I’ve successfully fine tuned ResNet models using fastai. I read Jeremy Howard’s post on timm models with excitement, and had success doing fine tuning on ConvNext models. However, when I try the Levit family of models, I hit a wall. Here’s my code for creating a binary classifier:
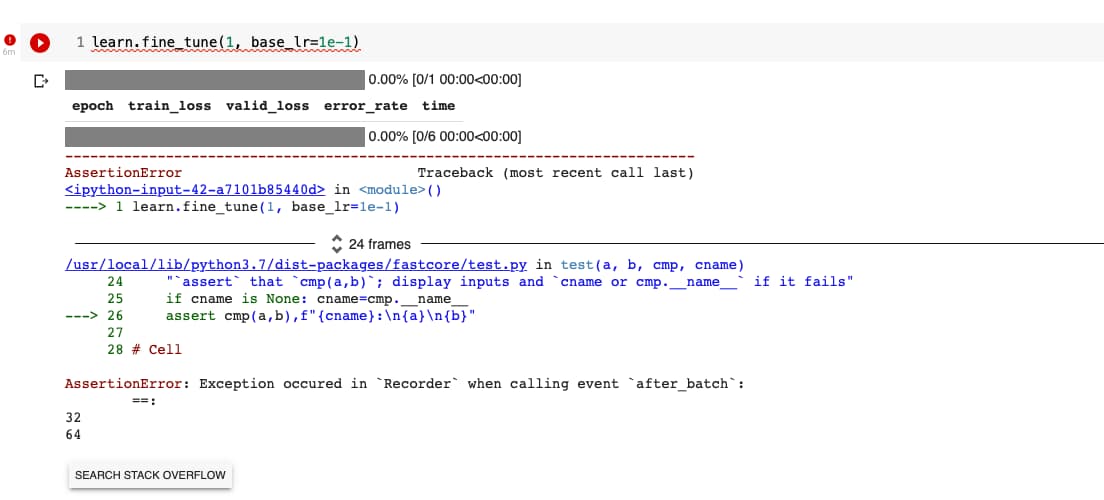
The lr_find() command errors, and after 18 frames of tracing I get this error:
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/batchnorm.py in _check_input_dim(self, input)
295
296 def _check_input_dim(self, input):
→ 297 if input.dim() != 2 and input.dim() != 3:
298 raise ValueError(
299 “expected 2D or 3D input (got {}D input)”.format(input.dim())
AttributeError: ‘tuple’ object has no attribute ‘dim’
From my research, it looks like maybe I need to change my loss function to one that is compatible with levit? If that’s correct, I have no notion of how to do that successfully.
@kwame1, this seems like a different issue. May I ask that you start a separate topic on it? Also, I would recommend you provide the specific model you have specified, along with the vision_learner() call that instantiated it.
class Levit(nn.Module):
""" Vision Transformer with support for patch or hybrid CNN input stage
NOTE: distillation is defaulted to True since pretrained weights use it, will cause problems
w/ train scripts that don't take tuple outputs,
"""
this might yield the problem you encountered.
Did you test it in plain torch already and encountered the problem there too?
Thank you @zonkyo ! I’m afraid that my “plain torch” skills are very limited–I’m a self-taught coder using FastAI as the “training wheels” version of PyTorch. Any links/pointers you can provide that can help clarify how to do the test you’re suggesting?
In my first comment I posted a github link. If you use the main.py from Facebook as a starter, there are enoguh basic argument to understand how to use it; from there, you can start changing parameters to use your own datasets and so on.
As I said, I just had a look there. If you want to transform it to be useable by fastai, I think one has to change parts of the forward method(s).
The issue is that LeVIT return two outputs: one for supervised learning and one for distillation. I just skimmed the paper yesterday but from what I understand the distillation is trained to give similar output as a certain resnet variant. I “solved” the issue by creating a model around LeVit that only uses the first output
class MyNet(nn.Module):
def __init__(self,arch,n_features=512,n_classes=10):
super(MyNet, self).__init__()
self.features = arch
self.clf = nn.Linear(n_features, n_classes)
def forward(self, inp):
x = self.features(inp)
if type(x) is tuple:
x = x[0]
return self.clf(x)
m = timm.create_model('levit_256', pretrained=True,num_classes=0).cuda()
model = MyNet(m).cuda()
# create your learner
learn = Learner(data, model,loss_func=LabelSmoothingCrossEntropyFlat(reduction='sum'),
opt_func=ranger,cbs=GradientAccumulation())
I also recommend reading the paper. I found it well written and it’s also not too long
EDIT: Actually, taking the mean of both outputs instead of just the first one might be the better solutions since that’s what’s done during inference: instead of
if type(x) is tuple:
x = x[0]
use
if type(x) is tuple:
x = .5*(x[0]+x[1])
Also you might wonder why we need the if-statement. During validation the model switches to just one output. Without asking if the output is a tuple we’d get an error message (or worse, some wrong numbers for our metrics)
/usr/local/lib/python3.7/dist-packages/torch/_tensor.py in torch_function(cls, func, types, args, kwargs)
1140
1141 with _C.DisableTorchFunction():
→ 1142 ret = func(*args, **kwargs)
1143 if func in get_default_nowrap_functions():
1144 return ret
RuntimeError: mat1 and mat2 shapes cannot be multiplied (64x768 and 512x10)
Part of the traceroute is pulling in your code:
in forward(self, inp)
10 if type(x) is tuple:
11 x = .5*(x[0]+x[1])
—> 12 return self.clf(x)
13
14 m = timm.create_model(‘levit_384’, pretrained=True,num_classes=0).cuda()
I tried running it with both modifications of your “if type(x) is tuple” code, but that did not affect this error.
Sorry for just dumping this out. I wish I was a better coder so I could fix it myself! I will, however, do as you suggest and research the LeVIT paper.
Without having looked it up, I think levit_384 probably has more features than levit_256 in the last layer. When you create the model you have to take this into account. also from the error message I conclude that you have 64 classes (I have 10 in my example):
model = MyNet(m,n_features=768,n_classes=64).cuda()
Also for finetuning with freezing to work, the model has to be split accordingly. Right now I cannot test the code but if I remember correctly it’s something like this (before starting to train the model):
learn.split([model.features,model.clf])
And a bit of advice at the end: Don’t shy away from reading the code and trying to understand what everything does. I know it’s kind of intimidating at first but it’s time well spent. For your question, the initial part of MyNet was important:
class MyNet(nn.Module):
def __init__(self,arch,n_features=512,n_classes=10):
The init() function takes 4 arguments: self, arch, n_features and n_classes. Let’s ignore self for now.
arch: that’s the input model
n_features: that’s the number of features in the last layer of the input model. Instead of giving this info manually, we could probably also infer it directly from the model, but I was too lazy
n_classes: the number of classes we want to predict. Again, you can probably also just infer this from your dataloader via: dls.c, but I was lazy
Sorry I haven’t responded earlier, been busy with lots of stuff.
Ross refactored the LeViT as couple months back so this isn’t an issue.
You need to either install the pre-release version pip install timm==0.6.2dev0 or install from master pip install git+https://github.com/rwightman/pytorch-image-models.git
I personally always use timm from master since timm is always cutting edge and new models and features are being incorporated quickly, so this gives me access to that. That’s what I always recommend.
I am still facing same issue (RuntimeError: The size of tensor a (225) must match the size of tensor b (196) at non-singleton dimension 3) even after installing timm from master pip install git+https://github.com/rwightman/pytorch-image-models.git
If you have a Colab link or some minimal reproducible example, I can try to investigate further…
I cannot reproduce it on my end so I don’t how much I can help…