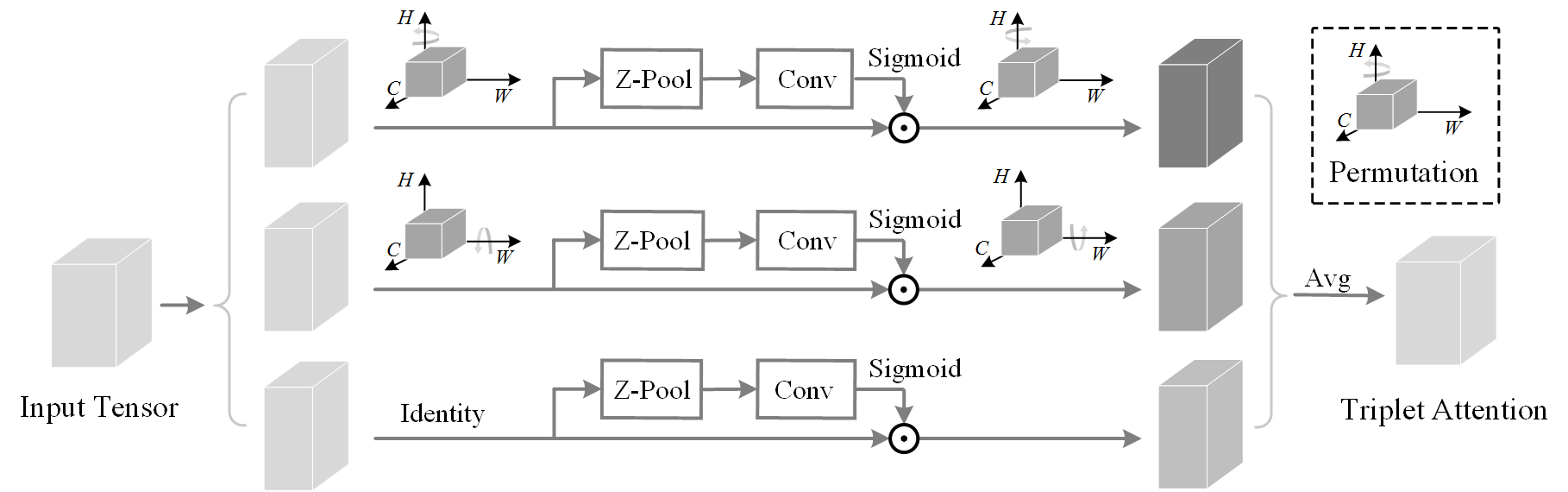
The preprint for our paper " Rotate to Attend: Convolutional Triplet Attention Module" is now out on arXiv (link). This was in collaboration with Trikay Nalamada (IIT-Guwahati), @iyaja (University of Illinois, Urbana Champaign) and Qibin Hou (National University of Singapore). We have open sourced the code on Github (link to our repository).
If you’re into attention mechanisms in computer vision and heard about squeeze-and-excitation networks and their contribution in Efficient Networks then you might be interested in giving our paper a read and trying Triplet Attention in your models.
We find that Triplet is able to retain more long range dependencies because of introducing cross dimensional interaction which we validate from the GradCAM/ GradCAM ++ maps as shown below:

16 Likes
Update: Our paper is accepted to WACV 2021.
4 Likes
Update - Here’s our updated paper - https://arxiv.org/abs/2010.03045 which was accepted to WACV 2021. As an author we would encourage everyone to provide any valuable feedback regarding our work and give it a try for your architectures for different tasks.
3 Likes
CVF Paper page + Supp Material along with Underline Video presentation. It will be soon out on YouTube. Will also integrate WandB and write a report on the same.
2 Likes
Here is our Youtube video for the paper - https://www.youtube.com/watch?v=t6qJTJXBHq8&feature=youtu.be
2 Likes