I’ve been trying to create a databunch from my personal Gait dataset. The output classification I am looking to predict is the last column named ‘label’, seen below:
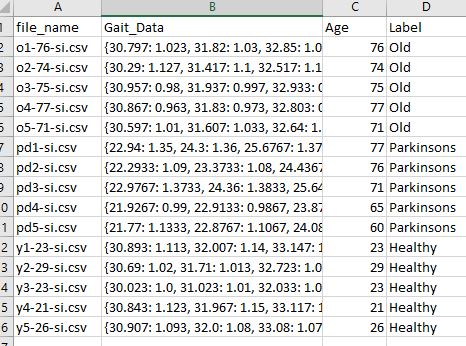
Each subject in the dataset is either healthy, old, or has Parkinson’s disease.
This is the code I’ve been using to try provide these labels
MixedGaitList.from_df(joined_df, cat_cols, cont_cols, txt_cols, vocab=None, procs=procs, path=PATH)
.split_by_rand_pct(valid_pct=0.1)
.label_from_df() #cols=dep_var, label_cls=MultiCategoryList) #.get_label_cls(labels=labels) #.label_from_df(dep_var)
.transform(tfm_y=True)
#Data augmentation? -> Standard transforms; also transform the label images
.databunch(bs=8,collate_fn=collate_fn, no_check=False)
This worked for test datasets I’ve thrown through it, the only difference is that the dependant variable is text instead of numerical, any ideas what I am doing wrong?
Version
=== Software ===
python : 3.6.7
fastai : 1.0.52
fastprogress : 0.1.21
torch : 1.1.0
nvidia driver : 410.79
torch cuda : 10.0.130 / is available
torch cudnn : 7501 / is enabled
=== Hardware ===
nvidia gpus : 1
torch devices : 1
- gpu0 : 15079MB | Tesla T4
=== Environment ===
platform : Linux-4.14.79+-x86_64-with-Ubuntu-18.04-bionic
distro : #1 SMP Wed Dec 19 21:19:13 PST 2018
conda env : Unknown
python : /usr/bin/python3
sys.path :
/env/python
/usr/lib/python36.zip
/usr/lib/python3.6
/usr/lib/python3.6/lib-dynload
/usr/local/lib/python3.6/dist-packages
/usr/lib/python3/dist-packages
/usr/local/lib/python3.6/dist-packages/IPython/extensions
/root/.ipython