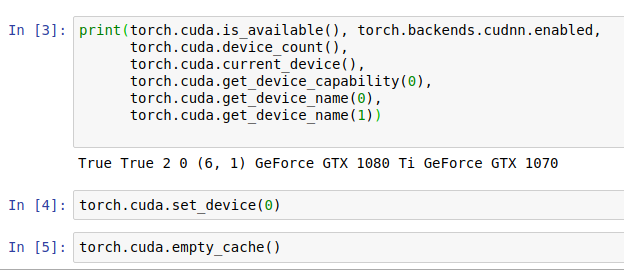
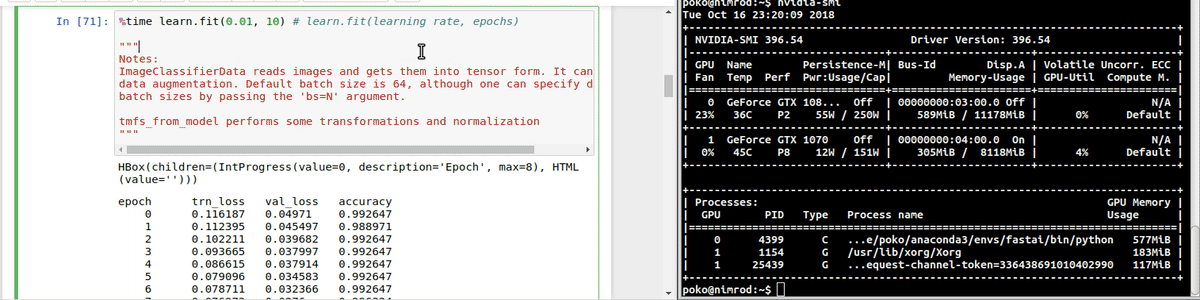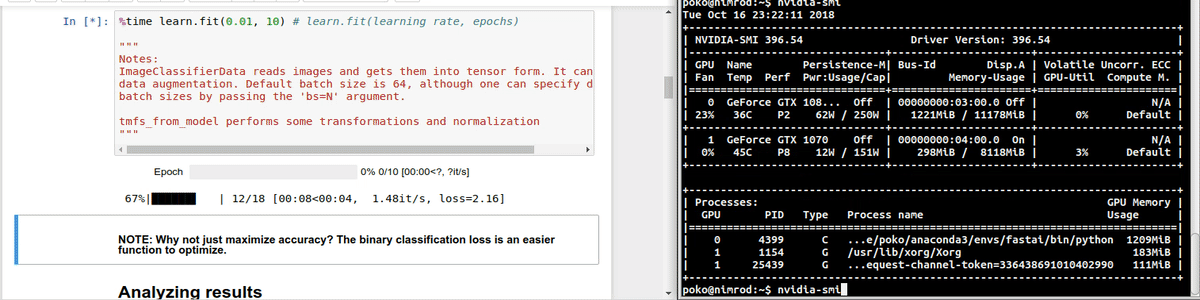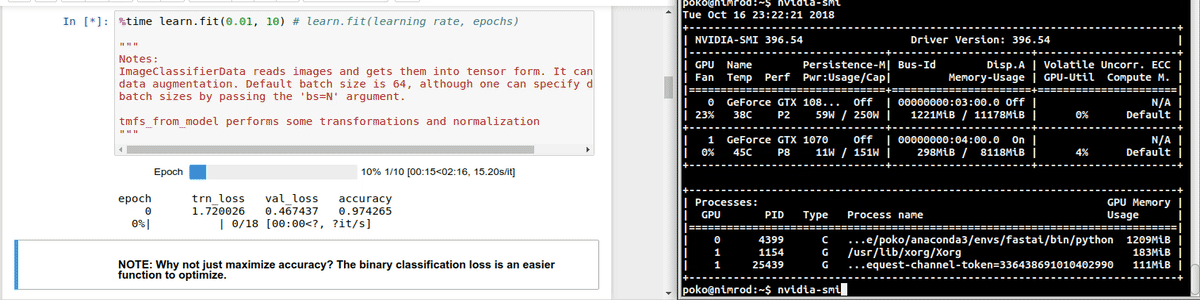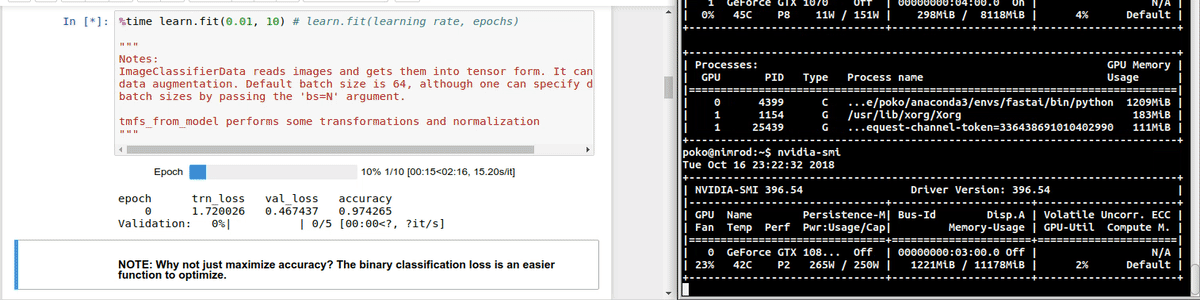
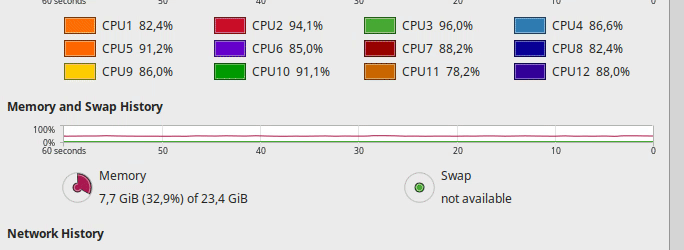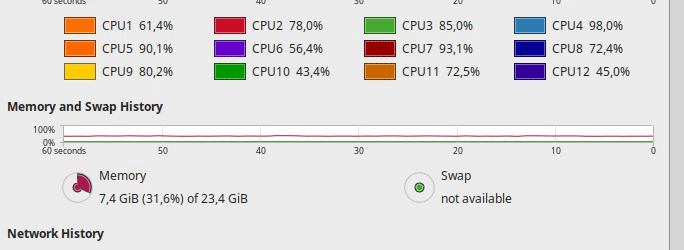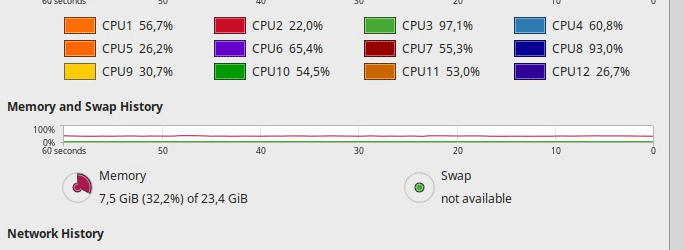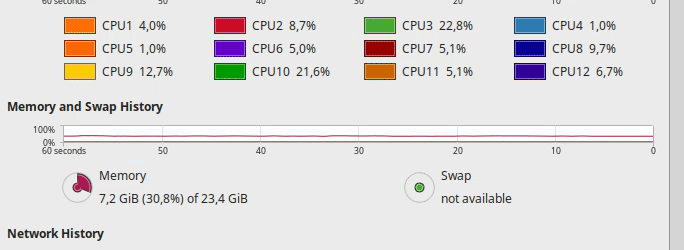
Hi. I’m having issues with my hardware, in the sense that the GPUs seem to be not properly fed by the rest of my hardware pipeline.
The machine in question is a Xeon 2630v2, 24Gb RAM, 500Gb NVMe drive, one 1080ti and one 1070.
Look at what happens:
The following are screencasts of the training process alongside continuous updates of nvidia-smi. Below, you can see the load over the CPU during the same process. Please note GPU-util column for GPU0: It idles for most of the time, and occasionally peaks at low percentages
[NOTE: right-click the animated GIF and select “open in a new tab”, otherwise it’s barely readable]
As you may see, the CPU is not fully loaded, so I don’t think it’s the bottleneck. Check. There is plenty of free memory. Check. And I cannot believe that a NVMe drive cannot properly feed a GPU. Check. Same story with the 1070.
Ok, so are you working with fast.ai library or a custom code in pure pytorch ?
That’s not clear to me.
Also depending from the version of pytorch are you using , this method bellow is discouraged in favor of device
torch.cuda.set_device(0)
example of device
device = ("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
Btw , you could clearly isolate each GPU using containers and creating the same environment in both of them and pointing to the same shared folder of your project
I am working in fastai 0.7 as of yet (watch the video, it will be clear from context).
All the rest of your answer contains useful information, but please note that I don’t care about multiple GPUs. I just want one GPU to be properly used. Pretend my system just has one GPU.
Better to leave out containers and similar stuff for now, and concentrate about isolating the problem. We have the GPU idling during training, and no apparent bottlenecks in CPU/ram/hard drive. Something else is going awry, but I’ve been unable to figure it out.
Leaving out the context of Multi-GPUs, and also the containers and focusing on the claim that your GPU is not filling the memory as you like
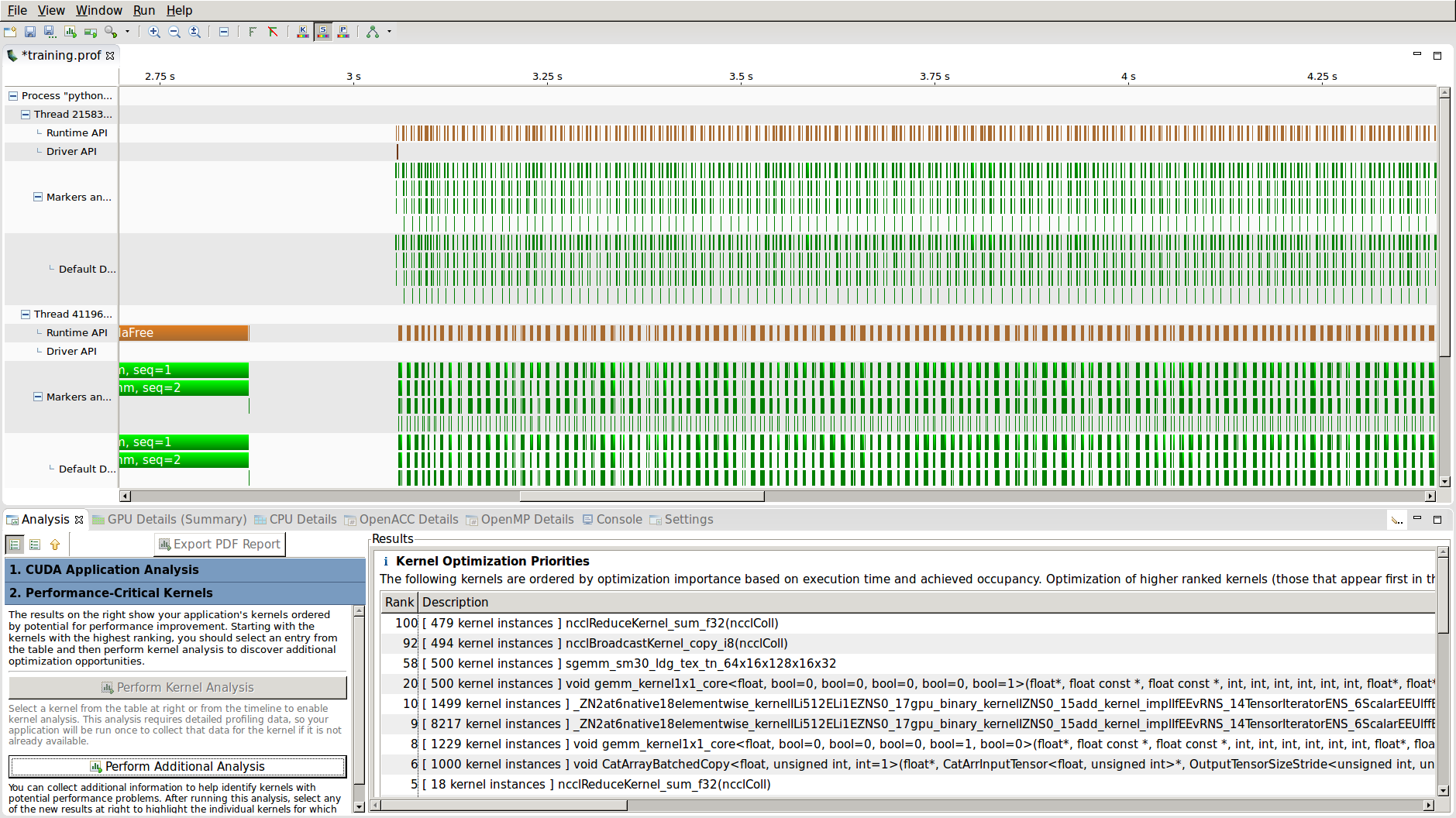
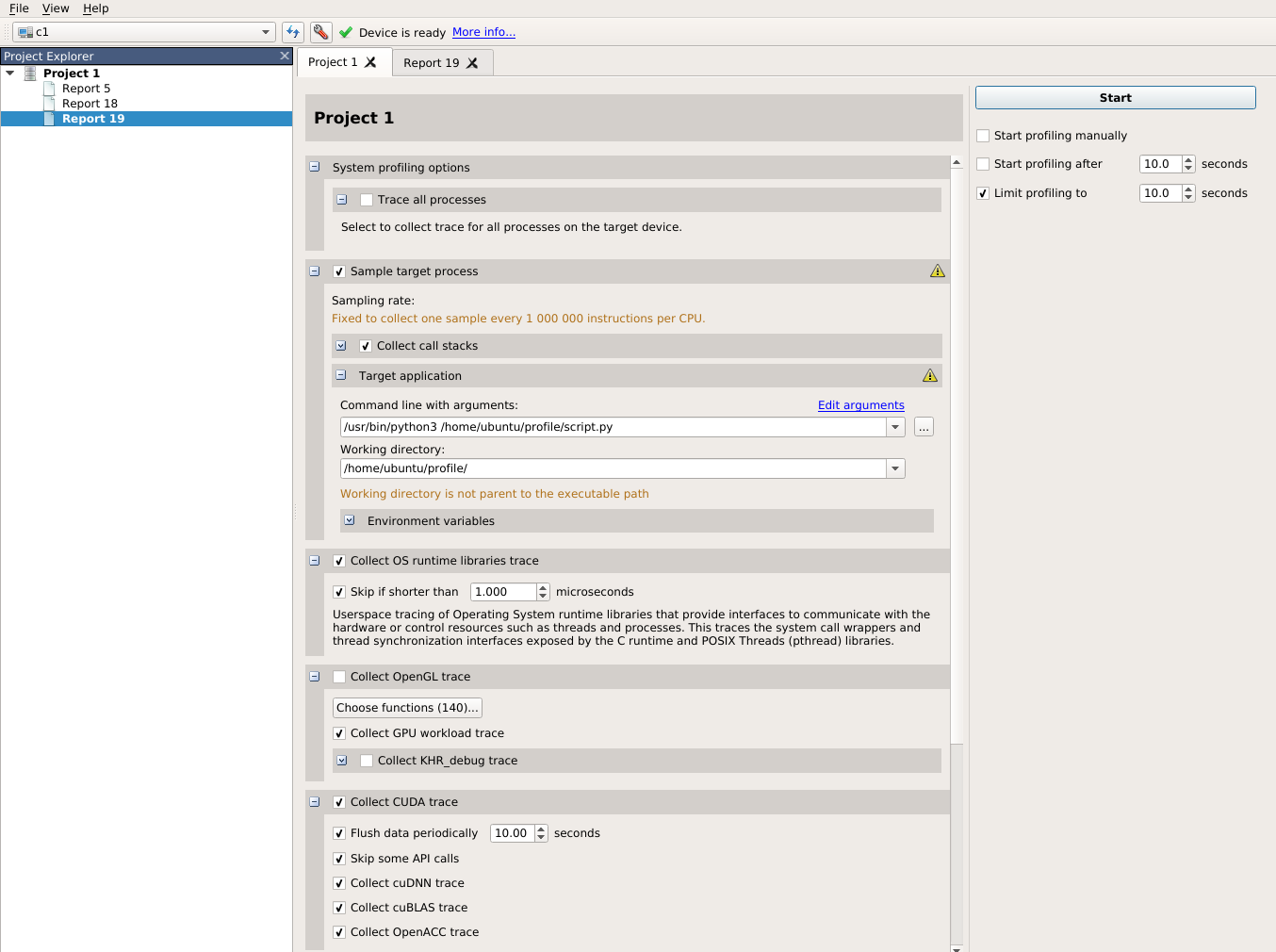
Have you tried to use some of this tools to prove it ?
Because watch nvidia System Management Interface, its not the same as Profiling Tools
My problem is that even a single GPU is not properly exploited .
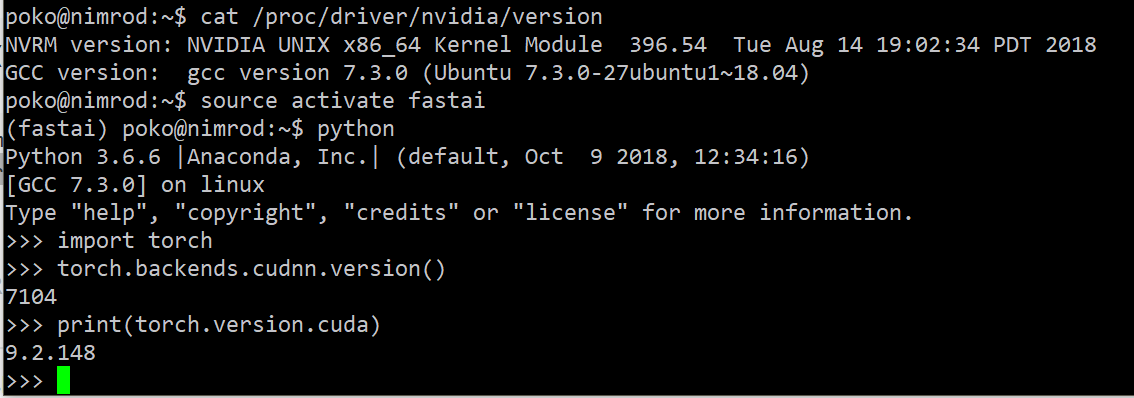
Also what version of driver, cuda and cudnn are you using ? There is a bunch of specifications you just leaved out from your first question. How can anybody predict whats your problem based an animated gif ?
It could be you’re just not pushing the GPU enough. It looks like you’re only using about 1.2 GB of memory on the GPU. I don’t know what your learner is but if layers are frozen that takes a huge load off the GPU. I would try upping the batch size to a point where most of the GPU memory is used and (if applicable) unfreezing the model to see if that increases GPU usage.
The issue is not just about memory. In that video you can appreciate the GPU utilization oscillates between 0% and 40% even as we fit the model with precompute=False.
Furthermore, I think that these profiling tools are intended for people who want to write cuda C code, but correct me if I make mistakes here.
You are absolutely right, I should have provided these informations from the beginning. The screenshot below rectifies this:
Thank you. Indeed, just the two trailing fully convolutional were involved in the training process. But it seems awkward nonetheless that the GPU is not fully leveraged for training such layers as quickly as possible.
I was a bit worried since this is a freshly assembled machine. Let’s try and train the whole network. But just for the sake of curiosity, you guys could experiment with a frozen network, and see what nvidia-smi reports about gpu utilization.
Hi again @balnazzar,
Some of this tools can be used to profile your memory CPU and GPU, I just does not have the code in hand for you, but you can find out there if you will. Also apparently is nothing wrong with the drivers and versions you have, at least what I should know about it.
I understand you want that 99.99% of your CPU and GPU be filled by the computation you need, but before this kind of thing can happen Nvidia has a lot of work to do for CUTLASS package is still in its infancy while this same kind of packages for CPU already exists. Other package I know about could be used to get better performance is MAGMA but Pytorch does not use it
So for now each neural network computation and space in memory is limited by the NN architecture and the batch training size. If you send a batch with lower volume of data will compute. If you send a batch volume with 1 bit over it will just throw a Cuda Error: Out Of Memoryof Hell! because you just have to start everything again, unless you have some snapshots of your training. (I don’t even know if fast.ai have this implemented or if it will implement in the future).
I tested both my GPUs with the network unfrozen, and the occupation reached almost 100% with peaks of power draw well over the nominal TDP.
I ran the same notebook on a much more powerful machine with Volta GPUs, and it showed the same behaviour: very low occupation while training the FC layers with all the rest frozen.
If you want a brief benchmark, the 1080ti completed those 10 epochs in 2min 22s, while Volta did it in 1min 51s (both in FP32).
I also bothered you all for nothing, but let’s hope this thread will be useful to other people incurring in the same doubts. Thanks!
PyTorch uses a caching memory allocator to speed up memory allocations. This allows fast memory deallocation without device synchronizations. However, the unused memory managed by the allocator will still show as if used innvidia-smi .
Analysis Tools
To be able to do that you need to save the jupyter script into a python script so the profile can identify you GPU correctly
Nvidia Profiler
nvprof --profile-from-start off -o training.prof -f -- python3 script.py
Ok mates, I solved my problem in the most brutal way: formatted & reinstalled everything from scratch. It worked.
Read it as “I don’t know where the blame should be put upon, but fastai library was blameless”. Still a process in R state which ignores sigkills remains a wonder for me.
Wow man, that’s sucks… but I am glad you did.
If you like the idea use Containers, because its ephemeral and you almost never will have to touch your host.