I am training a model for multilabel classification. My last epoch for learn.fit_one_cycle gives me a validation accuracy_multi of 91.4%. However, when I tried to use TTA, it gives me just 27% accuracy. Am I doing something wrong for TTA?
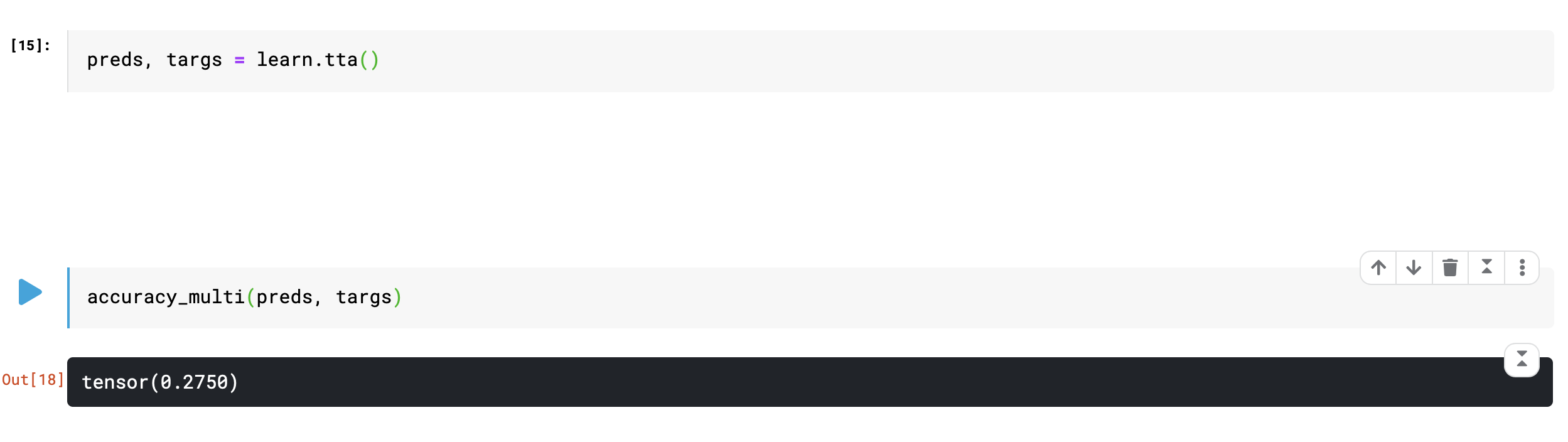
I think preds coming out of learn.tta() are probabilities (or just activations depending if sigmoid is invoked or not).
accuracy_multi seems to expect predictions (e.g. 1s and 0s after having applied a specific threshold to preds).
See here.
x = torch.randn(4,5)
y = (torch.sigmoid(x) >= 0.5).byte()
test_eq(accuracy_multi(x,y), 1)
Have you checked the contents of targs and preds?
Hey, thank you for the response. No I haven’t checked the contents of preds, targs. I shall do that. However, I did see the definition of accuracy_multi

and it does convert the activations to predictions before comparing. I will check the preds returned by learn.tta() though because sigmoid might be getting applied twice on them.
Good catch! Keep me posted!
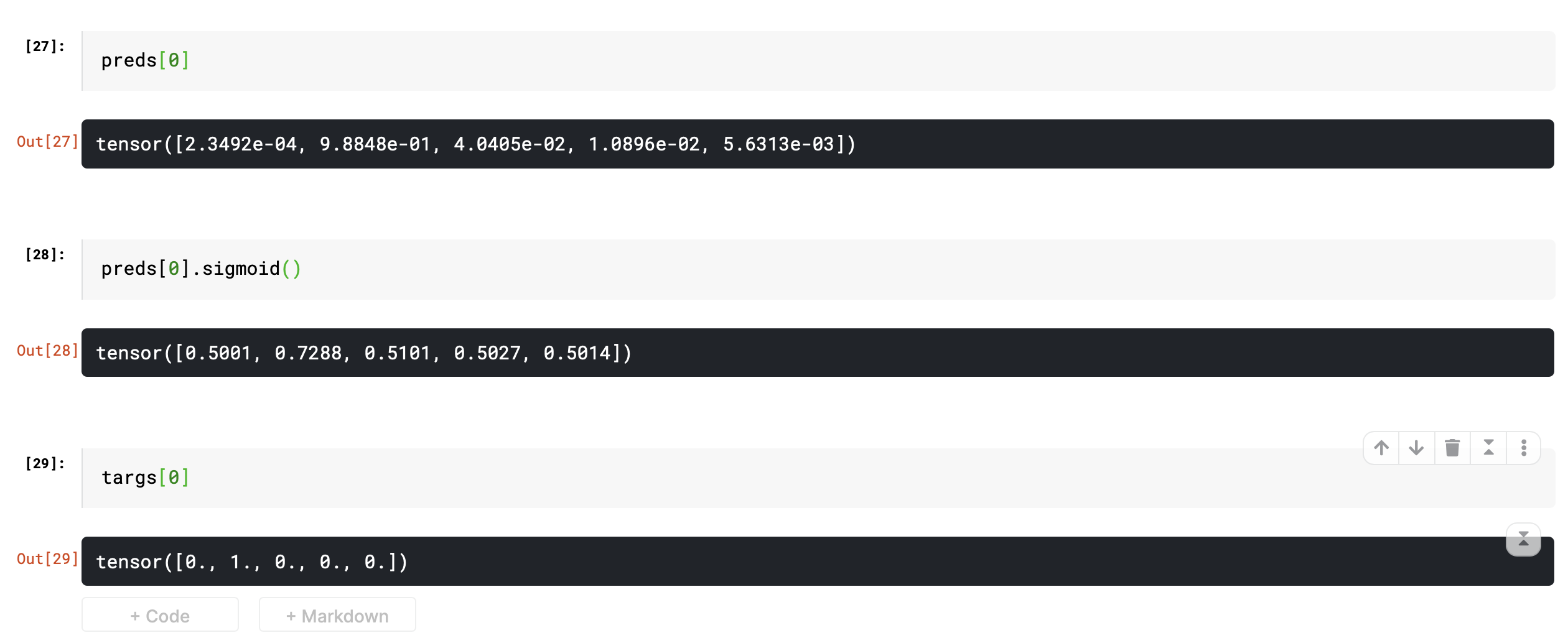
I checked the preds and targs and sigmoid wasn’t getting applied twice. I don’t understand the low accuracy. Do you think my model is corrupted? I had trained it earlier and now I’m loading it.
1 Like
Have you tried running TTA line by line to get the different preds and checking them yourself? As it’s about 5 different predictions that are used during it, you can check each one and see what’s acting up. Plus one is always just straight up a learn.get_preds() without the TTA, I’d start my debug there 
Edit: the only other thing I can think of is make sure your threshold is the same for when you calculate it
1 Like
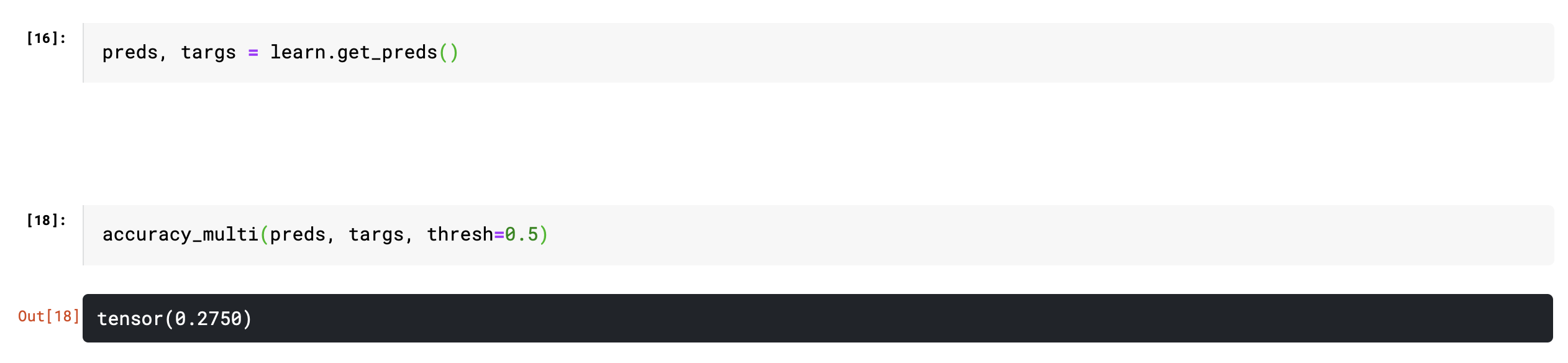
Hey @muellerzr, Thank you for the response. How do you run tta line by line? I had checked if learn.get_preds() is working as expected however I did not try to pass it through accuracy_multi. And when I did now, I see the same low accuracy. I’ve made sure the threshold is the same.
Something is up with my model. Is learn.export generally better than learn.save? I had trained this model in some other notebook, saved, downloaded and uploaded to use in a new one. Any of this can corrupt the model?
Just check the TTA source code and run it manually there should be a for loop that gets the predictions, just keep a second array that keeps the raw ones for you to look at.
What does learn.validate() get you? So learn.validate() and learn.get_preds() and checking it are different? If so, it’s not the model
Okay I will try running tta line by line. I just tried learn.validate() and it gives me 0.20 and 0.91 which is something called final_record. Is it the validation and train accuracies? I will try to dig deeper into this.
The first is your loss, the second would be your metric on the validation set
Hmm, so learn.validate is working properly. I’m confused now. I’ll check this tonight
@muellerzr
You know fastai from end to end always thanks for answering all the queries. Here are some more
-
Below is code snipped from learner.tta. I am trying to find where is fastai adding the augmentations of Train ,i checked the code self.get_preds couldnt find a place .
try:
self(_before_epoch)
with dl.dataset.set_split_idx(0), self.no_mbar():
if hasattr(self,‘progress’): self.progress.mbar = master_bar(list(range(n)))
aug_preds = []
for i in self.progress.mbar if hasattr(self,‘progress’) else range(n):
self.epoch = i #To keep track of progress on mbar since the progress callback will use self.epoch
aug_preds.append(self.get_preds(dl=dl, inner=True)[0][None]) -
If i want to model fold ensembling , only way i figure out is to run tta for each model fold,but then it might time consuming process to do this way, one may want to run same aug across all model folds and mean that prediction. Is there any better and optimized way?