Hi @jyr1,
So you pretained the model on Amazon reviews. Right?
No, on wikipedia data.
I can’t check your notebook as the github viewer isn’t working but I have a feeling what can be the issue.
Have you finetune the ulmfit on the entire dataset? I think the point with “extreme sample-efficiency” is that you use all your unspervised text that can be very large. And then only use few labeled examples. The reasoning behind this is that the raw text is cheep, labels are expensive.
Has anyone trained a German ULM on TransformerXL?
@sylvain tried to train Transformer XL and then use as LSTM in ULMFiT but I’m not sure if that was working.
1 Like
Hi @jyr1,
I’m currently working with your pretrained weights and it works great!
Thank you very much for your work.
Can you please priovide additional information about the weights?
Why did you “only” choose a vocab-size of 30k?
How many wikipedia articles have you used in total?
And how many words do the articles contain in total?
Best regards
Philipp
I as well trained a German language model with sub-word tokenization. You can download it on GitHub and I also give more background information there: https://github.com/jfilter/ulmfit-for-german
I experimented on 10kGNAD and achieved an accuracy on the validation set (1k samples from the training set) and test set of 91% and 88.3%, respectively. Check out the notebook for the details.
3 Likes
I trained a German Language Model on TransformerXL, just slightly adapting your Spanish LM code, (Thank you for your work and for @kaspar’s hyperparameter experiments !)
-
on a dataset of ≈ 100 million words from German Wikipedia (10% of all articles with > 1000 chrs)
-
with a 60k vocabulary size, mem_len=50 (to increase training speed)
-
reaching a perplexity of best validation loss of 18.9, but:
-
the OOV/out of vocabulary percentage is quite high: 6.5%-6.9% (train and valid set respectively), making the low validation error & perplexity less meaningful (as @piotr.czapla explained further up)
Notebook and link to weights and vocab here.
EDIT: it seems that under fastai 1.0.52 Transformer.py isn’t fully functional - the fastai wizards already repaired the problem, we should either wait for the next fastai release or stay with 1.0.51, if using Transformer, Sylvain Gugger suggests.
2 Likes
Hello, I am trying to clone the multilingual ULMFiT from GitHub in Google Colab. However, I keep running into the error below. I tried the various suggestions on StackExchange to no avail. I’m quite new to fast.ai so I have no idea what’s going on. Any help would be appreciated.
ERROR: Command “python setup.py egg_info” failed with error code 1 in /tmp/pip-req-build-rrjon9hs/
As an alternative: We have just decided to share our German BERT model with the community. It outperforms the multilingual BERT in 4 out of 5 tasks. You can find model and evaluation details here. Hope this helps some of you working on German NLP downstream tasks!
4 Likes
Thank you for sharing this! Reading your blog post re: training another model with more data - Are you considering training a German GPT-2 (345M)? That could take Natural language generation in German (which seems hard/unfeasible with BERT and is generally lagging behind English NLG) to a new level.
Our priority for now is training more BERT models on larger datasets (incl. domain specific ones) and simplify the usage for standard downstream tasks like document classification, NER, QA …
But maybe we afterwards move on to GPT-2 (or whatever NLG model is out there by then).
1 Like
Have you considered getting the model exposed through pytorch.hub either through fastai repo or huggingface?
It would be nice if someone could simply state:
tokenizer = torch.hub.load('huggingface/pytorch-pretrained-BERT', 'bertTokenizer', 'bert-de-deepset-base', do_basic_tokenize=True, do_lower_case=False)
1 Like
From my understanding there is no pretrained german language model for ULMFiT working for the current fastai v1.0.54?
Even @jyr1’s model gives me an error when I try to load it:
weights='30k-pre-ger'
vocs='30k-pre-ger-itos'
learn = language_model_learner(data_lm, AWD_LSTM, pretrained=False, drop_mult=0.5, pretrained_fnames=[weights, vocs])
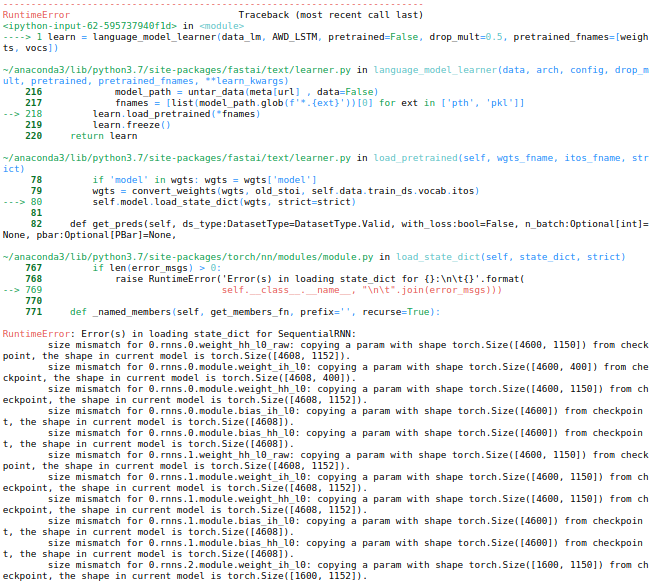
That’s due to all language model shapes being divisible by 8 as of fastai 1.0.53 by default (reason: half precision training is much faster this way). Thankfully, Sylvain Gugger posted a workaround here:
2 Likes
I was completely unaware of that. Will try today, thank you!
Hi
Is there a trained German model in the meantime that can be downloaded somewhere or will the ‘official’ German model come out soon (in the official model zoo)?
Regards, Felix
Hi @felixsmueller. @jyr1 trained a language model a while back that works well for me:
If using a recent fastai version (1.0.53 and later), you will have to read in the weights according to Sylvain Gugger’s workaround (see post a bit further up).
Thanks a lot.
Just some more descriptions for newbies like me:
Download the language model files (from https://drive.google.com/open?id=1gkuY3Tz6LBmcehAnZ95jssV80CBQh7L1) and store them into your Google drive account.
#Then the following code allows to access your Google drive:
from google.colab import drive
drive.mount(’/content/gdrive’, force_remount=True)
root_dir = “/content/gdrive/My Drive/”
base_dir = root_dir + ‘Colab Notebooks/FastAIGermanModel’ #Adapt path
#The following code then reads in the model:
FILE_LM_ENCODER = base_dir + ‘/30k-pre-ger’
FILE_ITOS = base_dir + ‘/30k-pre-ger-itos’
config = awd_lstm_lm_config.copy()
config[‘n_hid’] = 1150
learn = language_model_learner(data_lm, AWD_LSTM, config=config, pretrained_fnames=[FILE_LM_ENCODER, FILE_ITOS], drop_mult=0.3)
1 Like