Looks like this page teasing ULMFiT for seq2seq was added around May 2018. Anyone seen any updates since then? Is this still an area anyone is actively working on?
I’ve been wanting to experiment with using transfer learning for translation. I have a large English language corpus and a large Spanish language corpus covering different information about the same topic. But I have no mapping between the two. I want to translate the English content to Spanish and the Spanish content to English.
I’ve seen a couple of papers from Facebook AI that have had success in unsupervised training of translation models using only monolingual corpora. Eg Cross-lingual Language Model Pretraining and Unsupervised machine translation: A novel approach to provide fast, accurate translations for more languages
I’d like to try what they call “back translation” by combining the pretrained ULMFiT encoder of one language with the pretrained decoder of another in a cycle and sequentially training the encoders and decoders kind of like you do with a GAN generator and discriminator.
Or, alternatively, leaving the encoders and decoders frozen and trying to train a layer in between that translates one encoder’s output to the expected input of the other’s decoder. The intuition being that there should be some mapping between the encoded states of the different languages such that the decoder from the other language can understand it.
Something like this:
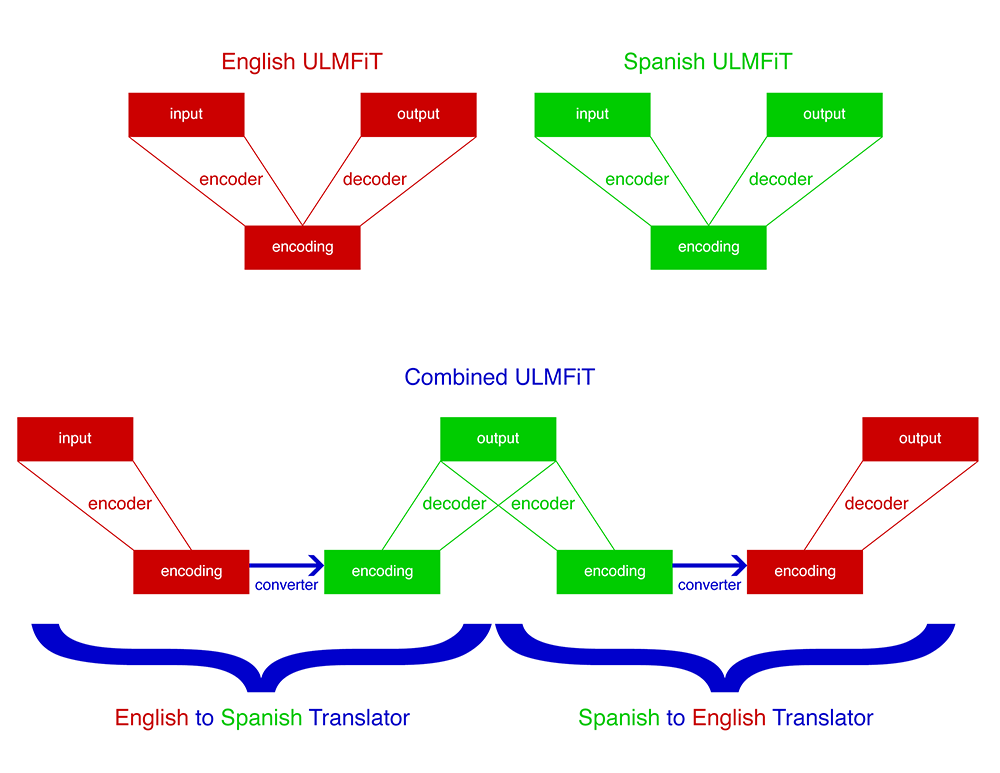
Anyone seen any other papers about similar topics? Or have any thoughts on the strategy?
The three hangups in my mind are that:
- ULMFiT is predicting the next token and the 2 languages may not have a 1 to 1 mapping between tokens so seq2seq would be better.
- Since the pretrained decoder predicts the next word, by the time you cycled back to English you’d be predicting the next word after that (which is your ground truth to compare against) – not sure how much that’d decrease the accuracy.
- Training English->Spanish->English and Spanish->English->Spanish but judging English->English and Spanish->Spanish it might find ways to cheat in training option 1 by not learning the intermediate language state and finding a way to pass data all the way through without the intermediate state being an accurate translation… I think using pretrained language models for each language and and training option 2 of only training an encoding converter while leaving the encoders and decoders frozen would be two potential ways to address this.