Thanks for the replies and appreciate it’s full steam ahead on the dev build. However I’m more than a little confused as to what learn.TTA() is returning (I’ve browsed the forums but am no clearer). For example, when I get an array tta_preds with dims [5, 400, 128,128] back I understand I have 5 predictions for 400 images.
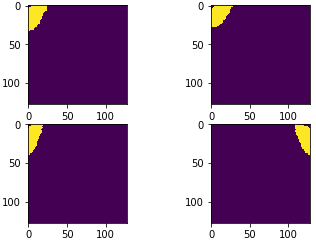
However for each transform returned I’m struggling to decipher what TTA was applied. For what it’s worth, if I could identify the lr flip one that would be great. Annoyingly, (unless I’m an idiot, which cannot be ruled out) this doesn’t seem as simple as plotting. Often within the same TTA transform some images are flipped and some are not.
This seems odd, I was expecting/hoping that, say, in the return from learn.TTA() [1, :, :, :] would correspond to lr flips all the time.
I hope this makes sense and apologies in advance if I’ve missed something really obvious.
Mark
All the same way:
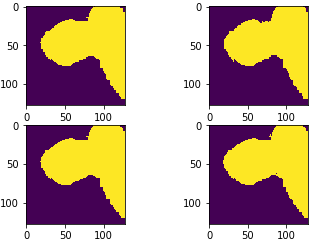
Some flipped: