, label_cols=None, text_cols=0, chunksize=5000, max_vocab=60000, bs=64)
learn = language_model_learner(lm_data, AWD_LSTM, pretrained=False, drop_mult=0.)
learn.lr_find()
learn.recorder.plot(suggestion=True)
learn.fit_one_cycle(10, 2e-3, moms=(0.8,0.7))
learn.save(‘pt_language_model’)
lm_data.vocab.save(path/f"models/pt_itos.pkl")
2 Likes
Hi @NandoBr, I´m working on a 60K PT-wiki LM model, and came accross your work while looking for benchmarks in portuguese. I believe that the classification results your team achieved over the TCU dataset is a great benchmark. Would you mind sharing some details, like the train-valid-test split ratios used and per class metrics (f-score/accuracy)?
Best Regards
Never mind, I´ve just found the split ratios in the notebook you shared!
I have a public school that is interested in building a chat bot to help high school children with their home work. Would love to help you guys to see if we could get something like this done. I’m thinking that the hardest part would be to get the model to recognize the math symbols, but I would be curios to see what we could obtain if we specialized the language model with about 20000 questions and answers in math.
Can I help?
Just sharing some early results from my work. Currently one can actually get up to 0.34 accuracy for Portuguese LM using the latest notebook on language modelling (https://github.com/fastai/course-nlp/blob/master/nn-vietnamese.ipynb)
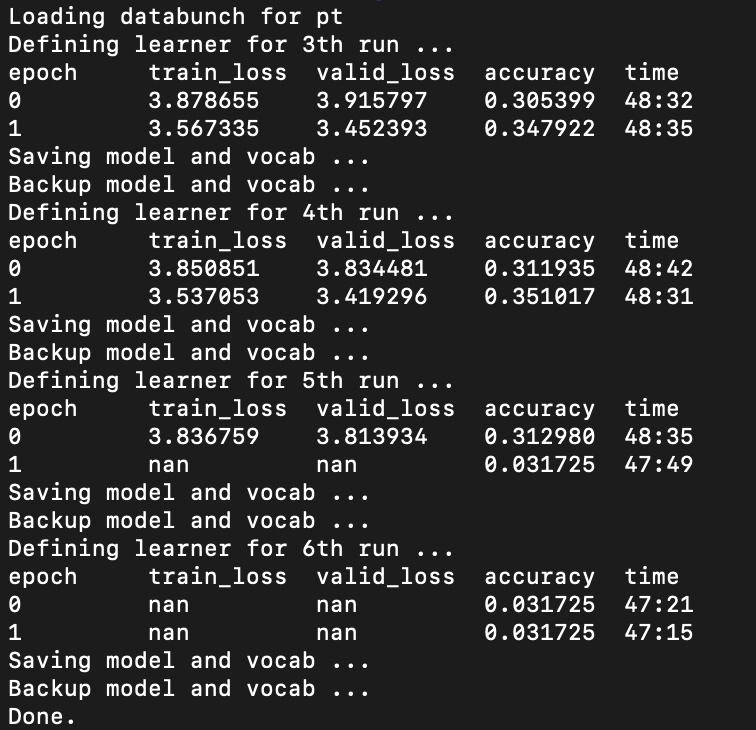
I literally didn’t make much change and used only the defaults. Only change I had to made was on the nlp_util script, where I had to change the encoding to ISO-8859-1.
Also interesting to note that the loss went bonkers after the 9th epoch. The above screenshot was taken from my terminal, since I changed the notebook to a script due to the long training process. I also had the model and vocab saved every 2 epoch (via for loop) so that I my training hours wouldn’t be wasted (I’d seen the NaN beforehand).
Hi guys! I’ve trained an Portuguese model with an Wikipedia dump by using @piotr.czapla instructions, and I have arrived at an accuracy of 54.8% and 11.65 perplexity.
The repository is here: https://github.com/danilolessa/Portuguese-ULMFiT and I suggest seeing @Antti_Karlsson finnish pre-trained model repository for getting an ready and clear Jupyter notebook as for how to use it for classification tasks.
[ EDIT ] I made a correction in the notebook of my TCU classifier and got an accuracy of 97.95% higher than my previous one (see my post).
Hi @monilouise, @NandoBr e @ErickMFS.
Following the publication of the MultiFit paper on September 10 (authors: Julian Eisenschlos, Sebastian Ruder, @piotr.czapla, Marcin Kardas, Sylvain Gugger, Jeremy Howard), I wanted to verify that the MultiFiT configuration gives better results than the ULMFiT one you used in order to firstly train a Portuguese Bidirectional Language Model and then, to fine-tune a classifier of the TCU dataset (thanks for making this dataset available).
And indeed, there is a slight progression: my legal text classifier reached an accuracy of 97.39% and a F1 score of 0.9737 (less than 5mn to fine-tune the bidirectional Language Model to TCU texts and the same time required to train the bidirectional classifier).
So, I published my notebooks on github:
- Bidirectional Language Model of Portuguese lm3-portuguese.ipynb trained over 16 hours,
- classifier of TCU legal texts lm3-portuguese-classifier-TCU-jurisprudencia.ipynb)
- and o link to download the Language Model’s parameters and vocabulary.
I also posted a post on medium explaining the motivation, the results and the configuration used.
Note: I trained my models on GCP with 1 GPU NVIDIA Tesla V100.
Bonus: I love the function show_intrinsic_attention() that allows to visualize the words that have contributed the most to the decision of the classifier. An example below with a legal text of the TCU ![]()
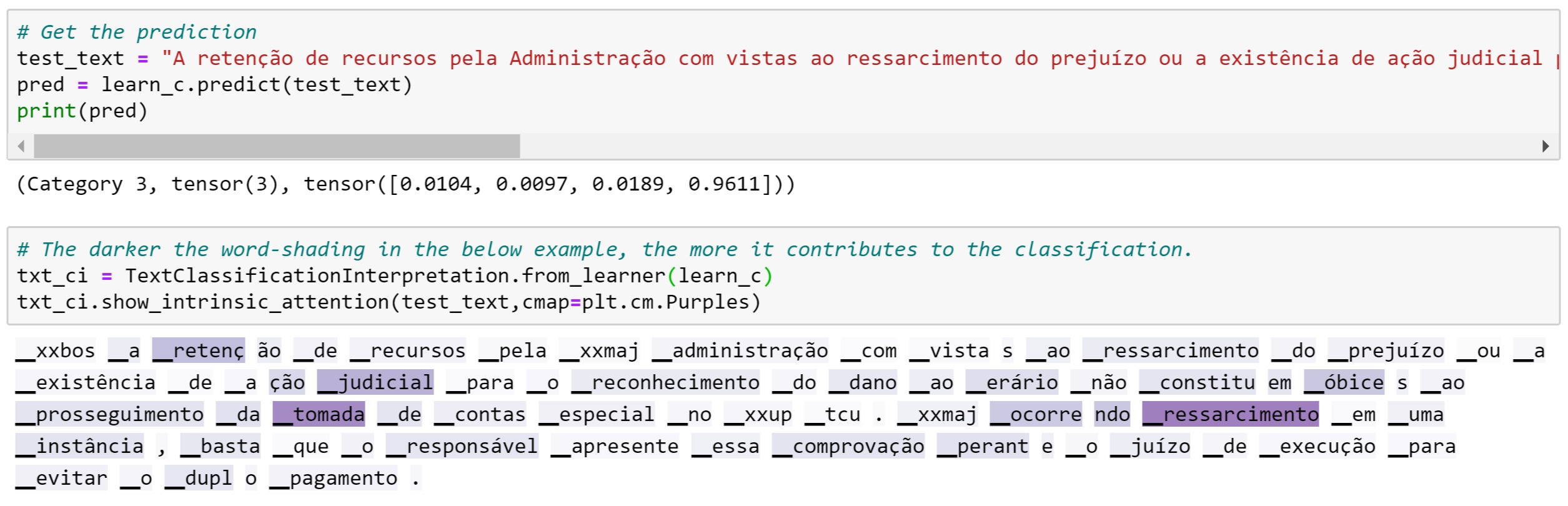
5 Likes
Hi @pierreguillou,
Thanks for your feedback!
In fact, our baseline accuracy was about 97.21%, according to https://github.com/fastai-bsb/nlp-tcu-enunciados/blob/master/1cycle_tcu.ipynb.
I haven’t read about MultiFit yet, thanks for sharing about it!
Monique
Hi @monilouise,
A post to say that I made a correction in the notebook of my TCU classifier and got an accuracy of 97.95% higher than my previous one.
I already updated the post, the notebook lm3-portuguese-classifier-TCU-jurisprudencia.ipynb (nbviewer) and the link to the tgz file in the models directory of my github.
Indeed (thanks to David Vieira), I noticed that the fine-tuning of the LM and classifier did not use the SentencePiece model and vocab trained for the General Portuguese Language Model (lm3-portuguese.ipynb).
For example, the code used to create the fine-tuned Portuguese forward LM was wrong:
`data_lm = (TextList.from_df(df_trn_val, path, cols=reviews,
processor=[OpenFileProcessor(), SPProcessor(max_vocab_sz=15000)])
.split_by_rand_pct(0.1, seed=42)
.label_for_lm()
.databunch(bs=bs, num_workers=1))`
It has been corrected by using the SPProcessor.load() function:
`data_lm = (TextList.from_df(df_trn_val, path, cols=reviews,
processor=SPProcessor.load(dest))
.split_by_rand_pct(0.1, seed=42)
.label_for_lm()
.databunch(bs=bs, num_workers=1))`
Therefore, I retrained the fine-tuned Portuguese forward LM and the classifier on TCU jurisprudência dataset and I got better results! 
-
(fine-tuned) Language Model
- forward : (accuracy) 51.56% instead of 44.66% | (perplexity) 11.38 instead of 15.97
- backward: (accuracy) 52.15% instead of 44.97% | (perplexity) 12.54 instead of 18.73
-
(fine-tuned) Text Classifier
- Accuracy (ensemble) 97.95% instead of 97.39%
- f1 score (ensemble): 0.9795 instead of 0.9737
2 Likes