best model (Tree-LSTM-NR) accuracy 0.795 - the dataset is most likely broken a bit Paper from contest
New Sentiment dataset like imdb data set
We have approached few companies to publish their data set of comments with ratings we are waiting for their response. It will be published as part of Poleval 2019
Hi Piotr, congratulations on setting SOTA for LM in Polish!
I would love to experiment with the downstream tasks like sentiment analysis using your model.
I wanted to download your pre-trained LM weights but I don’t see them (nor the itos file for mapping dictionaries) under the link you provided. Am I missing something?
Hi AnnaK It seems I’ve forgot to add the link to the pretrained wieghts. Here you have the model that won poleval: https://go.n-waves.com/poleval2018-modelv1.
Do you have some good open dataset that can be used for classification in Polish?
Thanks for the link! Correct me if I’m wrong, but in order to use it wouldn’t I also need your word-to-token mapping (in imdb that was the itos_wt103.pkl file)?
Unfortunately I couldn’t find any good datasets, so I think I’ll collect the data myself from some websites with reviews.
Hi Anna,
our language model uses a subword tokenization to deal with rich morphology of Polish language and a large number of unique tokens in PolEval’s dataset (the competition required to distinguish over 1M of tokens). For tokenization we used sentencepiece (here’s our implementation https://github.com/n-waves/fastai/tree/poleval/task3), so instead of itos*.pkl file we provided sp.vocab and sp.model files which contain trained sentencepiece model.
How did you decide on vocab_size using sentencepiece? I am using BPE model type. And did you use any pre or post rules from fastai spacy pipeline? Thanks
From NMT forums:
100000 and 300000 parameters are far too big - the usual values are between 16-30K. With such parameter, you simply disable BPE effect.
We selected hyperparameters based on results from grid search on smaller corpus.
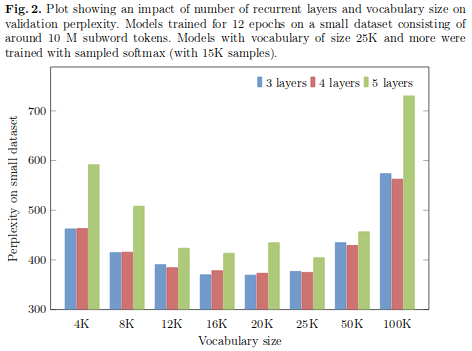
You can find more details in this paper. Bear in mind that lower perplexity does not imply better performance on downstream tasks.
The PolEval 2018 corpus was already pretokenized. From our experiments with hate speech detection in Polish tweets we noticed that default fast.ai transforms are sufficient.
Maybe I am missing an important point here but still wanted to make sure if this makes sense …
As we change our LM’s vocab/tokens with either vocab size or say with different tokenization methods (BPE, uni, etc) we also change the label representation of the test sets (e.g. next token to predict might be different with different vocabs for the same exact test sentence).
So, is it fair to make such comparison between methods when what we test is no longer identical? Is this a valid point to make? Or in overall it doesn’t matter?
Or, is this what your are referring to when you say we should compare these LM models with downstream tasks?
Then, non of the LM papers out there can be solely trusted based on just perplexity, unless same exact preprocessing is done and same tokens are used…
Hello, my first post here o/ ! I think you are exactly right as the perplexity is a function of the vocabulary (your LM is basically a probabilistic model on top of the vocabulary you have chosen). Thus it’s not “fair” to compare the numbers if the vocabularies are different. Of course one can probably get some intuition of the ballpark of the models (is the perplexity like 20 or 200), if it is reasonable to assume that the vocabularies are not super different.
Testing classification performance or some other downstream task is a better test in a sense, but maybe it could be that a language model can be “good” without being good for a specific task?
@piotr.czapla@mkardas Thanks for leading this, it’s really helpful to have the code available that can produce SOTA results in Polish. I’m just starting out with fastai/ULMFiT and prepared a Google Colab version of your approach, with a toy dataset, just to test if the pipeline works. I’d appreciate any feedback on the code: https://colab.research.google.com/drive/1n3QQcagr9QjZogae6u5G41RxI4l5Mk9g
It was book corpus and they haven’t come back to me after law checkup so I guess they lost interest, I’ve put a reminder to see if we can get the corpus or not. But since poleval2019 we have at least hate speech in polish to classify so sentiment isn’t that tempting anymore.
The point is more that the downstream task performance does not depend on perplexity. Perplexity is good measure of the performance of the language model ability to predict next tokens and to generate text. It does not tell you much how good that particular LM is going to be on down stream classification task.
Exactly, the LM’s with sentencepiece that we trained for recent poleval weren’t too good at generating language but performed very well when used as a base for a ulmfit classifier.
Interesting dataset you have, is it publicly available, it would be nice to see how good ULMFiT can get on such dataset.
The things I’ve noticed is that you aren’t doing any pretraining on unabeled data which should significantly help your classifier to accumulate knowledge that might note be easy to extract just from two books. I would at least start with wikipedia pretrained model, but in your case where you try to detect dialog vs narrator it would be good to add some dialog samples like reddit, I can send you the one we collected for poleval 2019.
But maybe you could simply use other books preferably from the same time and genre? https://wolnelektury.pl, some of the books are already in text format https://wolnelektury.pl/media/book/txt/poglady-ksiedza-hieronima-coignarda.txt.
Another important note is how you split the text for the language model you should make sure you include longer paragraphs of text as one item, so that they are feed to LM in order. In your case it seems you feed it with sentences which might make it harder for ULMFiT to see the changes in between narrator and dialog, as detecting this is not that beneficial as in case of longer paragraphs.
Thanks for the explanation Piotr, really enjoyed reading the paper earlier! I was actually trying to emphasize that comparing LM perplexity performances of differently tokenized datasets are like comparing apples and oranges. For example, if we change a parameter in sentencepiece and compare two LM model’s perplexity then it wouldn’t be a valid comparison. You stated that the end goal is downstream performance and I agree on that with you. I was only referring to the graph shared in this post (FIG 2).
After doing a little thought experiment before sharing what I had earlier I realized it wouldn’t be surprising to see naturally lower perplexities as # of tokens decrease. At extreme, say we have 2 tokens in our vocab. Probability of predicting next token for a randomly initialized model would be ~50%. (aka. less entropy to begin with)
Quoting someone down (this also make more sense to me for describing perplexity):
First of all, perplexity has nothing to do with characterizing how often you guess something right. It has more to do with characterizing the complexity of a stochastic sequence.
Just sharing my thoughts
PS. I also read a paper from CMU regarding different LM metric proposals for a more rigorous comparison, not seem to find it now but will definitely share once I do.
You are absolutely right you cannot compare the perplexity between arbitrary datasets or tokenisations. However you can make the perplexity comparable if your tokenisation is reversible (you can get original text out of it) and you normalize the neg log loss by fixed number (we used the number of words in polish corpus, not the number of subwords that was changing).
In case of your thought experiment if you have 2 tokens you can’t recreate the original text, so the perplexity would not be comparable in that case. We made sure that we were including the full set of characters from the corpus so you can compare the values in Fig2. It is a bit similar to the way OpenAI evaluated GPT-2 on the WIkiText-103. The GPT2 has different tokenisation mechanism (BPE on bytes), and it was trained on normal text documents while WikiText-103 is normalized by Moses so the had to undo the normalisation, and then do the tokenisation on byte level, but they could still compare the perplexity numbers with word level models because they were normalizing the perplexity by the number of words in the original corpus not by the nubmer of subword tokens.
 …
…